Title: Accelerating Model Training in Multi-cluster Environments with Consumer-grade GPUs
Authors: Hwijoon Lim(KAIST), Juncheol Ye, Sangeetha Abdu Jyothi, Dongsu Han
Scribe Mengrui Zhang(Xiamen University)
Introduction: Training large machine learning models requires substantial computing resources and memory. Thus, large tech companies use massive GPU clusters to train large models. However, academic environments often have budget constraints that force reliance on consumer-grade GPUs and slower inter-node connections, which are cost-effective but face limitations in network bandwidth compared to data center GPUs. This disparity makes it crucial to optimize distributed training processes to prevent bottlenecks caused by insufficient bandwidth. However, the existing techniques used to reduce communication overhead between GPUs bring additional computational overhead. This leads to a tradeoff between network load reduction and computational overhead. This paper addresses the inefficiency in training machine learning models using consumer-grade GPUs in multi-cluster environments with limited network bandwidth.
Key Idea and Contribution: The authors developed StellaTrain, a system designed to optimize model training in multi-cluster settings by leveraging consumer-grade GPUs and addressing bandwidth limitations. StellaTrain employs several innovative techniques, including gradient compression and a hybrid approach that uses both GPUs and CPUs for different tasks to maximize efficiency. One key strategy involves pipelining the training process to ensure GPUs are not idle, thus improving iteration speed. Another important contribution is the development of a cache-aware sparse optimizer that significantly reduces computational overhead by improving cache utilization during gradient compression and optimization.
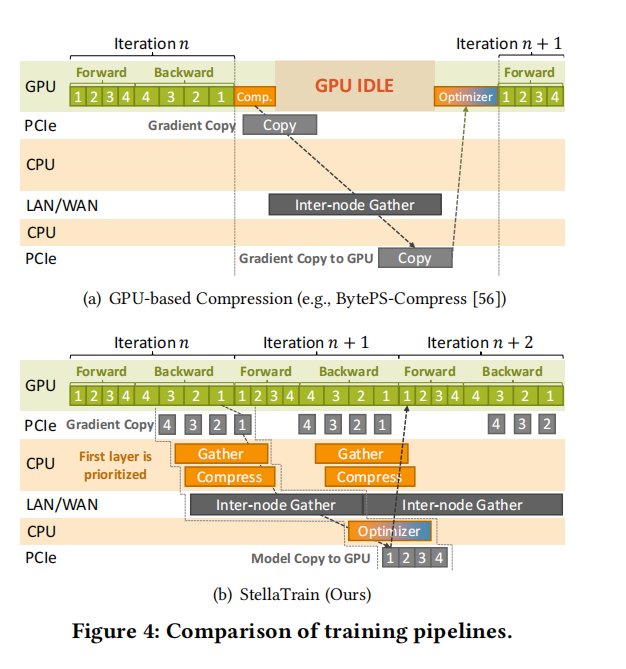
Evaluation:
- Multi-cluster Scenario: In a multi-cluster scenario with an average fluctuating link bandwidth of 115Mbps, StellaTrain is faster than both compressed and uncompressed systems, achieving up to 104 times faster TTA than PyTorch DDP. Additionally, it dynamically adjusts compression rate and batch size based on bandwidth, achieving higher iteration speed.
- Cost Savings: Compared to using only on-premises or cloud GPUs, StellaTrain can reduce cloud costs by 64.5% and training time by 29%, by leveraging public cloud in combination with an on-premises cluster.
This result is significant because it demonstrates how StellaTrain can optimize training processes in resource-constrained environments.
Q1: It seems you only update part of the gradient. Will this impact model convergence?
A1: Updating part of the gradient does affect the convergence speed, slowing it down by about 20%. However, it does not impact the final convergence. The model will eventually converge to the same accuracy.
Q2: Can your approach support Tensor Parallelism? Tensor Parallelism requires a really large bandwidth.
A2: This is our first work in our research group, and we have only focused on data parallelism this time. However, this can be extended. If we use Tensor Parallelism within a node and data parallelism across nodes, we can use this approach to leverage multiple types of parallelism simultaneously.
Q3: How do you stably measure time to accuracy? The curve can vary; if you train twice with some random seed, the time to reach a certain accuracy threshold might differ. For example, even if you set the accuracy target to 95% and train twice, sometimes the second trial may never reach the threshold. So how do you measure time to accuracy reliably?
A3: We maintain a target accuracy for each model and measure the time it takes to reach this accuracy. While the results may vary from model to model, in our evaluation, we set a custom target accuracy and measure the time to reach these target levels.
Q4: If you train twice, the results might be different. It might reach the accuracy threshold earlier or later. How do you ensure stable measurement?
A4: In our evaluation, we measure the number of iterations it takes to arrive at a certain accuracy or loss.
Personal Thoughts: The approach taken by StellaTrain is impressive, particularly in how it effectively balances computational and communication loads using a combination of consumer-grade GPUs and CPUs. The cache-aware compression and sparse optimizer are great solutions that address real-world constraints in academic and budget-limited settings.