Title: Agua: A Concept-Based Explainer for Learning-Enabled Systems
Authors: Sagar Patel (University of California, Irvine); Dongsu Han (KAIST); Nina Narodytska (VMware Research by Broadcom); Sangeetha Abdu Jyothi (University of California, Irvine)

Introduction
This paper addresses the challenge of explainability in learning-enabled systems, particularly in computer systems and networking applications such as adaptive bitrate streaming, congestion control, and DDoS detection. While deep learning offers superior performance, operators often struggle to interpret and debug these models. Existing feature-based explainers mainly highlight low-level input features, but their explanations are often complex, unintuitive, and insufficient for understanding higher-level patterns. Thus, there is a pressing need for more human-understandable explanations that bridge the gap between opaque machine learning models and system operators.
Key idea and contribution:
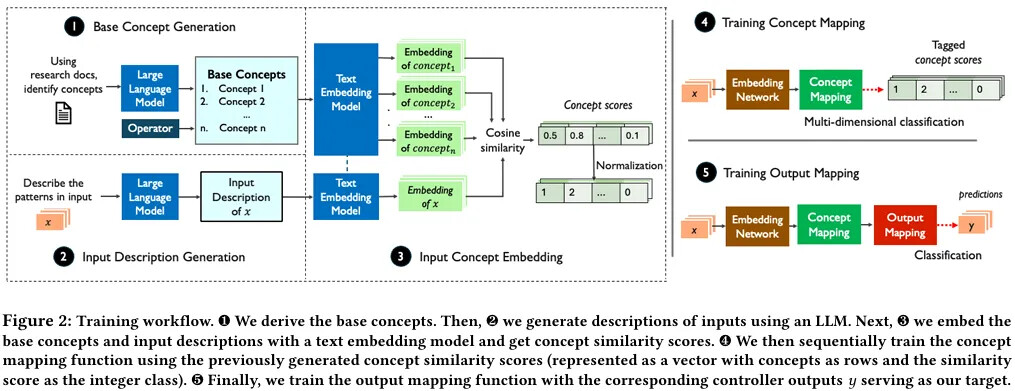
The authors propose Agua, the first concept-based explainer for learning-enabled systems. Unlike traditional feature-level explainers, Agua explains decisions in terms of high-level concepts (e.g., “volatile network conditions” or “rapidly depleting buffer”) that align with human reasoning and operator intuition. Agua achieves this by constructing a surrogate model with two mappings: from controller embeddings to a concept space, and from concepts back to controller outputs. To generate concepts, Agua combines domain knowledge, empirical analysis, and large language models (LLMs). This design enables Agua to reveal the key concepts driving a controller’s decisions while remaining robust to noisy data and LLM variability.
A major contribution of Agua is demonstrating its utility throughout the system lifecycle. The framework supports debugging unintended behaviors, detecting distribution shifts, guiding retraining with targeted data, and even augmenting datasets.
Evaluation
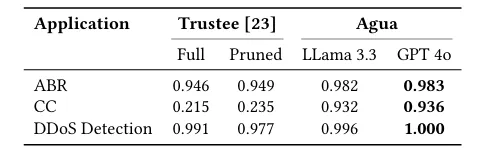
The evaluation spans three representative applications: adaptive bitrate streaming, congestion control, and DDoS detection. Across all domains, Agua achieves high fidelity (93–99%), consistently outperforming the state-of-the-art feature-based explainer Trustee by large margins, especially in complex settings like congestion control. The paper also showcases practical case studies, such as debugging Aurora to achieve more stable throughput, and using concept-based retraining to adapt to distribution shifts more efficiently than traditional retraining. This result is significant because it demonstrates that concept-based explanations are not only more interpretable, but also directly useful for improving the reliability, adaptability, and robustness of learning-enabled systems.
Q1: For scenarios that involve multiple ML models as part of a bigger system, how would you evolve your design for such scenarios?
A1: Transitioning from a single ML model to a system of multiple interacting models is challenging because of the need to manage cascading effects and propagate gradients across components. While there is potential in time-series–based approaches, similar to methods used in large language models, I am not sure how best to adapt their system to this setting. Anyway, I think some thing can be done.
Q2: Why don’t you use a large language model to just explain the explanation?
A2: Because LLMs lack guardrails and can produce outputs without guaranteeing accuracy. That means I lose my formalization of what an explanation is, and I can’t be sure whether the explanation truly reflects the system’s behavior or is just made up. Fidelity is already a difficult problem, and relying on post-hoc LLM explanations makes it even harder to evaluate correctness.
Q3: Your system uses a separate model to explain concepts rather than the neural network itself, the prior work uses same neural network for concept prediction, I wonder how fidelity is measured in your setup?
A3: While large language models are used only to generate labeled data, the actual explanation process does not rely on them. Instead, fidelity is measured through a separate pipeline that partially leverages the controller’s original model, combined with concept mapping and output mapping functions, creating a numerical flow that avoids dependence on large language models.
Personal thoughts
This paper pushes explainability beyond feature attribution toward concept-level reasoning, which is much closer to how human operators naturally think. The integration of LLMs for concept generation is an innovative and timely idea, showing how modern AI tools can enhance system management.
On the downside, the reliance on high-quality base concepts remains a potential weakness: if the concept set is poorly chosen or too overlapping, explanations may lose fidelity or clarity. Looking forward, I believe an interesting open direction would be extending concept-based reasoning to unify not just model explanations, but also the training and optimization processes—enabling operators to understand both what the model does and why it learned that behavior. Additionally, exploring interactive, intent-driven controller design using concept-level explanations could be a promising frontier.