Title: Alibaba Stellar: A New Generation RDMA Network for Cloud AI
Authors: Jie Lu, Jiaqi Gao, Fei Feng, Zhiqiang He, Menglei Zheng, Kun Liu, Jun He, Binbin Liao, Suwei Xu, Ke Sun, Yongjia Mo, Qinghua Peng, Jilie Luo, Qingxu Li, Gang Lu, Zishu Wang, Jianbo Dong, Kunling He, Sheng Cheng, Jiamin Cao, Hairong Jiao, Pengcheng Zhang, Shu Ma, Lingjun Zhu, Chao Shi, Yangming Zhang, Yiquan Chen, Wei Wang, Shuhong Zhu, Xingru Li, Qiang Wang, Jiang Liu, Chao Wang, Wei Lin, Ennan Zhai, Jiesheng Wu, Qiang Liu, Binzhang Fu, Dennis Cai (Alibaba Cloud)

Introduction
The paper studies how to deliver high-performance RDMA for large-scale cloud AI training/inference under virtualization, where today’s mainstream approach—SR-IOV with VF passthrough and hardware flow steering—suffers from poor scalability (VF inflexibility and huge memory overhead), long container start-up due to GPA pinning (VFIO/IOMMU), unstable performance from interference with non-RDMA traffic, and inability to exploit abundant multi-path capacity in modern AI fabrics. This matters because LLM training is increasingly network-bound (RDMA and GPUDirect RDMA), and cloud operators need both bare-metal-like performance and multi-tenant practicality/stability—something current solutions fall short of providing.
Key idea and contribution
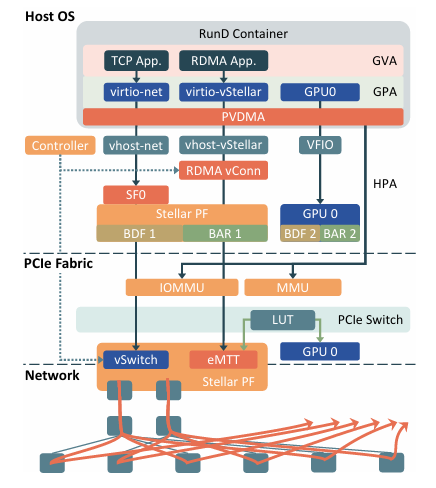
The authors propose Stellar, a next-generation, end-to-end RDMA virtualization stack that removes SR-IOV and rethinks the design across host, PCIe/IOMMU, and RNIC:
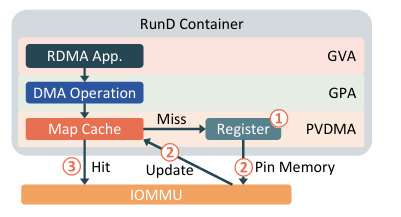
- PVDMA (Para-Virtualized DMA) at the hypervisor boundary: instead of pinning all guest memory up front, Stellar intercepts DMA ops and pins on demand, caching GPA→HPA translations (“Map Cache”). This slashes secure-container boot time while preserving the reuse semantics RDMA apps expect.
- eMTT for GPUDirect RDMA on the NIC: Stellar extends the NIC’s Memory Translation Table with a memory-type tag so the RNIC can bypass ATS/ATC lookups when accessing GPU memory. This avoids ATC/IOTLB thrashing that degrades GDR throughput on commodity ATS-based designs, keeping GDR bandwidth stable as messages grow.
- RDMA packet spraying across many equal-cost paths: Stellar implements oblivious packet spraying (OBS) at the RNIC and scales to 128 paths per connection, handling out-of-order robustly. This better utilizes fabric bisection and smooths contention compared to RR/BestRTT/DWRR or single-path ECMP steering.
The system ships as vStellar (virtio/vhost style para-virtual device + driver) and a custom RNIC dataplane (FPGA-based 400G in deployment). Together they provide 64K virtual devices, ~1.5 s per-device bring-up, tight isolation via RDMA protection domains, and no SR-IOV/VF flow-rule juggling—improving scalability, stability, and multipath utilization for AI clusters.
Evaluation
On testbeds and in production clusters, Stellar/vStellar:
- Cuts secure-container initialization time by up to 15×, keeping boot <20 s even with very large guest memory.
- Maintains high, flat GDR throughput as message sizes increase, whereas an ATS/ATC-based baseline (e.g., CX6) drops from ~190→170→~150 Gbps as sizes grow due to ATC/IOTLB pressure.
- With 128-path OBS, achieves higher bus bandwidth and shallower/steadier queues under static and bursty backgrounds than RR/BestRTT/DWRR, and shows resilience to link failures.
- Near-zero virt overhead vs bare-metal Stellar for RDMA latency/throughput; outperforms a VF+VxLAN baseline (which incurs ~7% extra latency for tiny packets and ~9% bandwidth loss for 8 MB).
- End-to-end LLM training speedups up to ~14% at cluster scale.
Q&A
Q: Are there any mechanisms to enforce isolation between virtual machines (VMs)? How exactly is it implemented?
A: The system implements isolation via pure software-based virtualization, differing from traditional hardware isolation. It relies on clear software isolation between containers to prevent memory leaks or invalid memory accesses. While not hardware-level isolation, it ensures security through software mechanisms.
Personal thoughts
PVDMA fixes the long-standing GPA-pinning tax at its root, eMTT tackles a real PCIe/IOMMU scaling pain for GDR, and RNIC-native multipath aligns with AI traffic realities (large, long-lived collectives) rather than generic tail-latency microflows. The deployment angle (FPGA-based 400G RNIC, 64K vDevs, multi-segment clusters) and the “virt is basically free” results make a strong practicality case for serverless AI.
Open questions I’d explore: (1) Portability—what subset of eMTT/OBS could map to commodity SmartNICs/DPUs without FPGA freedom? (2) Operations & observability—oblivious spraying complicates header-based path attribution; what telemetry/debug hooks are needed? (3) Inter-CC coexistence—how OBS interacts with modern DC congestion control (Swift/HPCC/FAST-FLOW) and with RoCEv2 PFC/ECN settings at scale. (4) Standardization—could the memory-type hinting behind eMTT be codified for broader PCIe/IOMMU adoption? (5) GPU-stack interplay—implications for MIG/vGPU scheduling and NVLink/NVSwitch topologies as GPU partitioning becomes the norm.