Authors: Qingkai Meng, Hao Zheng, Zhenhui Zhang, ChonLam Lao, Chengyuan Huang, Baojia Li, Ziyuan Zhu, Hao Lu, Weizhen Dang, Zitong Lin, Weifeng Zhang, Lingfeng Liu, Yuanyuan Gong, Chunzhi He, Xiaoyuan Hu, Yinben Xia, Xiang Li, Zekun He, Yachen Wang, Xianneng Zou, Kun Yang, Gianni Antichi, Guihai Chen, Chen Tian (Nanjing University, Harvard University, Tencent, Politecnico di Milano and Queen Mary University of London)
Scribe: Haodong Chen (Xiamen University)
Introduction

With the rapid growth of LLM parameters and training data, datacenter computation, networking, and energy systems face unprecedented challenges. This paper presents Astral, a datacenter infrastructure architecture supporting up to 500K GPUs, designed for large-scale LLM training and inference.
Core Ideas and Contributions
The Astral architecture consists of three main components:
-
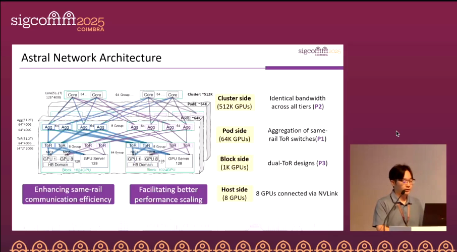
Network architecture
Astral adopts a same-rail aggregation + three-tier equal-bandwidth design: same-rail ToRs are aggregated to maximize Pod size (up to ≈64K GPUs per Pod). Bandwidth is kept equal across ToR–Agg–Core tiers to avoid oversubscription, congestion bottlenecks, and ECMP polarization. On each server, 8×NICs (each 2×200 Gbps) provide each GPU with a dedicated 400 Gbps RDMA rail, for a total of 3.2 Tbps per host. Reliability is enhanced by connecting the two ports of the same NIC to different ToRs, while Core switches enable cross-rail connectivity without oversubscription, scaling the cluster to ≈512K GPUs.
-
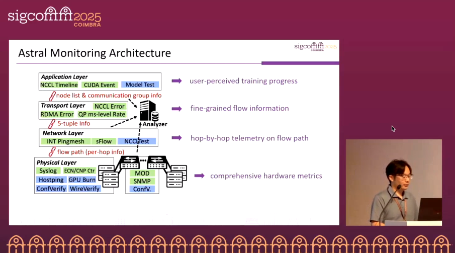
Astral Monitor
A full-stack monitoring system spanning from applications down to the physical layer: the top layer collects CUDA/NCCL timelines and errors; the transport layer measures RDMA QP-level throughput (at millisecond granularity) and five-tuple paths; the network layer reconstructs routes and hop latencies using sFlow and INT; the physical layer aggregates ECN/CNP/MOD/SNMP counters and host/port logs. Astral Monitor applies cross-host comparison and hierarchical correlation to precisely map application anomalies to lower-layer root causes. Offline tools such as WireVerify, ConfVerify, Hostping, and GPU-Burn are integrated for verification and fault reproduction.
-
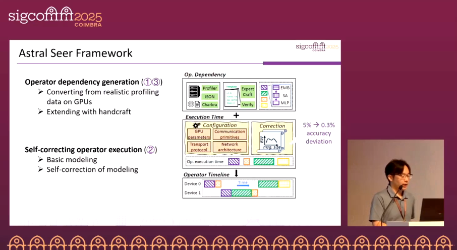
Seer
Seer provides operator-granular “foresight” timelines: it estimates execution time for compute, memory, and communication operators via basic models, then self-calibrates using real production bandwidth. This absorbs packet-level effects (e.g., grouping and congestion) into effective throughput, enabling second-level generation of iteration timelines. Seer serves as both an expected baseline for runtime anomaly diagnosis and as a planning tool for parallelism/overlap strategies, network configuration optimization, and evaluating new operators or cross-datacenter training topologies.
Evaluation
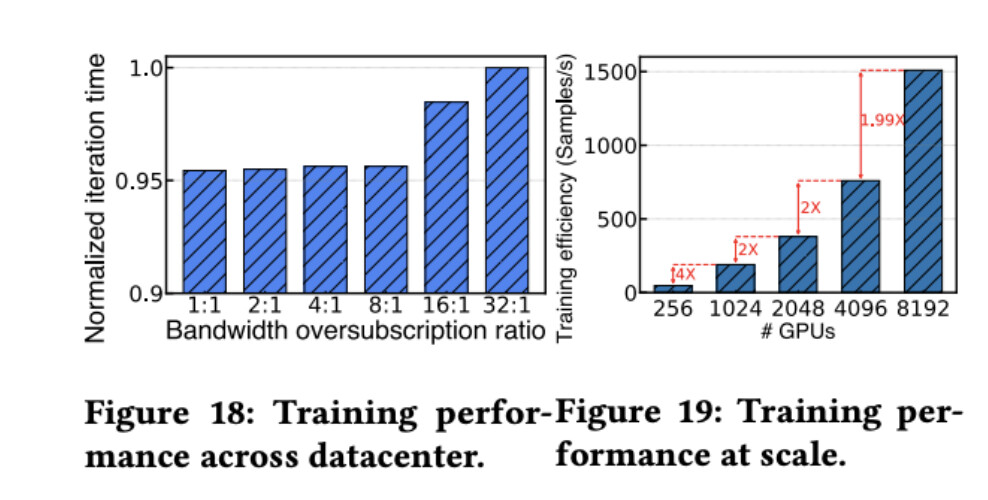
Scalability (Fig. 19, Appendix)
Deployed in production, Astral’s same-rail aggregation with three-tier equal bandwidth enables near-linear scaling: on Hunyuan-MoE, expanding to 8K GPUs incurs only ~0.6% efficiency loss.
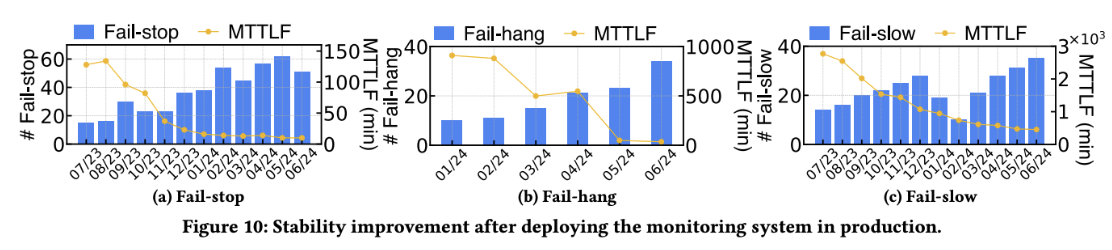
Reliability & Troubleshooting (Fig. 10)
With Astral Monitor’s cross-host comparison and hierarchical correlation (app → transport → network → physical), Mean Time To Locate Failure (MTTLF) is reduced to minutes with up to 12× (fail-stop) and 25× (fail-hang) reductions, and nearly 5× for fail-slow.
Q&A
Q1: How does Astral set thresholds to capture key events without excessive false triggers?
A1: By combining Seer’s expected timeline (which provides reference execution for each iteration/operator) with cross-host comparison (to identify outliers across peers), and correlating anomalies down to QPs, paths, and hop-level counters, thus avoiding false positives or negatives caused by static thresholds.
Q2: Is this an offline or online diagnosis system? Would online monitoring consume significant compute/bandwidth and impact training?
A2: It is a hybrid system: Astral provides continuous online monitoring in production, complemented by offline tools for pre-deployment validation and complex failure reproduction. Overhead is minimal: QP throughput is sampled using ACL-mirrored first packets, sFlow sampling reconstructs paths, and INT pingmesh provides hop latencies—most load is on switches/NICs, with negligible impact on GPU training.
Personal View
Astral integrates same-rail aggregation + three-tier equal bandwidth networking, full-stack monitoring across applications to physical layers, and operator-granular prediction via Seer. It represents a production-ready infrastructure capable of scaling up to half a million GPUs for LLM training and inference. Future work could further optimize monitoring–mitigation integration and enhance automated reliability, achieving even higher performance and robustness.