Title: ByteScale: Communication-Efficient Scaling of LLM Training with a 2048K Context Length on 16384 GPUs
Author:
Hao Ge (Peking University)
Junda Feng (ByteDance Seed)
Qi Huang (ByteDance Seed)
Fangcheng Fu (Shanghai Jiao Tong University)
Xiaonan Nie(ByteDance Seed)
Lei Zuo (ByteDance Seed)
Haibin Lin(ByteDance Seed)
Bin Cui(Peking University)
Xin Liu(ByteDance Seed)
Scribe: Mingjun Fang(Xiamen University)
Introduction

This paper focuses on the communication bottleneck that arises in large-scale LLM training as context length grows into the range of hundreds of thousands or even millions of tokens. Existing approaches rely on either data parallelism or context parallelism in isolation, and both suffer from severe inefficiencies. Data parallelism explodes communication costs as sequence lengths increase, while context parallelism wastes resources when short and long sequences are processed together. The authors argue that the root of the problem lies in the rigidity of current parallelization strategies, which treat all sequences as though they required the same partitioning scheme, leading to poor utilization and excessive waiting times across devices. This diagnosis motivates the design of ByteCycle.
Key idea and contribution
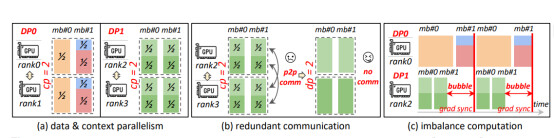
The central idea of ByteCycle is to propose a new hybrid parallelism paradigm that merges data and context parallelism into a unified communication model, dynamically adapting to sequence lengths. Its contributions are multifaceted: first, it introduces a selective offloading mechanism so that short sequences can be processed entirely on a single GPU without needless cross-device synchronization, while only long sequences are distributed; second, it develops a novel micro-batch scheduling approach that ensures balanced workloads even under heterogeneous sequence lengths, which minimizes pipeline bubbles and idle time; and third, it provides a lightweight data-aware communication optimizer that makes this scheme scalable to tens of thousands of GPUs. These contributions are not isolated tricks but rather represent a paradigm shift in distributed training design, redefining how parallelism should be orchestrated when training with extremely long contexts.
Evaluation
The evaluation is carried out on a massive cluster of 16,384 GPUs, covering both dense models such as LLaMA from 7B to 70B parameters and sparse MoE models such as Mistral 8×7B and 8×22B, with context lengths scaled up to 2,048K. On the GitHub dataset, baseline systems exhibit nearly halved throughput when context length doubles, whereas ByteCycle’s throughput drops only by a factor of 1.08, demonstrating remarkable stability under long contexts. On the Byted dataset, although sequence distribution introduces additional challenges, ByteCycle still significantly outperforms existing systems. The reported maximum speedup is an impressive 7.89× over state-of-the-art baselines, effectively setting a new benchmark for long-context training. Ablation studies further confirm that selective offloading, balanced scheduling, and remote data loading each make measurable contributions, ensuring that the performance gains are a direct consequence of the holistic design rather than a lucky artifact of one optimization. In sum, the evaluation establishes ByteCycle as a robust and scalable framework that fundamentally changes what is possible in long-context LLM training. Scallop decouples SFU functions into three tiers based on operational frequency and latency requirements: session management and other infrequent and non-real-time tasks are handled by a centralized controller; medium-frequency tasks such as bandwidth estimation and feedback processing are managed by a switch agent deployed on the hardware device, forming a low-latency control loop; while the most frequent and latency-sensitive operations—media packet replication, forwarding, and dropping—are entirely offloaded to the hardware data plane, thereby achieving optimal performance and scalability.
Q&A
Q1: You introduce hybrid data parallelism and beta dynamic offloading with selective offloading, and study the performance on 16,000 homogeneous CPUs. Do you have any experience or idea how sensitive the performance is to heterogeneous GPU clusters, especially when memory and interconnect speeds differ?
A1: The performance indeed varies because communication bandwidth and computation power differ across GPUs. The key point is how well communication and computation can be overlapped. When using different GPUs, it may be necessary to adjust the number of tokens per rank to better achieve overlapping.
Q2: You focus on LLM training and optimize communication overlapping. Can similar ideas be applied to LLM inference?
A2: Yes, the same idea applies to inference, especially for long-context inference. Techniques like context parallelism or sequence parallelism can also be used, but one must carefully handle the balance between long and short sequences.
Personal thoughts
The core idea of this paper—dynamically assembling communication groups based on the actual sequence length rather than using a static mesh—left a deep impression on me. This is not merely an optimization but rather a paradigm shift that acknowledges the inherent heterogeneity in real-world data. I believe the future of distributed training systems should be as proposed in the paper: adaptive, data-aware, and fluid. However, although the experiments achieved a remarkable 7.89x speedup, I think we still need to pay attention to the systematic overhead of its dynamic scheduling mechanism. The paper excellently optimizes GPU time but does not discuss the cost on the CPU side, including continuously profiling sequences, solving the optimization problem in Eq. (3) for every micro-batch, and coordinating the remote dataloader with Ray. At their massive scale of 16K GPUs, this overhead from metadata management and scheduling decisions could become a non-trivial bottleneck, potentially further limiting scalability or making the system highly sensitive to host machine performance.