Title: ByteTracker: An Agentless and Real-time Path-aware Network Probing System
Authors: Shixian Guo (ByteDance China), Kefei Liu (ByteDance China, State Key Laboratory of Networking and Switching Technology, BUPT, China), Yulin Lai (ByteDance China), Yangyang Bai (ByteDance China), Ziwei Zhao (ByteDance China), Songlin Liu (ByteDance China), Jianghang Ning (ByteDance China), Gen Li (ByteDance China), Jianwei Hu (ByteDance China), Yongbin Dong (ByteDance China), Feng Luo (ByteDance China), Sisi Wen (ByteDance China), Qi Zhang (ByteDance China), Yuan Chen (ByteDance China), Jiale Feng (ByteDance China) Yang Bai (ByteDance China), Chengcai Yao (ByteDance China), Zhe Liu (ByteDance China), Xin Hu (ByteDance China), Yang Lv (ByteDance China), Zhuo Jiang(ByteDance China), Jiao Zhang(State Key Laboratory of Networking and Switching Technology, BUPT, China, Purple Mountain Laboratories), Tao Huang(State Key Laboratory of Networking and Switching Technology, BUPT, China, Purple Mountain Laboratories)
Scribe: Mengrui Zhang(Xiamen University)
Introduction:
This paper studies the problem of efficient and accurate network fault detection in large-scale data center networks. As data centers grow to millions of servers, existing systems like Pingmesh face challenges such as high probe noise from end hosts, slow and inaccurate path tracking, inability to detect subtle failures (e.g., bit flipping, low-rate packet drops), and difficulties in managing millions of distributed probing agents. These issues make it hard to achieve timely and precise fault localization, which is critical for fault-sensitive services like distributed training. Therefore, building a more accurate, real-time, and scalable probing system is both important and interesting.
Key idea and contribution:
The authors present ByteTracker, the first agentless and real-time path-aware probing system. Instead of relying on end-host agents, ByteTracker deploys a small set of dedicated Probers at each data center ingress. Probers send specially crafted TCP SYN packets with invalid destination ports, triggering automatic RST replies from the OS kernel of the target servers. This design eliminates the need for probe agents on servers, reduces end-host noise, and ensures timely responses.
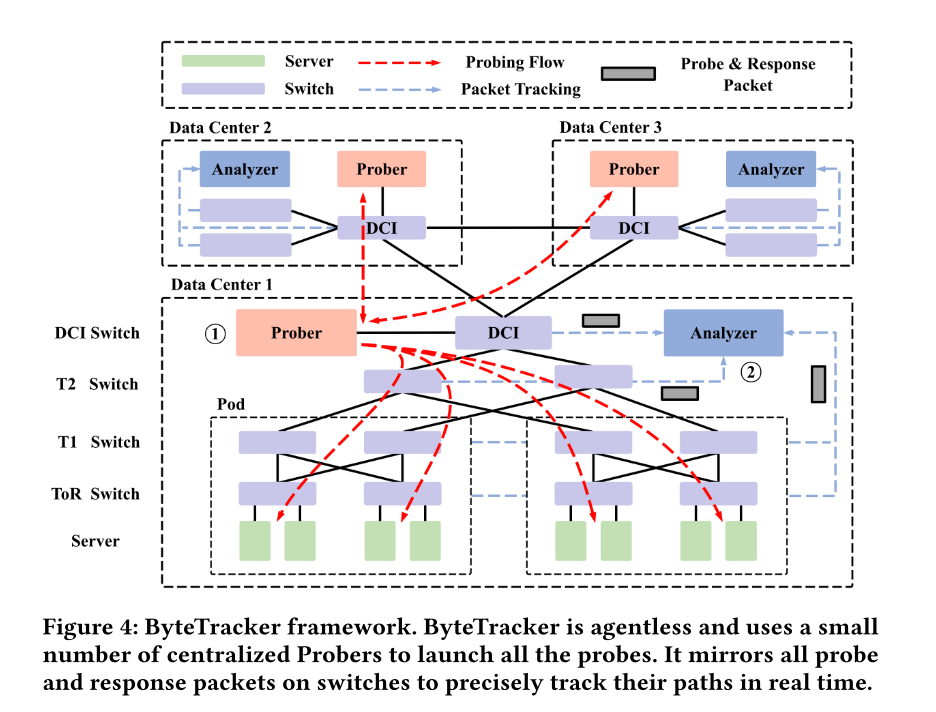
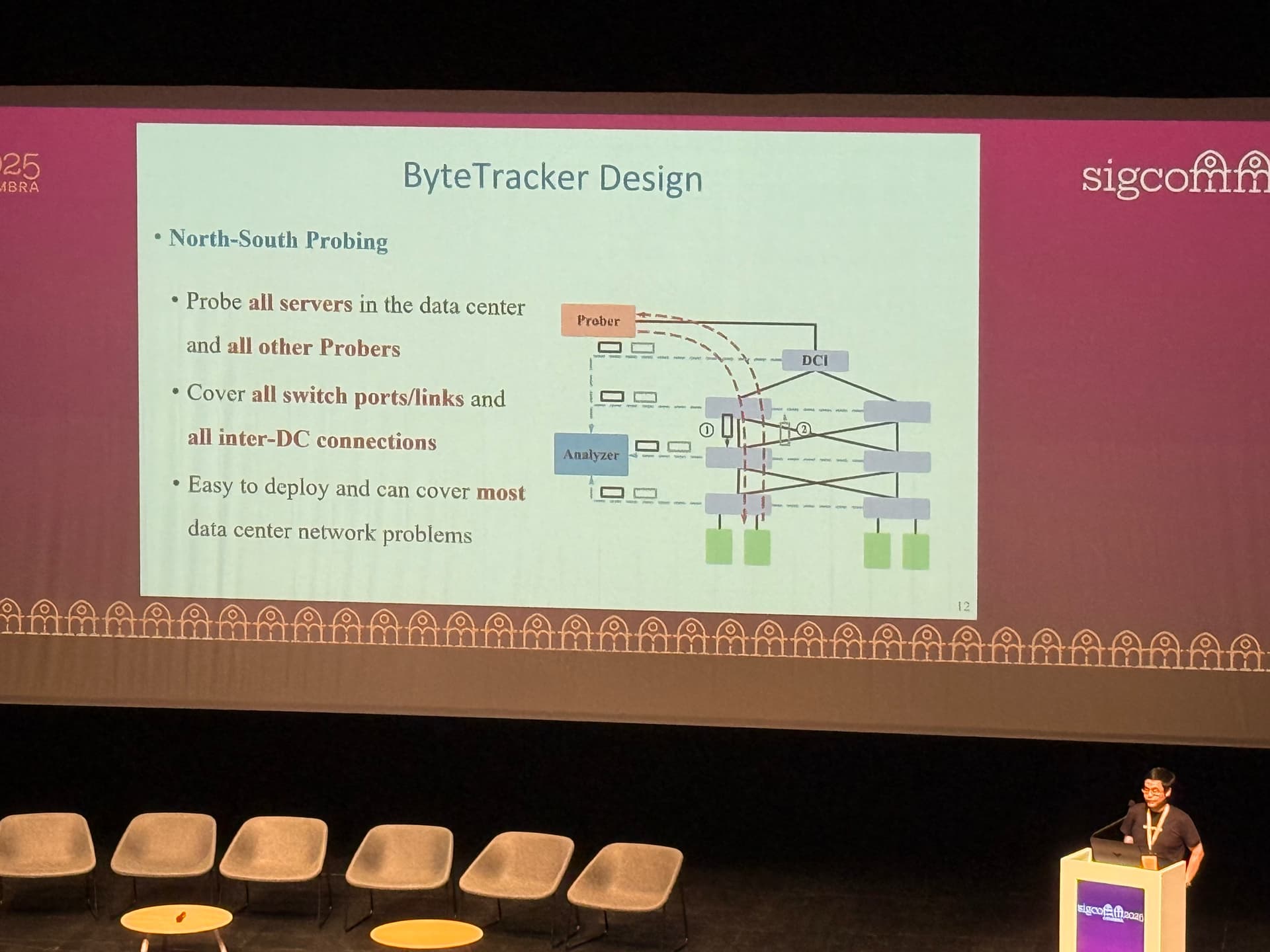
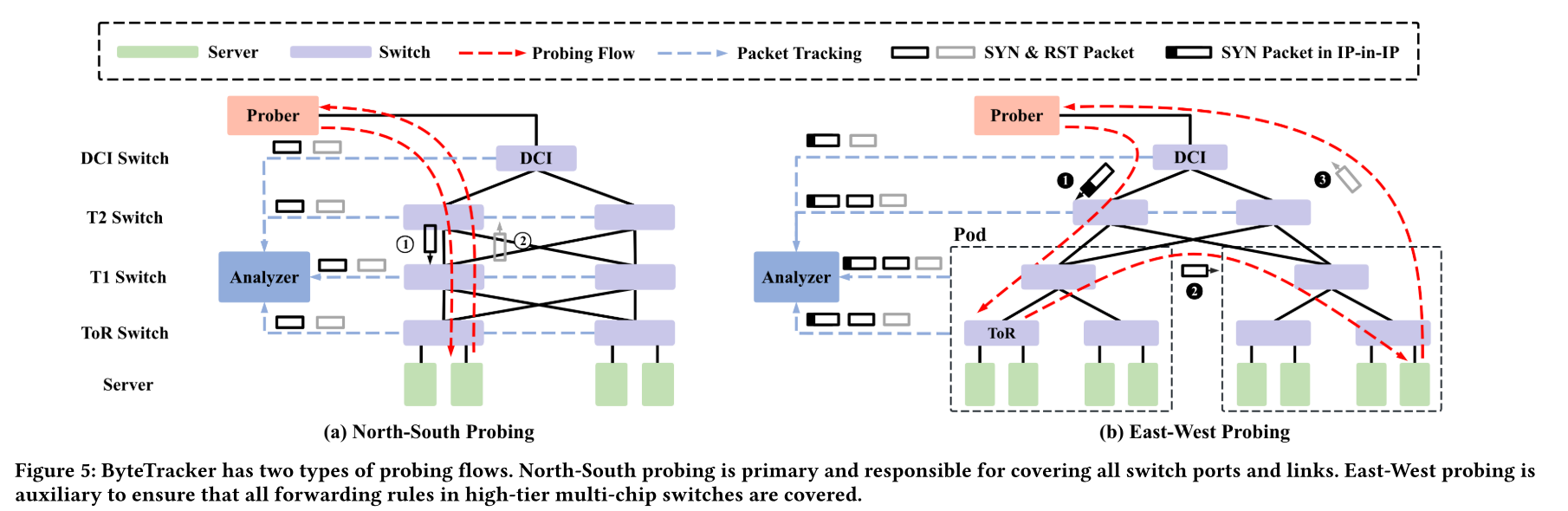
ByteTracker combines North-South probing, which covers all switch ports and inter-tier links, with East-West probing, which ensures forwarding logic coverage in multi-chip switches. It classifies network vs. host timeouts by sending parallel probes along different paths and leverages ERSPAN-based packet mirroring for real-time path tracking and hop-by-hop content comparison. This enables the system to detect subtle anomalies, such as silent packet drops and even rare bit flipping events, while locating faulty devices with near-perfect accuracy.
Evaluation:
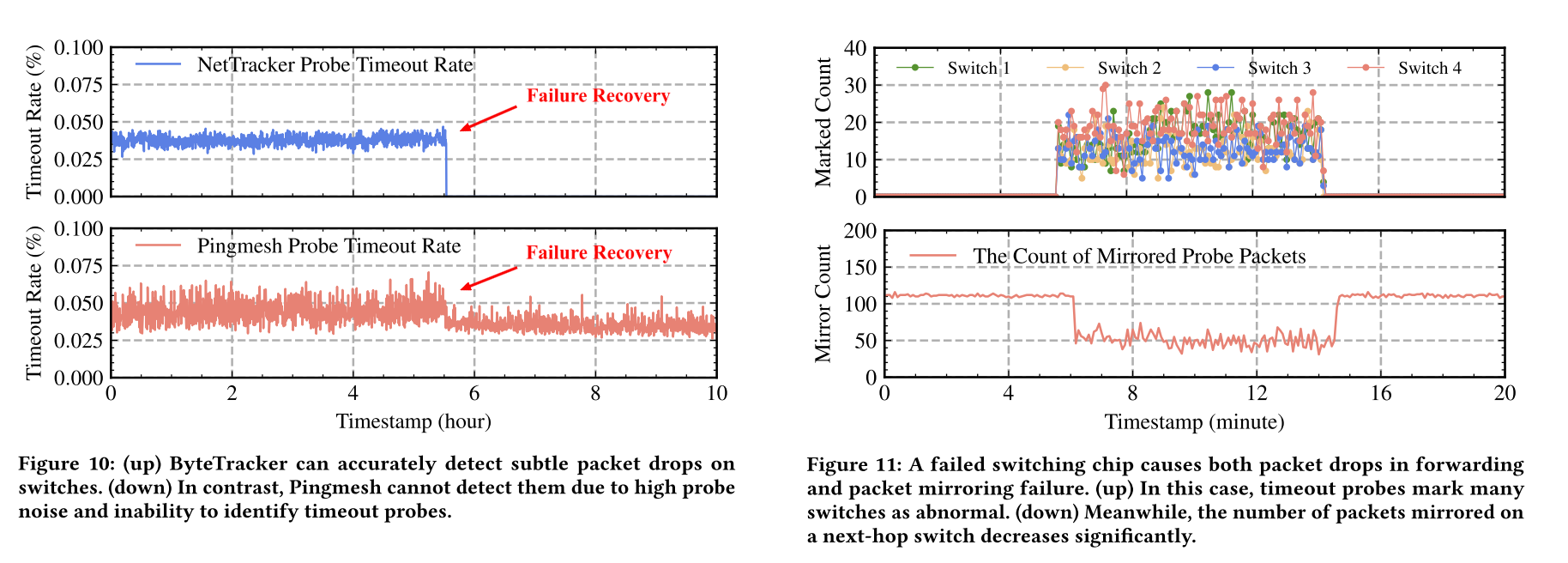
ByteTracker has been deployed across ByteDance’s global data centers, covering hundreds of thousands of servers. In a six-month evaluation, it detected 276 network anomalies, including subtle packet drops and silent bit flipping that previous systems could not detect, and localized them within five seconds with 100% accuracy. Compared to Pingmesh, ByteTracker produced fewer false alarms, avoided probe noise, and required negligible host and bandwidth overhead.
Q&A
Q1: How does ByteTracker interact with adaptive routing systems that may change probe paths?
A1: The authors note that adaptive routing can indeed interfere, but it can be mitigated by setting ACL rules to force certain packets to follow fixed paths or by simulating end-host traffic patterns for route consistency.
Q2: What is the role of multi-chip switches in the evaluation, and how do they compare with single-chip switches?
A2: Multi-chip switches are typically deployed at higher tiers due to their bandwidth advantage but are harder to manage and more failure-prone. ByteTracker helps uncover and localize the issues caused by these switches.
Q3: How frequently are ByteTracker probes invoked, and does higher frequency improve results?
A3: ByteTracker sends only a limited number of probes per second, resulting in very low bandwidth overhead (hundreds of Mbps across an entire data center). Increasing frequency is generally unnecessary because the system already achieves reliable detection.
Q4: What does “real-time” mean in ByteTracker?
A4: Real-time refers to detection and localization within seconds (not milliseconds). For microsecond-level analysis, additional systems would need to be integrated.
Q5: How does ByteTracker coexist with RpMesh or other probe systems?
A5: ByteTracker complements agent-based systems. For servers where deploying RpMesh agents is infeasible, ByteTracker provides reliable coverage. Where RpMesh agents are available, the two systems can work together, with RpMesh providing additional host-level visibility.
Personal thoughts:
I really like the clean and practical design of ByteTracker: removing the need for end-host agents not only reduces operational complexity but also makes the system much more robust and controllable. The combination of North-South and East-West probing to cover different failure modes is also clever and grounded in real-world deployment insights.