Title:CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving
Authors: Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang(University of Chicago); Qizheng Zhang(Stanford University); Kuntai Du(University of Chicago); Jiayi Yao(The Chinese University of Hong Kong, Shenzhen);Shan Lu(Microsoft Research);Ganesh Ananthanarayanan(Microsoft);Michael Maire(The University of Chicago); Henry Hoffmann(University of Chicago); Ari Holtzman(Meta,University of Chicago); Junchen Jiang(University of Chicago)
Speaker:Hanchen Li(University of Chicago)
Scribe:Xuanhao Liu(Xiamen University)
Introduction:
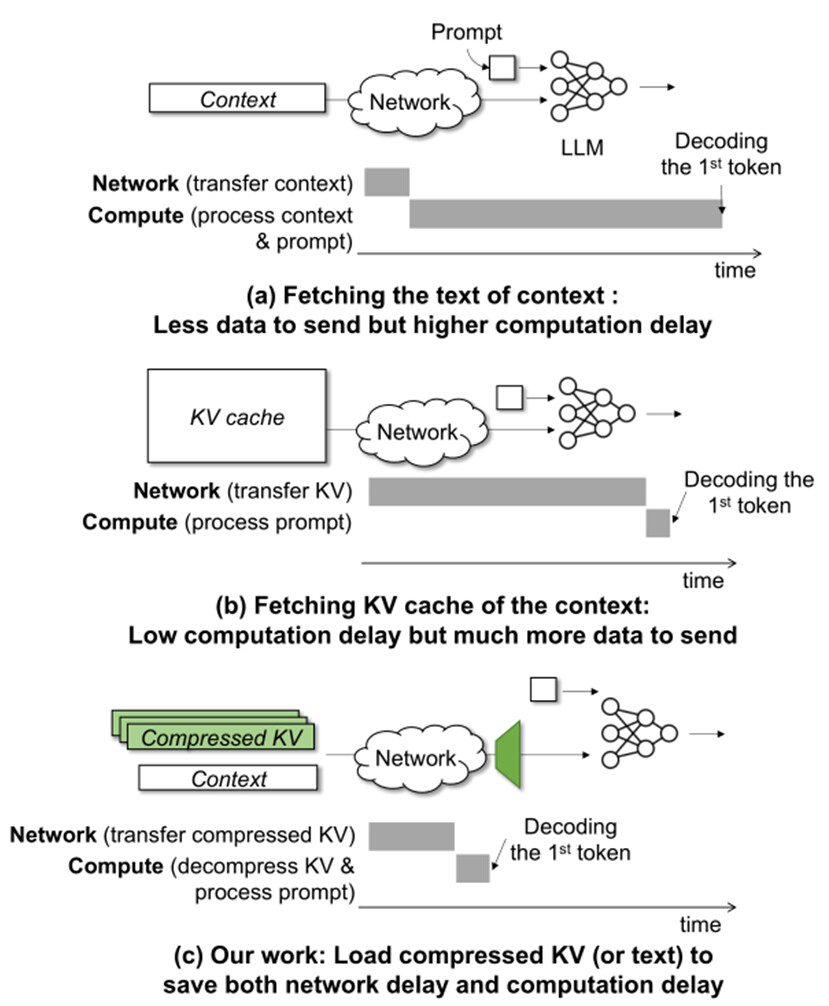
As large language models(LLMs) take on complex tasks,whose inputs are supplemented with longer contexts, they always reuse the KV cache of context across different inputs to reducethe context-processing delay, this paper introduces how to decrease the high extra network delays caused when fetching the KV cache over the network. They reduce the transmission-time size of KV cache by encoding it into compact bitstreams to reduce the network delay of sending it. Existing approaches that drop words (tokens) from the text context or quantize the KV cache tensors delete a part of the KV cache, resulting in incomplete content.
Key idea and contribution:
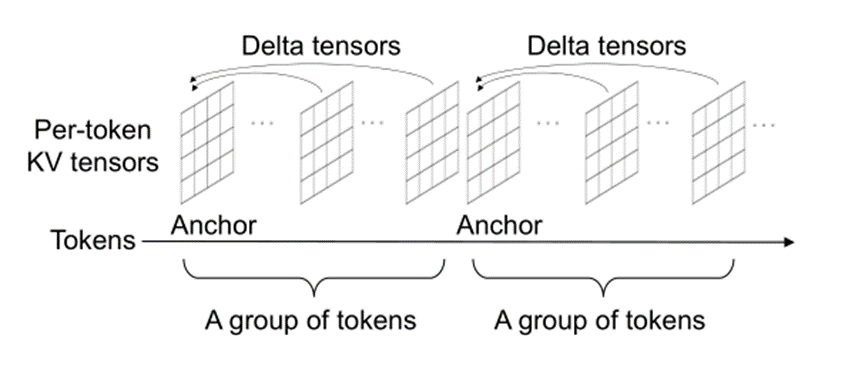
Based on three insight: 1. Within the same layer and channel, tokens in closer proximity have more similar K/V tensor values compared to tokens that are further apart. 2. The output quality of the LLM is more sensitive to losses in the KV cache values of the shallower layers than to losses in those of the deeper layers. 3. Each value in a KV cache is indexed by its channel, layer, and token position. The information gain of grouping values by their channel and layer is significantly higher than the information gain of grouping values by their token position. The encoding of CacheGen’s KV cache encoder consists of three high-level steps:First, they split the context into groups of tokens, independently compress the KV tensor of the first token and record the delta tensors with respect to the anchor token for every other token rathe than compressing the delta between each pair of consecutive tokens. It allows they to do compressing and decompression in parallel and saves time. Second, they reduce the precision of elements (floating points) in a KV cache by quantization so that they can be represented by fewer bits. Third, CacheGen uses arithmetic coding to losslessly compress the delta tensors and anchor tensors of a context into bitstreams. The KV encoder offline profiles a separate probability distribution for each channel-layer combination of delta tensors and another for anchor tensors produced by an LLM, and uses the same distributions for all KV caches produced by the same LLM.
During the workflow of CacheGen.When fetching a context, CacheGen sends these chunks one by one, and each chunk can choose one of several streaming configuration (or configurations for short): it can be sent at one of the encoding levels or can be sent in the text format to let the LLM recompute K and V tensors, and CacheGen estimates the bandwidth by measuring the throughput of the previous chunk. Because encoding the KV tensor of a token only depends on itself and its delta with the anchor token of the group of tokens, Each chunk is encoded independent to other chunks without affecting the compression efficiency as long as a chunk is longer than a group of tokens.
Evaluation:
Compared to default quantization, CacheGen is able to reduce TTFT by 3.2-3.7×. And it achieves better quality-size trade-offs across different settings, The degradation caused by lossy compression is marginal—the degradation is no more than 2% in accuracy, less than 0.1% in F1 score, and less than 0.1 in perplexity when CacheGen’s KV encoder reduces the KV cache size by 3.5-4.3× compared to default quantization.This result is significant because we can reduces overall delays while maintaining high task performance through CacheGen.
Q1: Do you compare the output of larger model with cache and smaller model without cache?
A1: We have done similar experiments, but it turns out that the larger model with cache actually performs much better.
Q2: I’m wondering that why searching KV cache could be a main bottleneck instead of loding process?
A2: what you could do is potentially just have a pointer that points from the raw text document to the 1st bed of this mystery, and then you can just load it, if you were talking about like agents with conversation history, there might be some overhead, but we are just currently studying this.
Q3: as you save the KV cache into the storage, I’m wondering whether the access to the storage, like usually one more than 100 microseconds, could that be a bottleneck?
A3: on that scale, I think like the small delay to access to device is not comparable. you can think of using these SSD as caching layer for the larger model, because they are much smaller.
Personal thoughts:
When existing work attempts to reduce the delay in large language models processing context caches by deleting parts of the KV cache, this paper approaches the problem from a different angle by compressing the KV cache to speed up task processing in large language models by reducing the network transmission delay of the KV cache. This has provided me with new insights for research.CacheGen compresses and transmits the KV cache for some context content that may not significantly help in solving the problem. This could impose a considerable delay burden on task processing without much improvement in result quality. If the KV cache could be filtered before compression, it might achieve a better balance between performance and latency.