Title: CClinguist: An Expert-Free Framework for Future-Compatible Congestion Control Algorithm Identification
Speaker : Jiahui Li (Fudan University)
Scribe : Yuntao Zhao (Xiamen University)
Authors: Jiahui Li, Han Qi, Ruyi Yao, Jialin Wei, Ruoshi Sun, Zixuan Chen, Sen Liu, Yang Xu (Fudan University)

Introduction
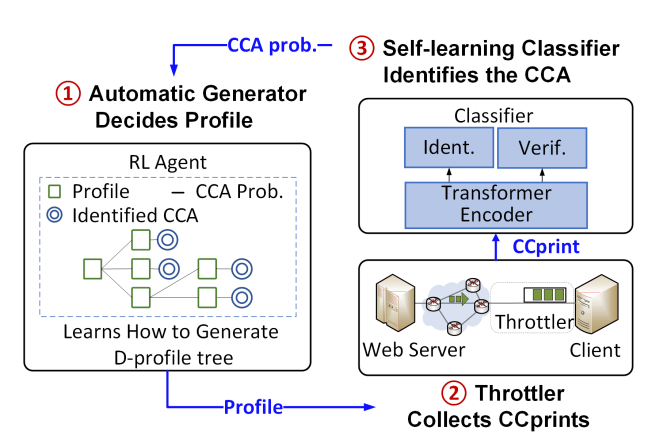
Congestion control algorithms significantly influence Internet transmission quality. With their rapid evolution—from loss-based TCP variants to recent learning-based and ECN-based schemes—network researchers increasingly need an up-to-date “census” of deployed CCAs to guide algorithm design and resource allocation. Traditional tools, however, rely on heavy expert intervention: manually crafting bottleneck profiles and repeatedly re-engineering classifiers. This manual cycle is slow, error-prone, and ill-suited to proprietary or newly emerging CCAs. CClinguist proposes an autonomous framework that eliminates experts from the loop by combining (i) an RL-driven profile generator and (ii) a transformer-based self-upgrading classifier, achieving both temporal (new CCAs) and spatial (diverse network paths) future compatibility.
Key idea and contribution:
-
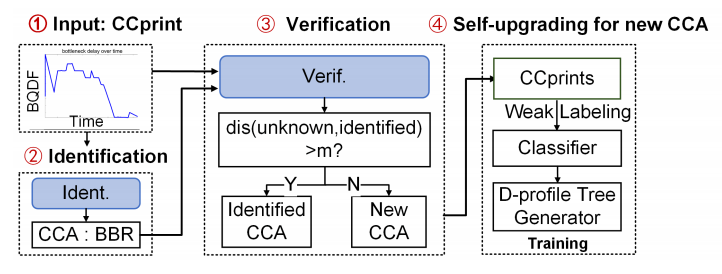
Accessible congestion fingerprints: The paper proposes using Bottleneck Queuing Delay Fluctuation (BQDF) instead of the congestion window (CWND) as the algorithm “fingerprint.” BQDF reflects the congestion state similarly to CWND but is easier to collect—by recording packet arrival times—and remains available in encrypted protocols like QUIC.
-
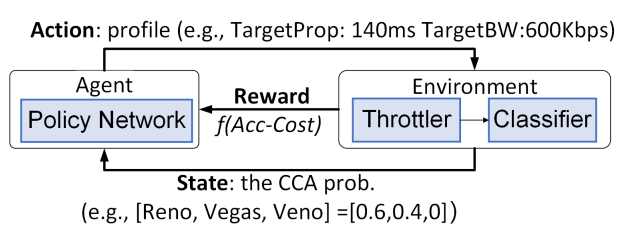
Reinforcement learning for profile discovery: A core novelty is the D-profile Tree, a hierarchy of network profiles that progressively narrows the candidate CCAs. Since one profile rarely distinguishes all algorithms, CClinguist’s RL agent chooses profiles that maximize identification accuracy and minimize path length. A reward function balances accuracy, confidence and the number of probes, ensuring the agent learns discriminative profiles.
-
Self-learning open-set classifier: CClinguist uses a transformer encoder to learn representations of BQDF time-series and a softmax layer to output class probabilities. A verification module measures distances in representation space; if a sample is far from all known classes, it is treated as “unknown”. When unknown CCAs are detected, weakly labeled data are incorporated and both the classifier and RL agent self-update, automatically expanding the CCA library.
-
Throttler for consistent measurement: To ensure reproducible data, a client-side throttler sets bandwidth and propagation delay, induces congestion via buffer control and connection reuse, and re-marks ECN bits, enabling both non-ECN and ECN-based schemes to be profiled consistently.

Evaluation
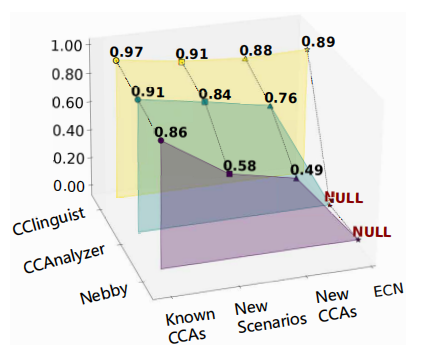
CClinguist is evaluated against CCAnalyzer and Nebby on a cloud testbed. The evaluation covers several dimensions:
-
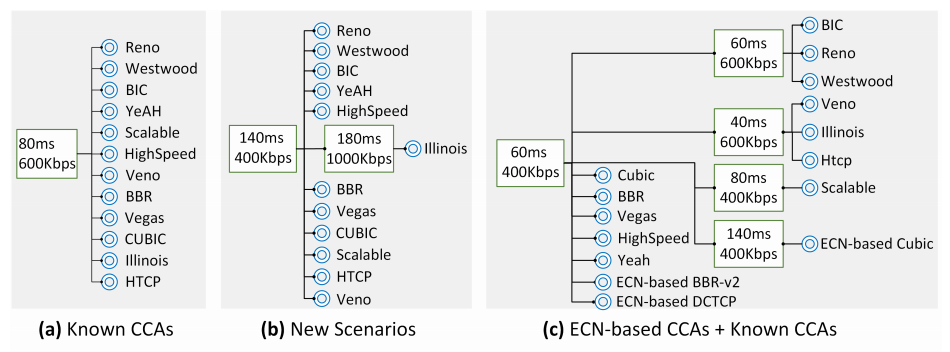
Identification of known CCAs: On twelve CCAs in Linux, CClinguist achieves an average accuracy of 97.33%, outperforming CCAnalyzer (91.66%) and Nebby (86.62%).
-
Adaptation to new scenarios: When the server-client latency increases (TYO→SV), the RL agent selects a new profile and maintains 91.67% accuracy, while CCAnalyzer and Nebby drop to 84.3% and 58.33% respectively.
-
Handling emerging CCAs: Introducing PCC-Loss, PCC-Latency and Astraea, CClinguist correctly detects them as unknown and, after self-upgrading, attains 88.33% average accuracy on fifteen CCAs.
-
ECN-based compatibility: Adding ECN-based DCTCP, Cubic and BBR-v2, CClinguist distinguishes all fifteen CCAs with 89.33% average accuracy, achieving 100% accuracy on BBR, ECN-based BBR‑v2 and Cubic, and 80–90% on ECN-based DCTCP and Cubic.
Q1: My question is, you use a transformer-based classifier, right? So did you consider using more advanced, also transformer-based, large language models for your classification? Because, as far as I know, there are some works using LLMs for networking optimizations, like NetLLM published in SIGCOMM last year. They use large language models to process sequential or time-series data. So, did you ever consider that during your design?
A1: Yes, we did consider using models like NetLLM. However, there are several reasons we ultimately chose a standard transformer over large language models. First, general-purpose LLMs don’t have built-in knowledge about congestion control algorithms, so we would need to fine-tune them, which is costly. Second, mapping text-based models to time-series data like CCprints is non-trivial and adds complexity. Lastly, when new CCAs emerge, retraining or adapting an LLM is much more expensive than incrementally updating our transformer-based classifier. That’s why we opted for a more lightweight and adaptable transformer model.
Q2: I have two questions. First, is it possible to not only identify the CCA but also infer its prime parameter settings? Second, once we know which CCA is in use, what can we do with that information?
A2: After identifying the actual CCA, we can infer its key tuning parameters—like the optimal buffer size, pacing rate, or loss threshold. These prime settings vary across CCAs: some perform best with full BDP buffering, others with half BDP, etc. So once CClinguist pinpoints the algorithm, the same framework can recommend or auto-tune these parameters to maximize throughput or minimize latency in the given network environment.
Personal thoughts
CClinguist’s main value is turning CCA identification from an artisan task into a self-driving pipeline; the RL-guided profile tree and the open-set transformer are natural but effective matches to the problem structure. However, joint training of the RL agent and transformer may require substantial data and compute—quantifying the training overhead and discussing deployment costs would strengthen the paper’s practical perspective.