Title: CEIO: A Cache-Efficient Network I/O Architecture for NIC-CPU
Data Paths
Authors: Bowen Liu, Xinyang Huang, Qijing Li (Hong Kong University of Science and Technology); Zhuobin Huang (University of Electronic Science and Technology of China); Yijun Sun, Wenxue Li, Junxue Zhang (University of Science and Technology of China); Ping Yin (Inspur Cloud); Kai Chen (Hong Kong University of Science and Technology)

Introduction
An efficient I/O data path between NICs and CPUs/DRAM is critical for datacenter applications with high-performance network transfers. However, conventional I/O accelerators such as Data Direct I/O (DDIO) and Remote Direct Memory Access (RDMA) often underperform due to inefficient last-level cache (LLC) utilization. To mitigate LLC misses, prior efforts explore two directions: limiting the I/O rate and limiting the I/O capacity. The former (represented by HostCC and its RDMA variant RHCC) reactively throttles NIC DMA upon detecting I/O congestion signals to reduce LLC contention; the latter (represented by ShRing) aggregates all I/O buffers into a shared ring sized below the LLC to eliminate cache misses. In practice, directly applying these approaches suffers from slow response and packet loss, leading to suboptimal performance.
This paper introduces CEIO, a cache-efficient network I/O architecture that combines proactive rate control with elastic buffering to optimize LLC efficiency while preserving the benefits of DDIO and RDMA across diverse network conditions. CEIO is implemented on commodity SmartNICs and integrated with widely used DPDK and RDMA libraries.
Key Idea and Contribution
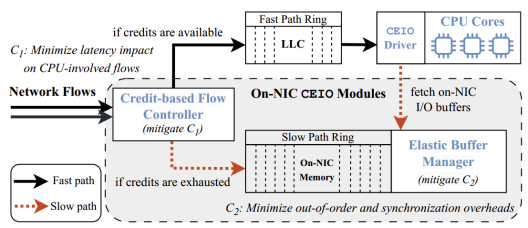
The core of CEIO is “proactive flow control + elastic buffering”: by proactively limiting ingress and buffering overflow on the NIC, CEIO keeps in-flight data within the LLC’s effective capacity and stabilizes performance under various network conditions.
- Proactive, Credit-based Flow Control. When a packet arrives at the NIC, it consumes a credit before initiating DMA. The total number of credits corresponds to the LLC capacity; packets that obtain credits follow the legacy I/O process (fast path), while others are buffered in on-NIC memory (slow path). Credits are replenished once packets are processed. This proactively limits the I/O rate before LLC misses occur, and a credit-based flow controller on the NIC manages the process.
- Elastic buffering. Elastic buffering is a receiver-side, in-place retention for excess arrivals: when a flow is demoted due to insufficient credits, its newly arriving packets are first buffered in on-NIC memory (slow path). To avoid reordering across paths, once a flow is demoted, its fast path is paused; the system first drains the slow-path backlog via DMA into host memory and then resumes the fast path. To reduce synchronous stalls while waiting for DMA, , CEIO driver will issue DMA read requests for slow path packets while the application processes fast path packets asynchronously, so that on the next poll the application can read the data directly from host memory.
Evaluation
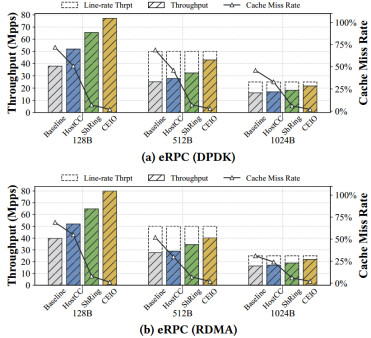
Under eRPC workloads, CEIO improves throughput and reduces tail latency compared to baselines. For example, experiments show up to 2.9× throughput speedup under network bursts, alongside notable P99/P99.9 latency reductions across DPDK- and RDMA-based data paths.
Q&A
Q1: For elastic buffering, you use on-board DRAM. DRAM is expensive and slower, why not use on-chip SRAM instead?
A1: The goal of elastic buffering is to absorb bursts first and wait for the rate limiter to take effect. It is a backup mechanism for the end-to-end system; we do not want to rely on DRAM because DRAM is much slower than SRAM. But this is an implementation issue for us: on BlueField-3 SmartNIC, we can only attach DRAM space rather than on-chip memory. On other platforms, if software can control SRAM space, I think the performance would be much better.
Q2:How do users use the driver in a real system?
A2: We expose a receive API. The driver is not a kernel module; it’s a userspace library. Similar to a DPDK-based stack, we provide several APIs, with the receive API being the primary one. In practice, a user replaces the DPDK or socket receive call with our API.
Personal Thoughts
The authors combine rate limiting and capacity limiting to propose CEIO, an LLC-friendly I/O architecture that delivers near line-rate throughput with µs-scale latency while coexisting with DDIO/RDMA, which is highly valuable in high-bandwidth network settings. A natural next step is to explore whether CEIO can be co-optimized with application-level memory allocation/placement.