Title : Centralium: A Hybrid Route-Planning Framework for Large-Scale Data Center Network Migrations
Authors : Yikai Lin, Mohab Gawish, Shih-Hao Tseng (Meta); Lixin Gao (UMass); Cen Zhao, John Tracey, Sunyi Shao, Hyojeong Kim, Ying Zhang (Meta)
Introduction
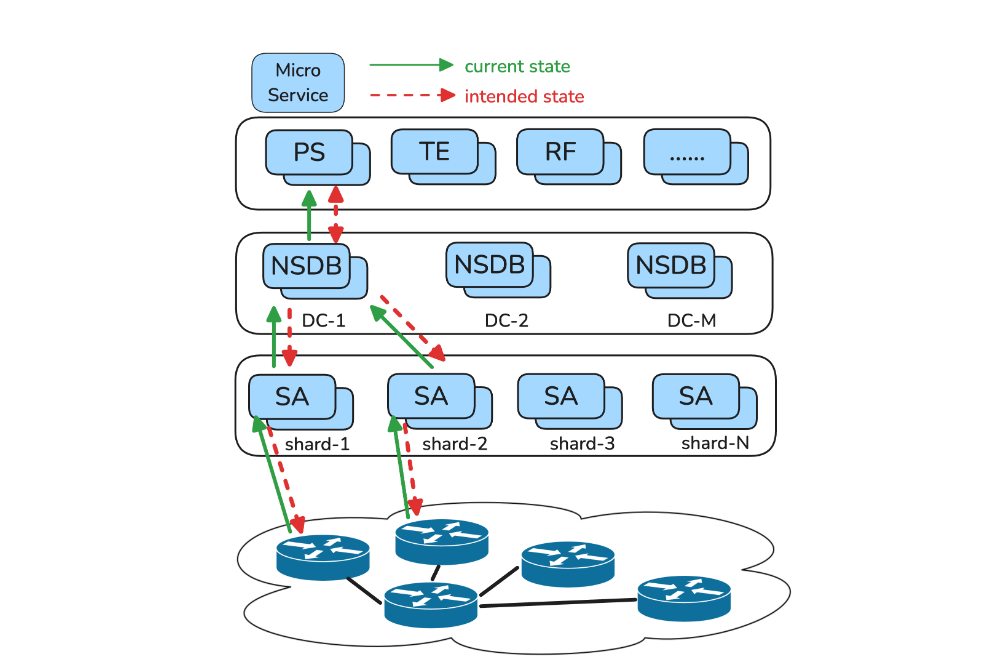
This paper addresses the challenge of executing large-scale migrations in data center networks. To support business growth, such networks require frequent hardware upgrades and topological evolution. However, the widely deployed Border Gateway Protocol (BGP), as a purely distributed protocol, exhibits fundamental limitations when supporting complex migration processes. Specifically, BGP cannot encode the sequential and conditional routing logic required for intermediate migration steps , which can lead to problems such as traffic funneling, transient loops, and forwarding resource exhaustion. This paper proposes Centralium, a hybrid route-planning framework that enhances BGP with centralized control capabilities to resolve these challenges.

Key idea and contribution :
The authors built Centralium, a hybrid routing system that combines centralized planning with distributed enforcement to manage complex network migrations. The key idea is a novel Route Planning Abstraction (RPA), which integrates a policy module into the BGP daemon to allow operators to directly prescribe high-level routing intent. The paper’s main contributions are threefold. First, it provides a comprehensive analysis of the operational challenges of using BGP for data center migrations, supported by production data. Second, it introduces the design of the Route Planning Abstraction (RPA) and the Centralium system architecture that uses RPAs for safe, sequenced deployment. Third, it demonstrates the effectiveness of Centralium through its application in over ten migration scenarios in Meta’s production network.
Evaluation
Centralium has been deployed at scale in Meta’s data centers for four years, where it manages hundreds of thousands of switches with minimal controller overhead—CPU usage remains below 25% and memory well under 3 GB. Measurements show that generating and deploying Route Planning Abstractions (RPAs) is extremely fast, typically under 200 milliseconds for a full data center and often less than one millisecond per update. Operationally, the system has delivered dramatic improvements: complex migrations that once required months of carefully sequenced steps can now be completed in a fraction of the time—for instance, one scaling migration was reduced from 9 steps over 189 days to just 3 steps in 21 days. Centralium also improves network efficiency through near-optimal traffic engineering, unlocking up to 45% more maintenance opportunities that would otherwise be blocked by service-level agreement concerns. These results matter because they demonstrate that a hybrid approach can make critical infrastructure operations safer, faster, and more reliable in practice, offering a proven path for evolving massive production networks without sacrificing resiliency.
Q&A
Q1: You mentioned that Meta operates many interconnected data centers. Does Meta have applications that need to run across multiple data centers? Could you share some specific types of applications? I
A1: Yes, AI training is a typical example. Our data centers are usually deployed in clusters organized by Metros, which naturally generates a significant amount of cross–data center server-to-server traffic, either for storage or for internal application communication.
Q2: What technical challenges have you encountered in supporting these applications?
A2: Load imbalance would be one. To address this, we rely on traffic engineering and some centralized solutions, since BGP itself has inherent limitations. Of course, there are other challenges as well, but the details would be better suited for offline discussion.
Q3: Do you think that the same approach can also be used to other network tasks?
A3: Yes. The concept of RPA can be applied to other cases. I think it is generally a powerful abstraction that allows you to control a distributed protocol stack, etc…
Personal thoughts
This paper’s hybrid approach is highly pragmatic. Instead of advocating for a complete replacement of BGP with a fully centralized SDN controller, the authors chose to augment the existing, battle-tested protocol. This makes the solution far more practical to deploy in a massive, live production environment, as it preserves the inherent scalability and fault tolerance of BGP’s distributed nature while introducing centralized programmability where it is most needed—during complex migrations.