Title: DistTrain: Addressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models
Authors: Zili Zhang, Yinmin Zhong (School ofComputer Science, Peking University); Yimin Jiang (Independent Researcher); Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Daxin Jiang (StepFun); Xin Jin (School ofComputer Science, Peking University)
Scribe : Wenyun Xu (Xiamen University)

Introduction
Multimodal Large Language Models (LLMs) have emerged to combine the strengths of LLMs with traditional multimodal models, allowing them to process diverse inputs like text, images, and audio, and generate multimodal outputs in an auto-regressive manner. However, training these models introduces unique system challenges due to model heterogeneity and data heterogeneity. Model heterogeneity arises because the different modules (encoder, LLM backbone, and generator) vary dramatically in size and computational demands, which leads to severe pipeline bubbles and poor GPU utilization in monolithic training frameworks like Megatron-LM. Data heterogeneity is caused by the significant differences in volume and processing costs between various data types (e.g., a high-resolution image versus a line of text), which creates training stragglers that prolong the training duration.
Key idea and contribution:
The authors propose DistTrain, a disaggregated training system for multimodal LLMs, which uses two novel disaggregation techniques to address model and data heterogeneity.
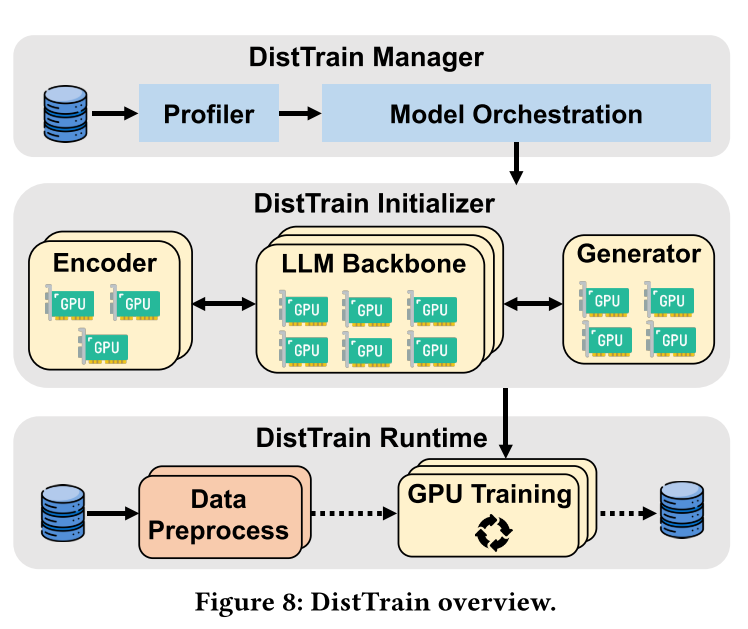
- Disaggregated model orchestration: This technique separates the training of the modality encoder, LLM backbone, and modality generator. This allows each component to independently and adaptively orchestrate its resources and parallelism configurations, such as tensor and data parallelism. By doing so, DistTrain can minimize pipeline bubbles and achieve optimal training efficiency.
- Disaggregated data preprocessing: This technique decouples data preprocessing from the training process. This not only eliminates resource contention between the two tasks but also enables efficient data reordering. DistTrain uses both intra-microbatch reordering (to evenly distribute load across data parallelism groups) and inter-microbatch reordering (to hide training stragglers).
Evaluation
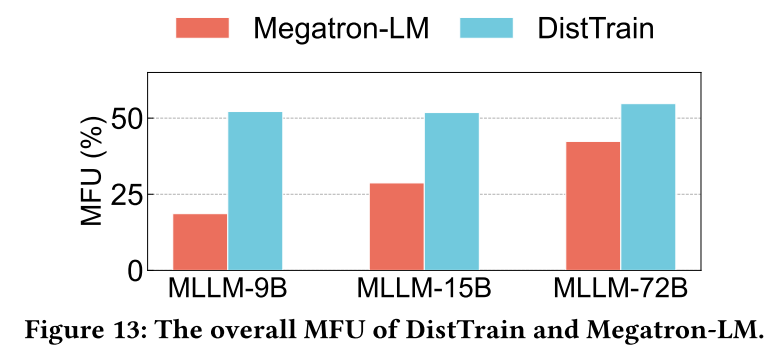
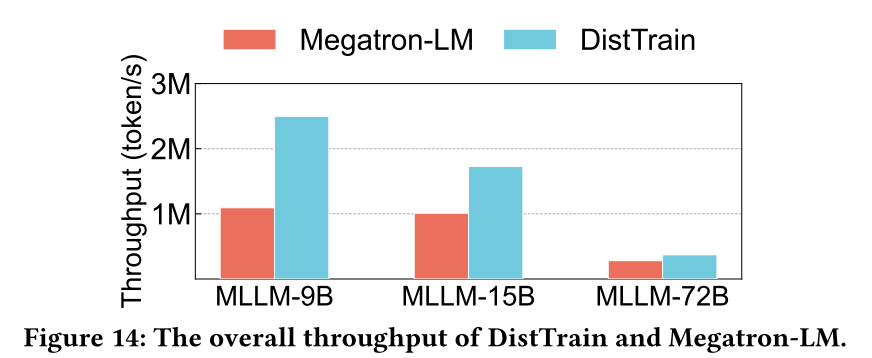
The authors evaluated DistTrain on a large-scale production cluster with a 72B multimodal LLM on 1172 GPUs. The results show that DistTrain achieves 54.7% Model FLOPs Utilization (MFU) and outperforms Megatron-LM by up to 2.2x on training throughput. This result is significant because it demonstrates a substantial improvement in resource utilization and training speed for large-scale multimodal LLMs, which are critical factors for reducing the time and cost associated with developing state-of-the-art models.
Q:When we set up the system, is the model’s optimal pipelining configuration static, or can it be dynamic during the training?
A: This is dynamic, but before training you can set up a static training purism which is really optimal.
Q: So I think the main contribution of your work is to designing an algorithm to accommodate the pipelining strategy for different combination of the multi-model training, right?
A: Sure, I think the main contribution is to dissociate the different modules with different architectures.
Q:It seems to me that the very essence of the work lies in the estimation of computational workload for different data chunks within or across batches. Given that you’ve said it’s possible to pre-configure an almost optimal static pipeline, could you please comment on the predictability of this computational workload?
A:Regarding predictability, if given a fixed benchmark of data and a fixed model, the configuration is static and predictable most of the time. However, in production-level deployment, the data is dynamic. Therefore, in DistTrain, we have dynamic data reordering online to address the dynamism in online training.
Q: So you still have to kind of anticipate?
A: Yes. The pipeline bubble is inevitable.
Personal thoughts
I really like that DistTrain tackles the problem of training multimodal LLMs from a systems perspective, rather than just a model-centric one. It provides a practical and effective solution to the core system-level challenges of heterogeneity. The dual-level disaggregation is a clever approach that addresses the two main bottlenecks—model and data imbalance—simultaneously. A potential open question for future work is how to further extend this disaggregation. The paper mentions the possibility of using heterogeneous hardware for different modules (e.g., cheaper GPUs for the encoder). This could lead to even greater cost-efficiency, which is a major consideration for large-scale training.