Title: DNSLogzip: A Novel Approach to Fast and High-Ratio Compression for DNS Logs
Authors
Yunwei Dai (Southeast University; Jiangsu Future Networks Innovation Institute); Guyue Liu (Peking University); Tao Huang (Southeast University; State Key Laboratory of Networking and Switching Technology, BUPT, China; Purple Mountain Laboratories); Shuo Wang (State Key Laboratory of Networking and Switching Technology, BUPT, China; Purple Mountain Laboratories); Yong Wang, Xingli Wu (Jiangsu Zhiwang Technology Co., Ltd.); Lei Song, Heshun Li, Chuang Wang (China Mobile Communications Group Shandong Co., Ltd.); Fanglong Hu (China Telecom Co., Ltd.); Hong Sun, Yanan Li (China United Network Communications Corporation Jiangsu Branch)
Scribe: Rulan Yang (Xiamen University)

Introduction
The Domain Name System (DNS) is a critical component of the Internet, and DNS logs are widely used for security monitoring, traffic analysis, and regulatory compliance. Rapid growth in Internet traffic has caused DNS log volumes to increase dramatically, creating significant storage challenges. Existing approaches primarily rely on general-purpose compression algorithms, which fail to leverage the unique characteristics of DNS logs, such as skewed domain lookup distributions and repetitive query patterns, thereby limiting their effectiveness. To address these limitations, this work proposes a DNS-aware compression method that leverages both inter-line and intra-line log patterns. The approach significantly improves compression ratios while maintaining lossless reconstruction, offering a practical and efficient solution for managing large-scale DNS log data in real-world deployments.
Key idea and contribution:
The key insight is that DNS logs contain significant redundancies, both across lines and within individual lines, and exploiting these patterns enables effective lossless compression. Building on this observation, the authors conduct an empirical analysis of real DNS logs and identify four key inter-line and intra-line features that help reduce redundancy without losing information. Guided by these insights, DNSLogzip is designed with a modular compression architecture, which supports diverse log formats and allows flexible integration and customization.
The features they observed are:
(1) The DNS caching mechanism ensures that queries sent to the same resolver for the same domain name and record type are more likely to return identical lookup results.
(2) The DNS tree structure [35, 36], as shown in Figure 7, determines that most domain names in the DNS system share common suffixes.
(3) On the Internet, most DNS queries are Type A and can get normal lookup results, meaning that QType is 1 and RCode is 0 in most cases.
(4) Letters in DNS are case-insensitive, resulting in logs that primarily contain numbers and lowercase letters.
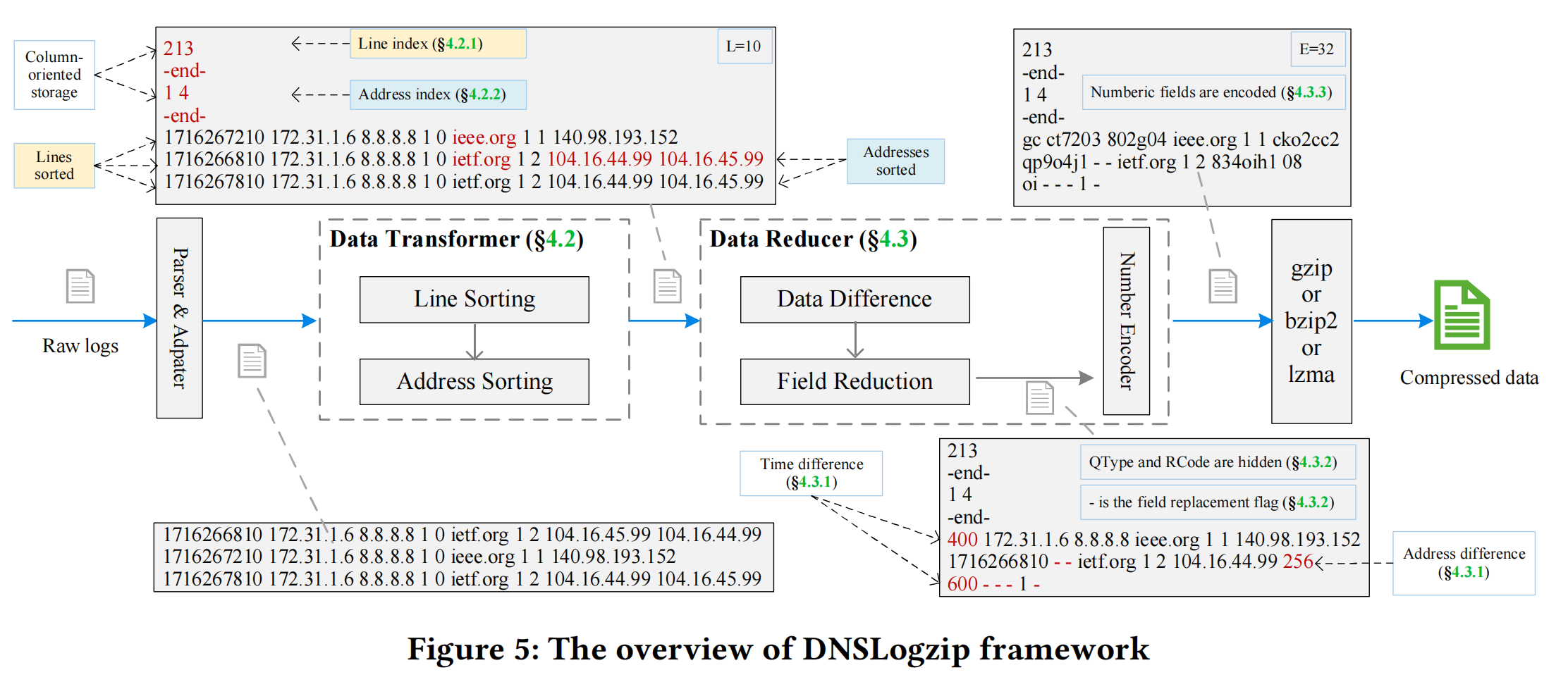
The DNSLogzip framework compresses DNS logs by exploiting their unique characteristics. The Parser & Adapter splits log files into chunks and parses fields. The Data Transformer enhances text similarity using inter- and intra-line features, while the Data Reducer reduces chunk size through differencing, hiding, replacing, and encoding. Finally, a general-purpose compressor produces the compact output.
Evaluation
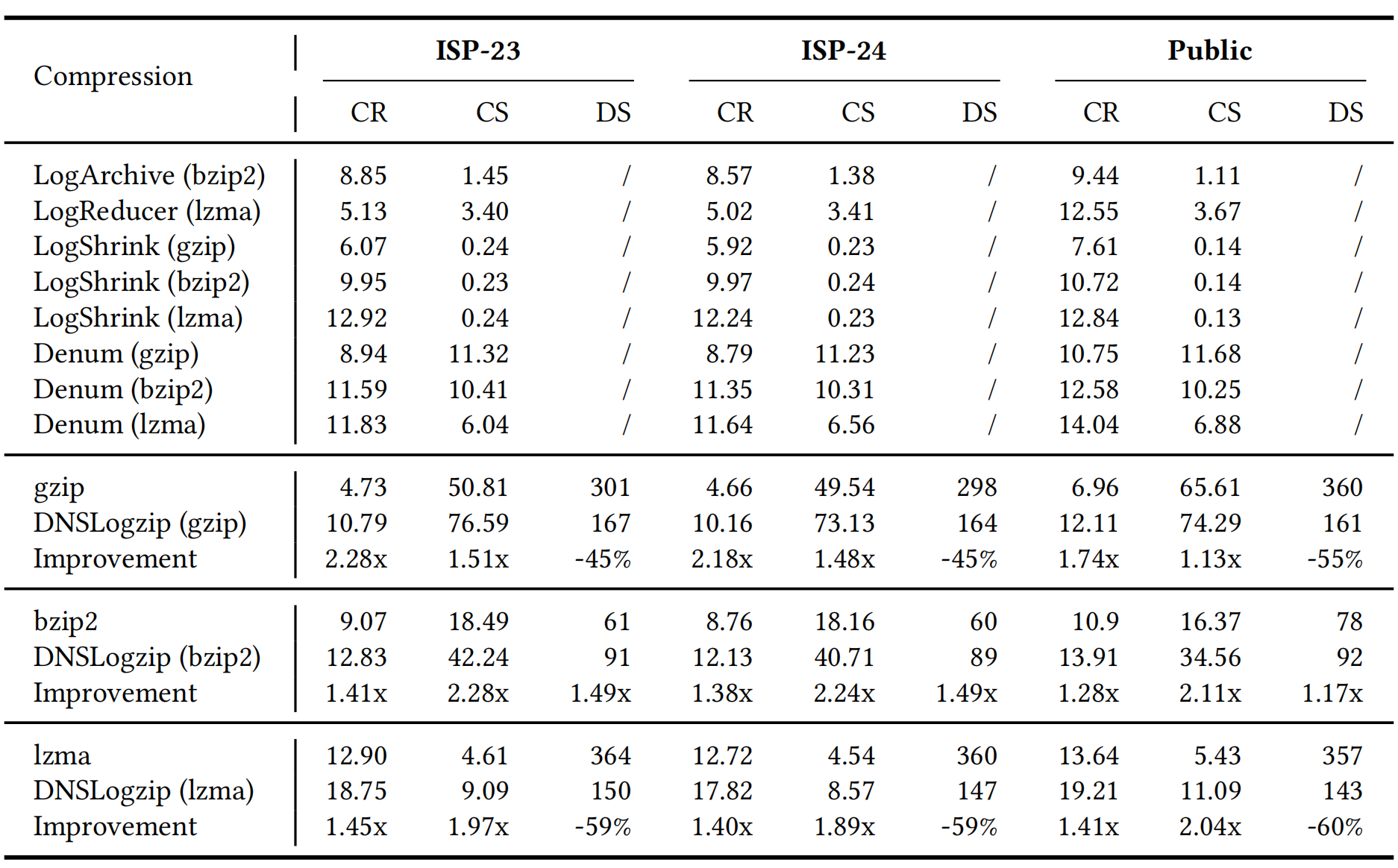
Results show that DNSLogzip achieves consistently higher compression speeds than both general-purpose and domain-specific compressors, reaching up to 1.51× faster than gzip and over 500× faster than LogShrink. Its decompression speed remains above 160 MB/s across datasets, confirming practical applicability. Checksum verification demonstrates that DNSLogzip is fully lossless.
Q&A
This paper is being presented on behalf of the authors, and there will be no Q&A session.
Personal thoughts
DNSLogzip presents an innovative DNS log compression method, leveraging domain hierarchies, query patterns, and address continuity to improve similarity and compression ratios. Its modular design, multi-field sorting, field hiding, and number encoding enable efficient, low-overhead processing, while concurrency ensures scalability. Potential issues include dependence on specific log formats, added complexity from address sorting and indexing, and field-hiding assumptions that may fail for unusual QTypes or RCodes. Future work could explore adaptive parsing for diverse logs, real-time streaming support, and applying similar techniques to other structured network logs to enhance robustness and generality.