Falcon: A Reliable, Low Latency Hardware Transport
Authors: Arjun Singhvi, Nandita Dukkipati, Prashant Chandra, Hassan M. G. Wassel, Naveen Kr. Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Montazeri, Neelesh Bansod, Sarin Thomas, Inho Cho, Hyojeong Lee Seibert, Baijun Wu, Rui Yang, Yuliang Li, Kai Huang, Qianwen Yin, Abhishek Agarwal, Srinivas Vaduvatha, Weihuang Wang, Masoud Moshref, Tao Ji, David Wetherall, and Amin Vahdat (Google LLC)
Scribe: Mingyuan Song(Xiamen University)
Introduction: The Need for a General-Purpose Hardware Transport
Context: The Performance Demands of Modern Datacenters
Modern datacenter workloads, spanning high-performance computing (HPC), large-scale artificial intelligence and machine learning (AI/ML), and real-time analytics, impose extreme demands on network performance. These applications require a combination of high bandwidth, low latency, and high message operation rates to function efficiently. Furthermore, this performance must be delivered with minimal host CPU consumption, freeing valuable compute cycles for the applications themselves. Hardware-accelerated transports, which offload the transport datapath to dedicated logic on the Network Interface Card (NIC), are uniquely capable of meeting these stringent requirements. The performance gap is substantial; the Falcon transport, for instance, demonstrates a 5x higher operation rate and 10x lower tail latency compared to Pony Express, a highly optimized software transport stack, immediately establishing the significant advantage of hardware offload.
The Core Problem: The Brittleness of RoCE
Despite the promise of hardware acceleration, existing transports—most notably RDMA over Converged Ethernet (RoCE)—are ill-suited for general-purpose, large-scale datacenter deployments. RoCE’s design inherits fundamental limitations from its origins in lossless InfiniBand networks, making it fragile and inefficient in standard, lossy Ethernet environments. This unsuitability stems from three critical flaws:
- Ineffective Loss Recovery: RoCE’s primary loss recovery mechanism, originally Go-Back-N and later augmented with a restricted form of Selective Repeat (SR), performs poorly in the presence of packet loss. Because RoCE NICs lack significant on-chip packet buffering, a receiver is forced to drop any packets that arrive out of order following a loss. This prevents the receiver from precisely signaling which specific packets are missing (as is done with Selective Acknowledgements, or SACK), leading to slow, imprecise, and often excessive retransmissions that cripple throughput.
- Lack of Native Multipathing: The RoCE protocol has no intrinsic support for multipathing. While datacenter networks are rich with multiple paths, leveraging them with switch-level mechanisms like Adaptive Routing creates significant packet reordering. RoCE misinterprets this reordering as packet loss, triggering spurious retransmissions and degrading performance. This fundamental conflict forces RoCE deployments to rely on Priority Flow Control (PFC) to create a lossless fabric, an operationally complex and often problematic solution.
- Decoupled Congestion Control: RoCE’s congestion control is implemented as an add-on, relying on out-of-band probe packets to gather congestion signals. This separation from the main datapath results in a sluggish and imprecise response to dynamic network congestion, failing to provide the rapid feedback needed for stable, high-performance operation.
Falcon’s Proposition
Falcon is introduced as a direct solution to these challenges. It is the first hardware transport architected from the ground up to deliver reliable, high performance in general-purpose, lossy Ethernet datacenter networks without requiring specialized switch features like PFC or Adaptive Routing.The design philosophy behind Falcon represents a strategic choice to embed transport intelligence at the network endpoints (the NICs) rather than relying on a complex, managed network fabric. This “smart endpoint, simple network” approach is a cornerstone of hyperscale infrastructure, enabling massive scale and operational simplicity with commodity hardware. This principle is reinforced by the design goal of having “minimal requirements on… in network support,” as stated during the Q&A session. Falcon aims to merge the raw performance of hardware offload with the proven robustness and generality of advanced software transport principles.
Key Idea and Contribution: A Holistic, Multi-Layered Design
Falcon’s architecture is a cohesive system where each component is designed to address specific shortcomings of prior art. Its innovations are not isolated features but deeply integrated mechanisms that work in concert to achieve robust, high performance.
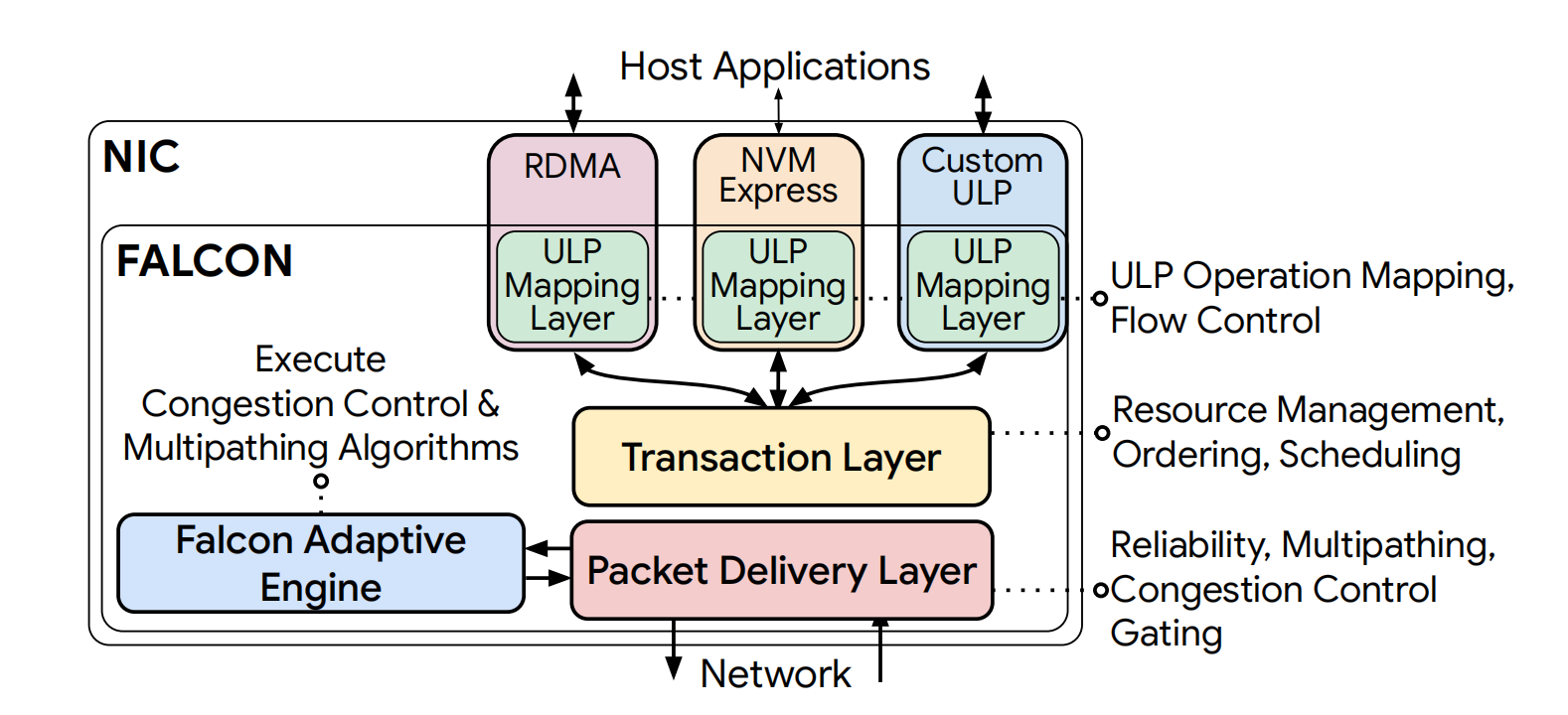
1. Layered Design with a Multi-ULP Transaction Interface
Falcon’s architecture is modular, with a clear separation of concerns into distinct layers: a ULP Mapping Layer, a Transaction Layer (TL), and a Packet Delivery Layer (PDL). This layered approach is a core design principle that manages hardware complexity and promotes extensibility.
At the heart of its multi-protocol capability is a simple yet powerful request-response transaction interface. Upper Layer Protocols (ULPs) like IB Verbs and NVMe map their operations onto two fundamental Falcon transaction types: Push transactions, where the requester sends data (e.g., an RDMA Write), and Pull transactions, where the requester receives data (e.g., an RDMA Read). This abstraction allows Falcon to provide transport services to standard protocols without needing to implement their full semantics in hardware, which significantly reduces feature duplication and simplifies the NIC design.
To support legacy applications that depend on strict ordering, Falcon provides flexible ordering semantics. Each connection can be configured as ordered or unordered. Crucially, ordering is managed by a Request Sequence Number (RSN), which is distinct from the Packet Sequence Number (PSN) used for reliability. This decoupling allows Falcon to use transport mechanisms like multipathing, which naturally reorder packets at the PSN level, while still delivering transactions in the correct order at the RSN level to the ULP.
2. Delay-Based Congestion Control and Congestion-Aware Multipathing
Falcon integrates a sophisticated congestion control and multipathing system, drawing inspiration from proven software transports but implementing the mechanisms in hardware for line-rate performance.
- Delay-Based Congestion Control: Falcon adopts a delay-based algorithm similar to Swift. It uses precise, hardware-generated timestamps on each packet to measure per-packet Round-Trip Times (RTTs). This provides a fine-grained and immediate signal of network congestion without requiring explicit feedback from switches (like ECN or INT), aligning with the goal of operating over commodity networks. The design uniquely manages two separate congestion windows: an
fcwndfor network fabric congestion and anncwndfor NIC/host congestion. Thencwndis modulated by monitoring the receiver’s on-NIC buffer occupancy, a signal piggybacked on ACKs, which prevents the receiver NIC itself from becoming a performance bottleneck. - Congestion-Aware Multipathing: Multipathing is a first-class feature in Falcon, not an afterthought. A single Falcon connection can be striped across multiple network paths, where each path is treated as a “flow” identified by a unique IPv6 Flow Label. Switches use this label in their ECMP/WCMP hashing to direct flows along different physical paths. The key innovation is that path selection is congestion-aware. The hardware scheduler tracks the congestion state of each flow and, for each outgoing packet, assigns it to the flow with the largest available congestion window. This mechanism naturally and dynamically biases traffic towards less congested paths, providing a form of just-in-time, fine-grained load balancing that minimizes latency and maximizes throughput.
This design creates a powerful synergy between reliability, congestion control, and multipathing. In RoCE, these features are often in conflict, as the reordering from multipathing breaks the fragile loss recovery. Falcon, by contrast, creates a virtuous cycle. First, its robust, SACK-based reliability with on-NIC buffering makes the transport inherently tolerant to packet reordering. This reordering tolerance, in turn, enables the use of aggressive multipathing. The per-flow state tracking required for multipathing then provides fine-grained, path-specific delay signals. Finally, these precise signals feed back into the delay-based congestion control algorithm, allowing it to manage the sending rate of each path with high precision. No single feature would be as effective in isolation; their tight, co-designed integration is a cornerstone of Falcon’s performance.
3. Hardware-Based Reliability and Error Handling
To overcome the fragility of RoCE, Falcon implements a robust, state-of-the-art reliability layer entirely in hardware. The foundation of this system is the use of on-chip buffers at the receiver to absorb and hold out-of-order packets. This is a fundamental departure from RoCE and a prerequisite for any advanced loss recovery scheme.
Falcon employs a bitmap-based Selective Acknowledgment (SACK) mechanism. The receiver maintains a bitmap of received packets, which is piggybacked on acknowledgment packets. This allows the receiver to precisely communicate to the sender which packets have been received and which are missing, all within a single RTT, enabling fast and efficient retransmission of only the lost data.
Furthermore, Falcon adapts the RACK-TLP (Recent Acknowledgment - Tail Loss Probe) algorithm for its hardware datapath. RACK uses timers to differentiate between packet reordering and actual packet loss, preventing the sender from spuriously retransmitting packets that are simply delayed on a different path. TLP helps to quickly detect and recover from losses at the end of a transmission burst (tail losses), which are notoriously difficult for ACK-based mechanisms to handle. This combination ensures Falcon performs reliably even under the high degree of reordering induced by its own multipathing system.
4. Systematic On-NIC Resource Management
A key challenge in hardware design is managing finite on-chip resources. Falcon’s design explicitly addresses this to prevent deadlocks and performance cliffs under scale and stress. It employs two primary strategies:
- Resource Carving: On-NIC resources, such as state contexts and packet buffers, are logically partitioned into dedicated pools. Resources are carved between transmit (Tx) and receive (Rx) paths, between requests and responses, and for head-of-line (HoL) packets. This strict separation prevents one class of traffic from starving another, ensuring that the protocol can always make forward progress. For example, dedicating a pool for responses guarantees that a flood of incoming requests cannot prevent outgoing responses from being sent, which would lead to deadlock.
- Dynamic Backpressure and Isolation: Falcon provides isolation between connections to prevent a single “slow” connection (e.g., one experiencing heavy congestion or communicating with a slow application) from monopolizing NIC resources and impacting other connections. It monitors the resource usage of each connection. If a connection exceeds its dynamic threshold, Falcon exerts per-connection backpressure via an Xon/Xoff interface to the ULP, temporarily halting new transaction submissions from that connection. The thresholds are not static; they are calculated dynamically by the Falcon Adaptive Engine based on congestion signals, ensuring that connections making slow progress are allocated fewer resources, thus preserving fairness and overall system performance.
5. The Falcon Adaptive Engine (FAE): A Programmable HW/SW Co-Design
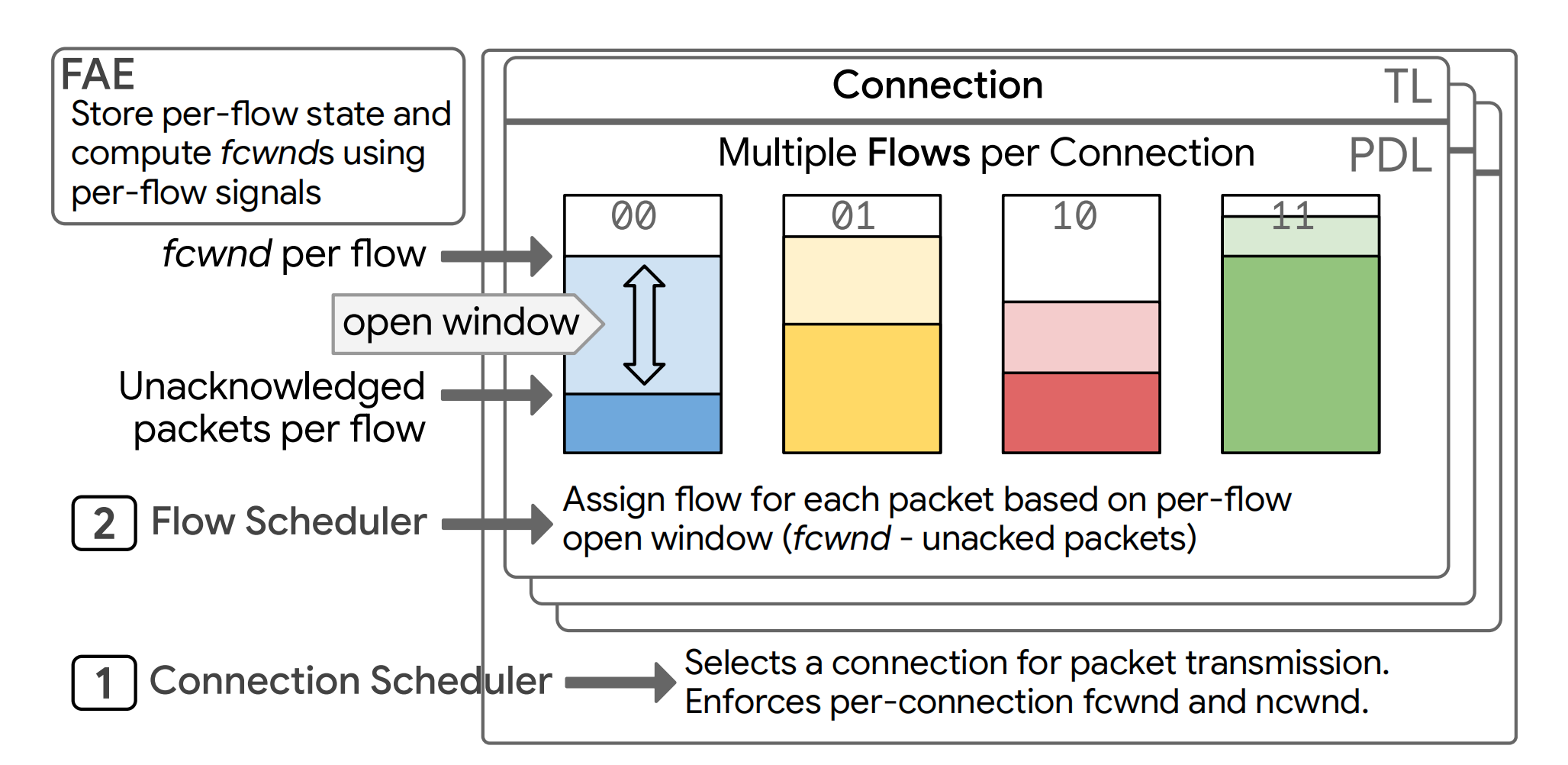
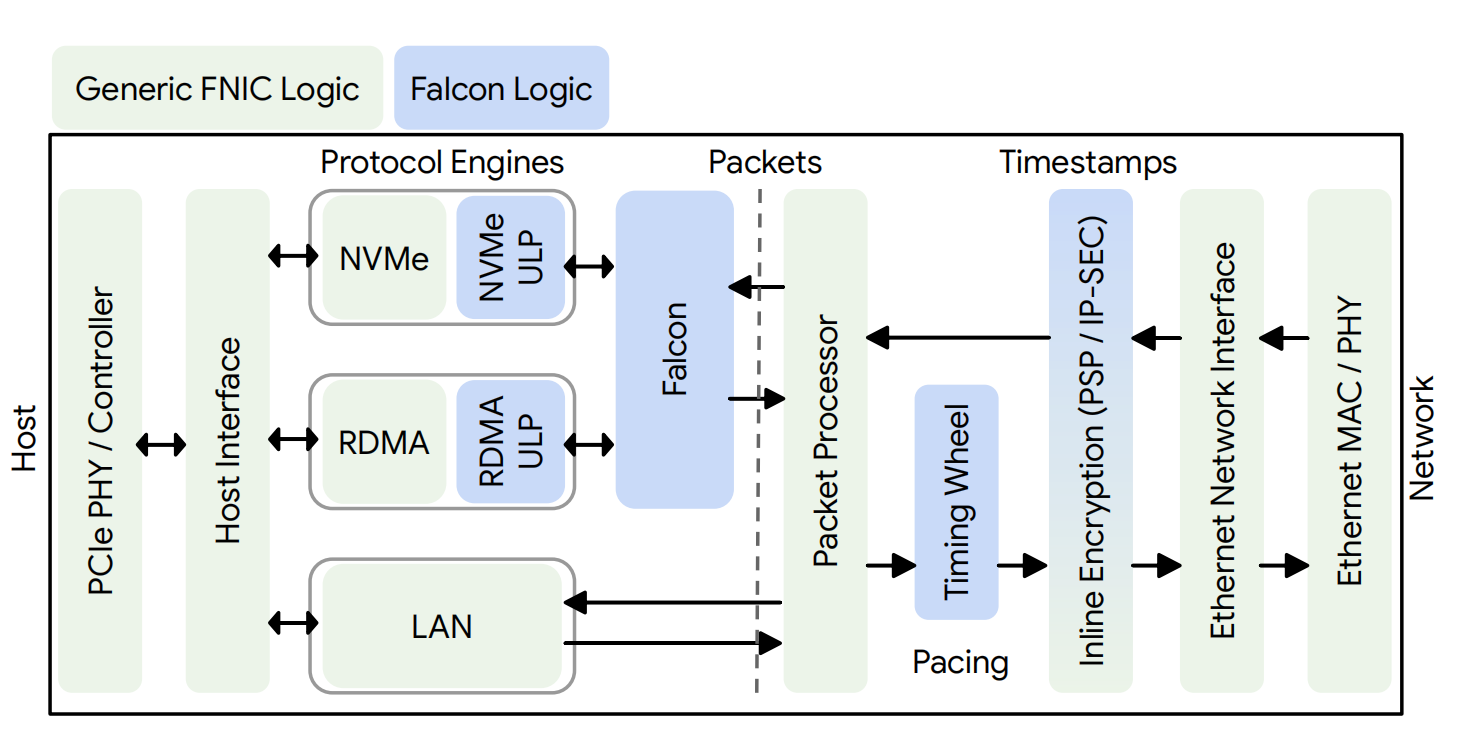
Perhaps Falcon’s most forward-looking feature is the Falcon Adaptive Engine (FAE), which embodies a hardware/software co-design philosophy. This architecture partitions transport functionality:
- Hardware (PDL): The high-speed, per-packet datapath functions—such as packet parsing, timestamping, window enforcement, pacing via a Timing Wheel, and ACK processing—are implemented in fixed-function hardware for line-rate performance.
- Software (FAE): The more complex, less frequent control-plane logic—such as the congestion control algorithm itself, multipath routing decisions, and the calculation of retransmission timeouts—runs as software on a general-purpose CPU core integrated into the NIC.
This split provides the best of both worlds: the raw performance of an ASIC datapath and the flexibility and programmability of software. Congestion control algorithms can be updated, tuned, or even completely replaced with a simple software update, eliminating the multi-year cycle of a hardware respin. This directly addresses a major historical limitation of hardware offloads, which have been notoriously rigid and difficult to evolve. The FAE makes Falcon adaptable and future-proof.
| Feature | Hardware Mechanism (PDL) | Interface Signals | Software (FAE) Tasks |
|---|---|---|---|
| Reliability, Loss Recovery | ACK Bitmap, RACK, TLP | Timestamps, Rx Buffer Level | Compute RTO, RACK timeout, TLP threshold |
| Congestion/Flow Control | Sliding Windows, Pacing | #hops, ECN, RTO, CSIG | Compute fcwnd, ncwnd, IPG, target delay scaling |
| Multipathing, PLB, PRR | Path-aware flow scheduler | Flow Labels | Flow Label (re)assignment and per-flow CC tasks |
| Isolation | Dynamic Thresholds | Resource Occupancy | Compute DT alpha based on dynamic factors |
| ACK Generation | Ack Request Bit in Header | Ack Request Rate | Decide when/how to set the AR bit |
Table adapted from Table 3 in the source paper to illustrate the HW/SW division of responsibilities in Falcon.
Evaluation: Empirical Validation of Falcon’s Design
The paper’s evaluation systematically validates Falcon’s design principles through a series of microbenchmarks and real-world application tests. The primary testbed consisted of 32 machines with 200 Gbps Falcon NICs and 400 Gbps NVIDIA CX-7 RoCE NICs. A validated simulator was used to evaluate features not yet available in the 200G hardware, such as RACK-TLP and advanced multipathing.
Protocol Performance: Falcon vs. RoCE Under Stress
The evaluation’s core theme is demonstrating Falcon’s robustness in non-ideal, real-world conditions where traditional hardware transports falter.
- Loss Recovery: Under random packet loss, Falcon’s goodput remains stable and near line-rate, while RoCE’s performance (both Go-Back-N and Selective Repeat variants) collapses, dropping by up to 3.4x. Falcon outperforms RoCE’s best-case SR by up to 65%. This result directly validates the effectiveness of Falcon’s SACK/RACK-TLP design and the critical role of its on-NIC buffering.
- Reordering Tolerance: When subjected to network-induced packet reordering, Falcon’s performance is unaffected, whereas RoCE’s goodput plummets by 5%-52% (for SR) and up to 20x (for GBN) due to spurious retransmissions. This highlights the ability of the RACK heuristic to correctly distinguish packet reordering from actual loss, a crucial capability for enabling multipathing.
- Congestion Handling:
- Fabric Incast: In a many-to-one incast scenario, Falcon maintains near-optimal median and average latencies, with a p99 latency only ~2x the ideal. In contrast, RoCE suffers from significantly higher tail latency and a 13% loss in total goodput. This demonstrates the fast, precise response of Falcon’s delay-based congestion control.
- End-Host Congestion: When a receiver’s PCIe link is artificially bottlenecked, Falcon’s
ncwndmechanism enables it to rapidly converge to the new bottleneck rate. RoCE’s response is far more sluggish, taking twice as long to adapt down and 6x longer to ramp back up once the bottleneck is removed. This confirms the value of explicitly signaling end-host backpressure in the transport protocol.
Multipathing and Hardware Scalability
The evaluation confirms that Falcon’s architectural choices translate to excellent scalability and performance benefits from its advanced features.
- Multipathing Benefits: Simulations demonstrate that Falcon’s congestion-aware multipathing delivers up to 180x lower operation latency and sustains 50% higher network load (sustaining up to 90% of fabric capacity versus only 60% for single-path). When applied to ML training workloads, this translates into a communication time reduction of up to 30% and an overall training runtime improvement of 5%.
- Op-Rate and Bandwidth Scaling: Falcon meets its hardware performance targets, scaling to a peak of 120 Mops/sec with as few as 12 QPs for small messages. At high bandwidths, it achieves two orders of magnitude lower latency than a state-of-the-art software transport.
- Avoiding the “Connection Cliff”: A critical scalability test shows that as the number of active connections exceeds the NIC’s on-chip cache size, Falcon’s latency increases gracefully. In contrast, the CX-7 RoCE NIC experiences a sharp ~3x latency spike. This validates the design of Falcon’s connection state caching and memory system, which is crucial for predictable performance in large-scale environments.
- FAE Scalability: The FAE software, running on a single on-NIC ARM core, is shown to be highly scalable. Using prefetching techniques, it can process a stable 20 million events per second, far exceeding the measured peak of 8 M-events/sec in real-world applications. The transport’s performance remains robust even when artificial delays are introduced into the FAE’s response time, demonstrating resilience to transient processing slowdowns.
Real-World Application Impact
The evaluation culminates by demonstrating that Falcon’s protocol-level and hardware-level advantages translate directly into significant end-to-end performance gains for a diverse range of real-world applications.
- HPC/MPI: For MPI collectives, RDMA-over-Falcon is up to 5.5x faster than TCP for a 64KB AllReduce and 4.3x faster for small-message AllToAll operations. HPC applications like GROMACS (molecular dynamics) and WRF (weather forecasting) scale to more nodes and run up to 2.4x and 32% faster, respectively, compared to running over TCP.
- Disaggregated Storage (NLF): When used for Near Local Flash (NLF), NVMe-over-Falcon delivers bandwidth and IOPS performance within 10% of a locally attached SSD, proving its efficacy for high-performance storage disaggregation.
- Virtualization (VM Live Migration): Compared to a high-performance software transport (Pony Express), Falcon accelerates the critical post-copy phase of VM live migration by 2.5x. This results in a 3x higher memory access rate for the guest VM and a 6x reduction in vCPU stall time during migration, significantly reducing the performance impact on the live-migrated application.
The consistent theme across the evaluation is not just that Falcon is faster in ideal conditions, but that it excels precisely where other systems break down: under loss, reordering, incast congestion, host bottlenecks, and high connection counts. This robustness translates directly into predictable, high performance for real applications, which is paramount for operators of large-scale systems.
Q&A Session: Design Rationale and Future Context
The Q&A session provided further context on Falcon’s design choices and its position within the evolving landscape of network transports.
Q1: Why delay-based congestion control over telemetry-based (e.g., HPCC/Bolt)?
A: The primary design goal was to minimize reliance on in-network switch support, as advanced telemetry features are not universally available across all datacenter fabrics. Falcon was designed to work well on commodity networks. However, the programmable nature of the FAE means that Falcon could be adapted to use telemetry-based algorithms in the future if the network provides the necessary signals.
Q2: Will Falcon and similar transports like UET replace TCP for general-purpose networking?
A: There is significant potential for RDMA-based transports to replace TCP, especially within and across datacenters, due to their inherent low-latency and CPU efficiency benefits. Falcon is designed with the scalability needed for this role and is part of a broader industry trend toward wider RDMA adoption.
Q3: Does Falcon require synchronized clocks?
A: No, it does not. Falcon uses a four-timestamp method involving the sender and receiver to calculate RTT accurately without requiring synchronized clocks. However, if synchronized clocks are available, the FAE could be programmed to leverage them for more precise one-way delay measurements, potentially further improving the congestion control response.
Q4: Was Falcon evaluated for AI/ML training workloads?
A: Yes, the paper includes evaluation results for ML models (Figure 18), and the performance benefits demonstrated are applicable to that domain.
Q5: How does Falcon compare to Ultra Ethernet (UET)?
A: Falcon is specifically designed for general-purpose datacenter applications, with a strong focus on backward compatibility for “lift and shift” customers using the standard IB Verbs API. This was a key requirement. UET, on the other hand, does not prioritize this legacy support. While there are similarities in some underlying mechanisms (e.g., both use a SACK-based loss recovery approach), their target use cases and application interfaces differ significantly.
Personal Thoughts: A New Benchmark for Hardware Transports
Strengths
- A Paradigm Shift for General-Purpose Transports: Falcon’s most significant contribution is that it successfully breaks the long-standing trade-off between hardware performance and protocol robustness. It delivers the low latency and high message rates of RDMA over standard, commodity Ethernet, a goal that has largely eluded previous attempts like RoCE. By treating reliability and congestion control as integral, co-designed components rather than afterthoughts, Falcon establishes a new standard for what a general-purpose hardware transport should be.
- The Power of the Falcon Adaptive Engine (FAE): The HW/SW co-design embodied by the FAE is a landmark innovation in NIC architecture. It directly solves the classic problem of hardware ossification, where transport logic, once etched in silicon, is nearly impossible to change. By moving the control-plane policy (the “what to do”) into software on the NIC while keeping the datapath mechanism (the “how to do it fast”) in hardware, Falcon becomes adaptable, tunable, and future-proof. This architecture is likely to serve as a blueprint for the next generation of programmable NICs and Infrastructure Processing Units (IPUs).
- Holistic, Systems-Oriented Design: The work excels because it is not a point solution but a complete, end-to-end system. Every component—from the ULP interface down to the on-NIC resource manager and the packet scheduler—is designed to work in concert. The breadth of the evaluation, which covers everything from protocol microbenchmarks under stress to the performance of full-scale, real-world applications, is a testament to this holistic approach and its success.
Limitations and Future Directions
- Complexity and Programmability Model: While the FAE is immensely powerful, the paper does not detail its programming model. Key questions remain regarding the developer experience: How difficult is it to develop, debug, and safely deploy new algorithms on the FAE? The potential for subtle bugs in this privileged, on-NIC software could have significant performance and security implications. Future work should explore the development toolchains and safety mechanisms required to make such a powerful platform truly usable and robust.
- Applicability Beyond the Datacenter: Falcon’s design is heavily optimized for the datacenter environment, characterized by RTTs in the tens of microseconds and specific traffic patterns. Its reliance on on-NIC buffering (sized according to the bandwidth-delay product) and its delay-based congestion control algorithm might require significant tuning or adaptation to perform well over wide-area networks (WANs), which have much larger, more variable RTTs and different packet loss characteristics.
- The Evolving Landscape (UET): The Q&A touches upon the Ultra Ethernet Consortium (UEC) and its UET transport. While Falcon’s strength lies in its general-purpose nature and backward compatibility with IB Verbs, specialized transports like UET are being co-designed from a clean slate specifically for AI/HPC workloads. By shedding the constraints of legacy APIs, UET may achieve even higher performance for those targeted applications. A deep competitive analysis between these two philosophies—general-purpose compatibility versus workload-specific optimization—will be a key area of future research.
Conclusion
Falcon is a landmark paper that sets a new standard for hardware transport design. By masterfully integrating proven principles from software transports into a flexible and performant hardware architecture, it provides a robust, scalable, and general-purpose solution for the immense demands of modern datacenters. It effectively closes the chapter on the limitations of first-generation RDMA-over-Ethernet protocols and opens a new one centered on programmable, reliable, and highly efficient hardware acceleration for all workloads.