Title:Firefly: Scalable, Ultra-Accurate Clock Synchronization for Datacenters.
Authors: Pooria Namyar, Yuliang Li, Weitao Wang, Nandita Dukkipati, KK Yap, Junzhi Gong, Chen Chen, Peixuan Gao, Devdeep Ray, Gautam Kumar, Yidan Ma, Ramesh Govindan, Amin Vahdat (Google LLC).

Introduction
This paper targets sub-10 ns device-to-device clock synchronization in datacenters while also keeping devices within ≲1 µs of UTC—requirements driven by cloud-hosted financial exchanges where nanosecond-level timestamp fairness matters. Existing techniques (NTP/PTP/mesh/tree designs) struggle at scale due to clock drift, queuing-induced jitter, and forward/reverse path asymmetries; they also rely on a reference clock or specialized hardware, making them brittle or costly. Firefly reframes the problem as fast, scalable, software-driven consensus on commodity Ethernet, explicitly handling jitter/asymmetry and decoupling internal (device-to-device) from external (UTC) sync.
Key idea and contribution
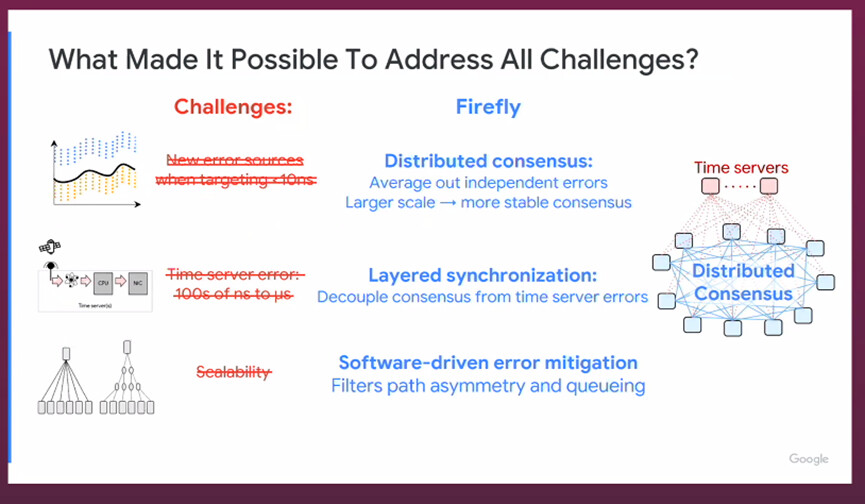
Firefly’s core idea is distributed clock averaging over a random overlay graph plus layered synchronization. Instead of steering everyone toward a single reference, each NIC periodically probes a small, random set of peers and iteratively averages offsets/drifts; theory shows random graphs converge quickly and, with degree d=O(log N), preserve accuracy as the network grows. On top, Firefly separates a fast, internal “swarm virtual clock” (SVC) consensus from a slower, smoothed convergence to UTC, which makes the system resilient to noisy/misbehaving time servers while keeping ultra-tight relative ordering between machines.
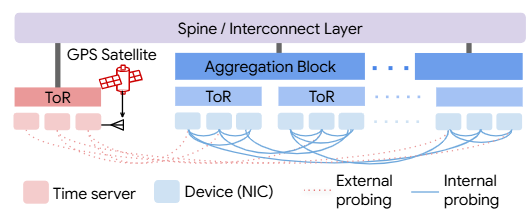

To make this practical on commodity networks, Firefly adds system techniques to tame measurement error: regression-based drift estimation; truncated-mean outlier rejection; RTT filtering and/or Transparent Clock to suppress queuing jitter; and active path profiling to lock onto minimally asymmetric ECMP paths. Together, these let consensus average out residual noise/asymmetry without specialized optics.
Evaluation
On a 248-NIC, six-hop Clos testbed, Firefly achieves p99 ≈ 10 ns internal (NIC-to-NIC) and ≤1 µs external (NIC-to-UTC) accuracy, and outperforms a PTP Boundary-Clock chain even though Firefly runs at larger scale. The design is robust to oscillator drift, high traffic (with TC/RTT filtering), and large time-server jitter/faults thanks to the layered architecture. This result is significant because it shows cloud-grade, software-only sub-10 ns synchronization—previously the domain of specialized hardware—is feasible and scalable on commodity Ethernet.
Q&A
Q1: Your accuracy — how does it depend on link latency? Specifically, could a similar solution work in cellular networks requiring base station sync, or in multi-region networks with long inter-link latency? Or does it only work under certain latency conditions?
A1: Accuracy does not directly depend on link latency, since offset calculation relies solely on four timestamps, independent of network delay. Current evaluation was done within a data center (e.g., a six-hop Jupiter network). Cross-data-center or cross-region (e.g., East Coast to West Coast) deployment is our next step, but introduces new challenges like higher jitter and packet loss.
Q2: You used “exchange” as a motivation example, but your evaluation seems limited to a single data center. Are there limitations when applying this to exchange scenarios where different entities own their own network segments and you don’t control the entire infrastructure? What if multiple entities, each owning part of the network, try to synchronize clocks?
A2: In typical exchange setups, participants connect to a common network and get time sync from a single provider — that’s standard practice. If multiple entities don’t trust each other and run different protocols, it’s indeed challenging. This is a great question — how to ensure fair and accurate synchronization in a competitive multi-entity environment deserves further exploration.
Q3: Beyond financial transactions, what other potential uses do you envision for such precise synchronization within data center infrastructure — e.g., for consistent/lossless updates, state synchronization, accurate one-way delay measurement?
A3: Definitely. We anticipate broader infrastructure use: 1) Building next-gen financial exchanges (eliminating need for expensive custom fabrics like EtherCAT); 2) In ML, pre-scheduling traffic to avoid congestion/packet loss and achieve high performance; 3) Rethinking database design — especially concurrency control protocols, which currently assume inaccurate clocks; high-precision sync enables a paradigm shift in how we design systems.
Personal thoughts
I like the clean separation of concerns: fast peer-to-peer consensus (SVC) for relative order, then gentle percolation toward UTC to absorb time-server noise. The random-graph viewpoint is compelling—it gives both a convergence argument and a practical knob (degree $d$) with logarithmic scaling. The system tricks (RTT filtering, TC, path profiling) are pragmatic and clearly motivated by real error sources.
Two things I’d watch next: (1) Systemic first-hop asymmetry (NIC↔ToR optics) remains a limiting floor; it would be interesting to see commodity-friendly calibration or redundant-path tricks to cancel this component. (2) Beyond a single DC: a WAN-level hierarchy of “swarms” sounds promising but will run into higher jitter and routing asymmetry; adapting consensus and asymmetry correction across sites is an open, worthwhile direction for truly global sub-µs (or even ns-class) sync.