Title : From ATOP to ZCube: Automated Topology Optimization Pipeline and A Highly Cost-Effective Network Topology for Large Model Training
Authors : Zihan Yan, Dan Li (Tsinghua University); Li Chen (Zhongguancun Laboratory); Dian Xiong (Harnets.AI); Kaihui Gao (Zhongguancun Laboratory); Yiwei Zhang, Rui Yan (Tsinghua University); Menglei Zhang, Bochun Zhang, Zhuo Jiang, Jianxi Ye, Haibin Lin (ByteDance)
Introduction
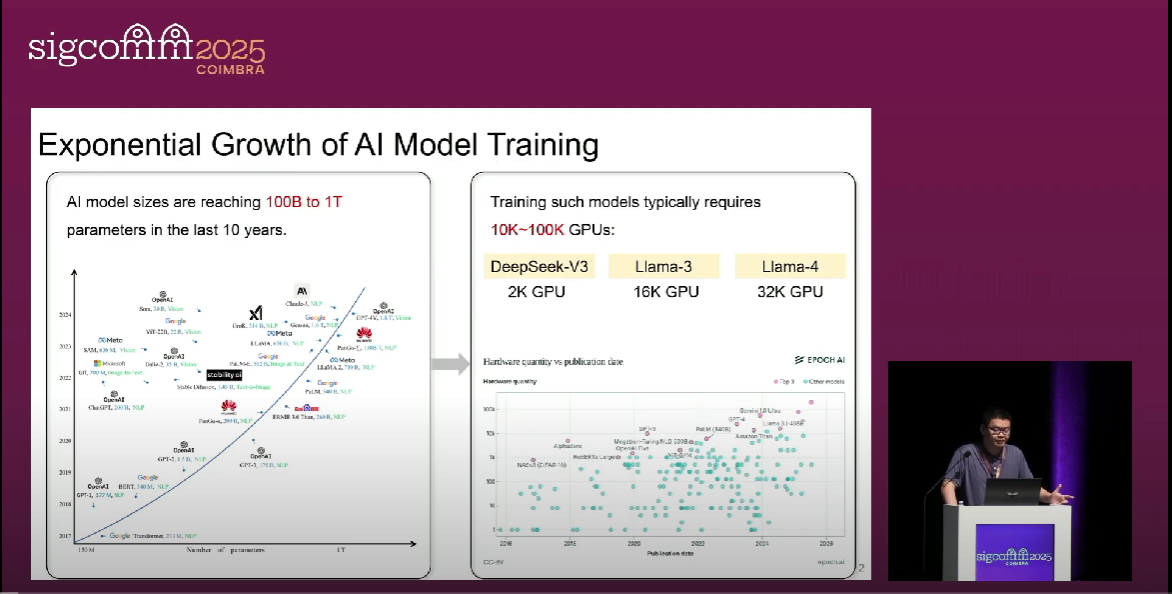
The problem studied is the design of network topologies for large-scale GPU clusters used in training large language models (LLMs). This is important and interesting because the scale of these clusters is growing exponentially (e.g., up to 24k GPUs), representing massive capital investments, and an efficient network is critical for performance. Existing systems fall short because current design processes rely on a limited set of well-known topologies (like ROFT, Rail-only, HPN) that are not cost-performance optimal. Manual design by experts struggles with the vast search space and human bias toward simple, symmetric designs, while previous automated methods are either computationally infeasible due to an enormous search space or cannot easily optimize for end-to-end application performance.
Key idea and contribution :
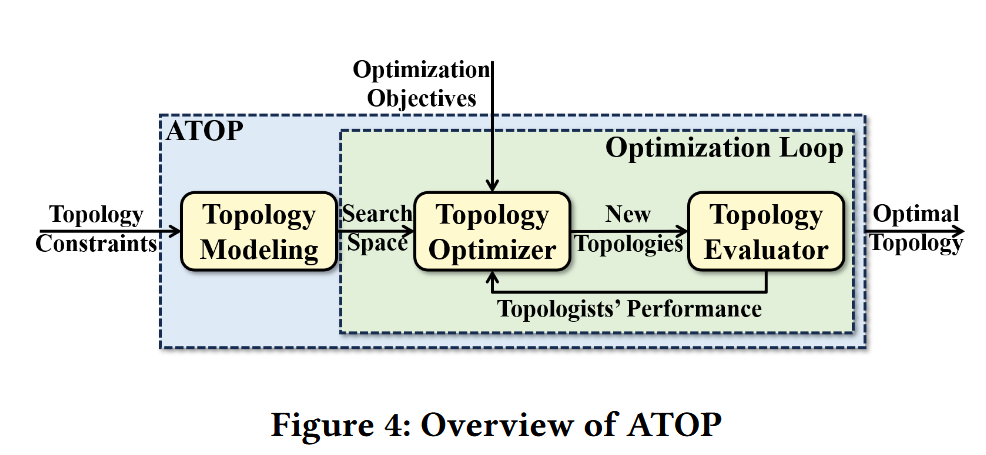
The authors built ATOP, an Automated Topology Optimization Pipeline, to systematically explore the topology design space. The key idea is to combine human intuition with automated search. ATOP models the topology design space using 11 types of searchable hyperparameters, which are distilled from the expert design principles of existing DCN and HPC topologies. This creates a large yet manageable search space that includes known topologies but can also generate novel, asymmetric ones. ATOP then uses a multi-objective evolutionary algorithm (NSGA-II) guided by a high-fidelity simulator to efficiently search this space, optimizing for user-defined goals like LLM training time, hardware cost, and fault tolerance.
The primary contribution is the discovery of a new topology, ZCube, which ATOP identified as the most cost-effective solution across various scales (from 256 to 16,384 GPUs). ZCube is a novel, asymmetric topology that exhibits a low network diameter, strong LLM training performance, robust fault tolerance, and superior cost-effectiveness compared to the state-of-the-art.
Evaluation
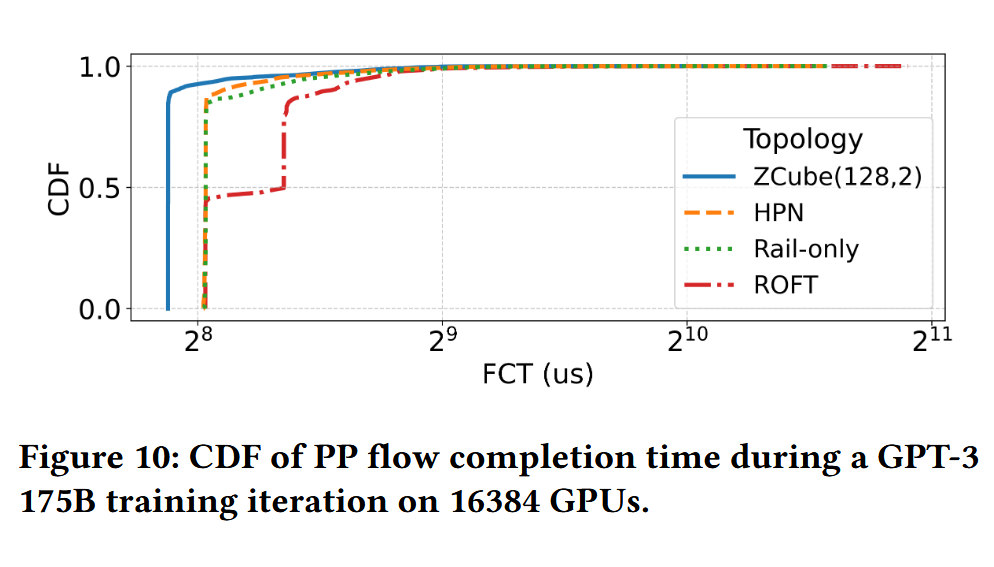
The evaluation was two-fold. First, the ATOP pipeline was validated across three practical scenarios: designing a new data center, adjusting an existing one, and expanding a cluster, demonstrating its versatility. Second, the discovered ZCube topology was extensively evaluated against state-of-the-art topologies like ROFT, Rail-only, and HPN. Simulation results for clusters up to 16,384 GPUs showed that ZCube improves end-to-end LLM training speed by 3% to 7% while reducing network hardware costs by 26% to 46%. Furthermore, a physical testbed with 16 GPUs was constructed, where ZCube achieved the same all-reduce and all-to-all performance as ROFT but with a 25% reduction in hardware cost. This result demonstrates that the conventional, human-centric approach to topology design overlooks more optimal, asymmetric solutions, and an automated pipeline like ATOP can systematically discover them. The resulting ZCube topology offers a direct path to building more powerful and economical large-scale AI clusters by simultaneously improving training performance and significantly cutting network hardware costs.
Q&A
Q1: The first question is edge density. I couldn’t tell is it worse or just similar to the topologies that you started with where it’s roughly the same number of edges but they’re connected in different ways. It was really hard to tell from thinking in my head.
A1: We first used the adjacency matrix, but we found it would result in a very large search space and we couldn’t discover a superior topology in a short time. So we proposed ATOP and introduced a new topology modeling method based on layered and symmetric structures. Thanks to these, we can use only tens of parameters to represent a topology. This is also a unified method, and we can use it to represent Fat-Tree, BCube, Dragonfly, DCell, and many other famous DC topologies.
Q2: The world is about gpus these days but why not just regular data center topology. Are we suggesting that maybe we should do away with the ones that we know about you and we should start using ZCube.
A2: We are trying to deploy ZCube. But a new topology is not easy to deploy, as almost every data center topology uses the Clos or Fat-Tree now.
Q3: Could this be applied in other domains that are nothing to do with computers?
Z3: As ZCube is designed for GPU clusters, it is a scale-out network topology. Maybe it can also be used in traditional data center networks, and maybe it can be applied in other domains as well.
Personal thoughts
This paper is impressive for its practical and systematic approach to a very relevant and expensive problem. What I like most is the core concept of ATOP: encoding domain knowledge into a searchable hyperparameter space. It’s a pragmatic and powerful way to blend expert insight with the brute-force capability of automated search, avoiding the pitfalls of both pure manual design and unconstrained brute-force exploration. The discovery of ZCube serves as a strong validation of this methodology, and the inclusion of a real-world testbed evaluation adds significant credibility to the results.