Title: Hattrick: Solving Multiclass TE using Neural Models
Speaker : Abd AlRhman AlQiam (Purdue University)
Scribe : Yuntao Zhao (Xiamen University)
Authors: Abd AlRhman AlQiam, Zhuocong Li (Purdue University); Satyajeet Singh Ahuja, Zhaodong Wang, Ying Zhang (Meta); Sanjay G. Rao, Bruno Ribeiro, Mohit Tawarmalani (Purdue University)
Introduction
The paper addresses the challenge of traffic engineering in wide-area networks that serve multiple classes of traffic with different priorities and requirements. Traditional optimization-based methods and recent ML approaches mostly focus on a single traffic class, which is unrealistic for production networks where diverse services coexist. Simple extensions, such as weighted losses in neural networks, fail to capture the sequential and hierarchical nature of multi-class optimization. This motivates the design of Hattrick, a machine learning framework for multi-class traffic engineering that seeks to achieve robust and efficient performance in realistic settings.
Key idea and contribution:
The paper proposes Hattrick, an ML-driven framework for multi-class TE, with the following key ideas and contributions:
-
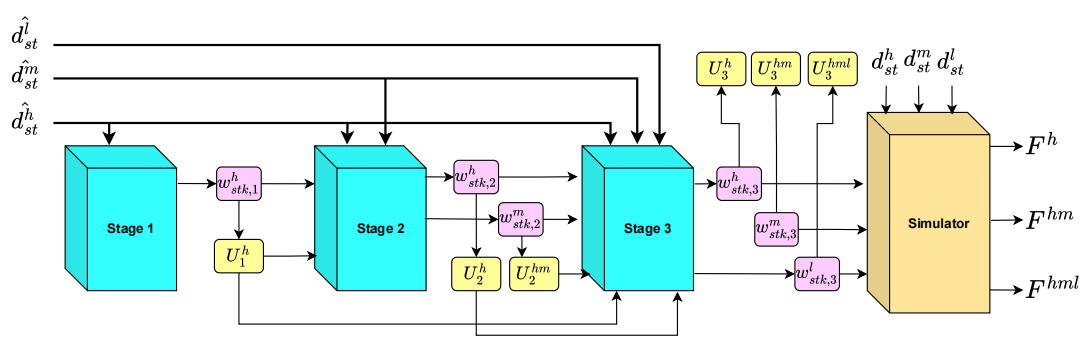
Multi-stage neural architecture – The paper introduces a novel multi-stage neural network architecture composed of recurrent units that sequentially optimize traffic classes in descending priority. Later stages can refine routing decisions made for higher-priority traffic in earlier stages, allowing more flexible accommodation of lower-priority traffic without compromising higher-priority performance. This design mirrors the stepwise optimization in classic multi-class TE schemes and offers significant advantages over conventional approaches that lack such fine-tuning of earlier decisions.
-
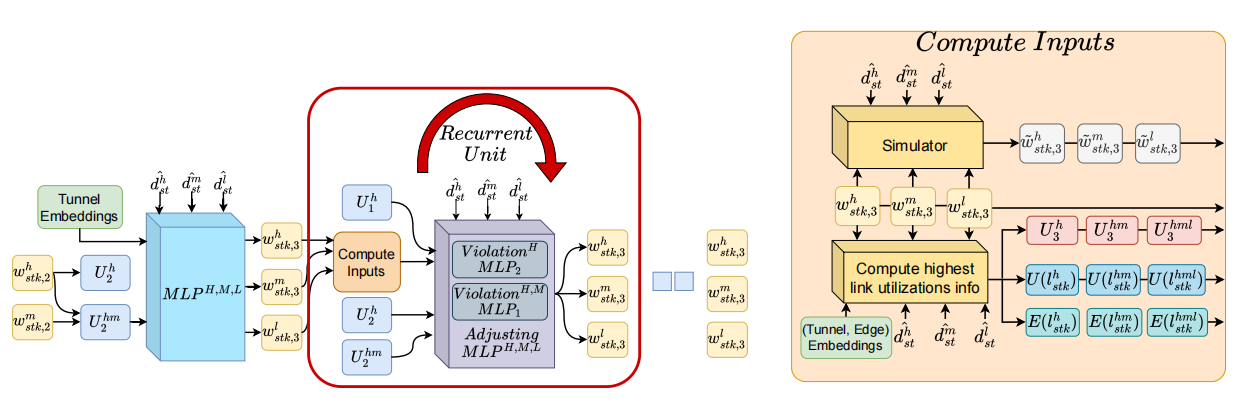
Robustness to prediction error – Hattrick explicitly prioritizes performance under traffic demand uncertainty. The paper integrates a differentiable, class-aware flow simulator into the training process to model the potential effects of traffic prediction errors (e.g. link under-utilization or capacity violations). By optimizing metrics that capture these detrimental effects, Hattrick improves the network’s robustness and reliability in the face of prediction uncertainty, a factor largely neglected by prior multi-class TE methods.
-
Precedence-aware multi-task learning – To handle multiple performance objectives across classes, the paper introduces a customized multi-task learning approach with a gradient projection technique. This ensures that learning updates for lower-priority traffic do not degrade the performance of higher-priority traffic, respecting the strict priority hierarchy. The approach effectively resolves conflicts between objectives and outperforms conventional multi-task learning baselines that assume equal task importance, providing a more efficient solution for multi-class TE.
Evaluation
Setup: Evaluated on real WAN traces and public topologies, compared against SWAN and BEST_MC.
- Superior Multi-Class Performance: Hattrick consistently outperforms the classical baselines in terms of how much traffic demand can be satisfied under real-world conditions. For example, on the GEANT network, Hattrick was able to carry 5.48% to 19.3% more traffic (depending on the class priority) compared to SWAN, when measuring the fraction of traffic delivered with 99% reliability. It even exceeded the performance of the optimized BEST_MC solution by up to 11.6% for certain classes.
- Robustness to Prediction Errors: The results demonstrate that Hattrick’s focus on prediction error pays off. Under varying traffic prediction scenarios (the paper tests multiple predictive models), Hattrick maintained high service levels for top-priority traffic and avoided severe drops for lower classes, whereas baselines showed more vulnerability when the input forecasts were inaccurate. An ablation study showed that removing the differentiable simulator or the special training adjustments led to worse outcomes, confirming that each design element (the multi-stage network and the gradient projection training) contributed significantly to these gains in robustness.
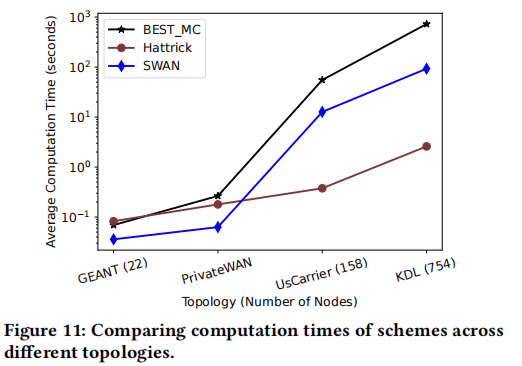
- Computational Efficiency: Apart from network performance, Hattrick also scales better. In experiments on very large topologies (hundreds of nodes and links), the trained model can compute routing decisions much faster than optimization solvers. For a test topology with 754 nodes, Hattrick achieved about 280× faster computation than the BEST_MC optimization approach and about 36× faster than SWAN’s heuristic, while still delivering better or comparable traffic allocation.
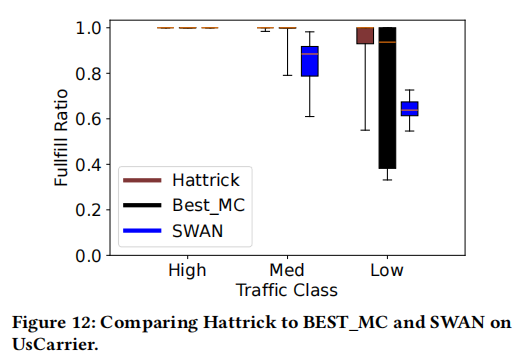
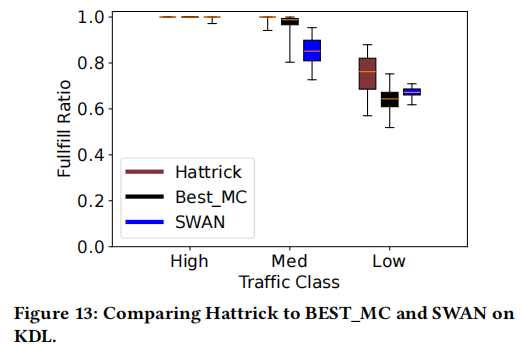
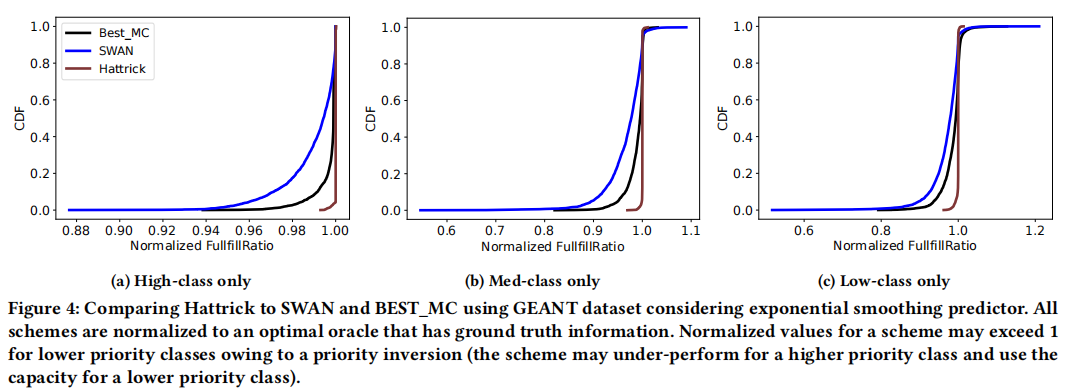
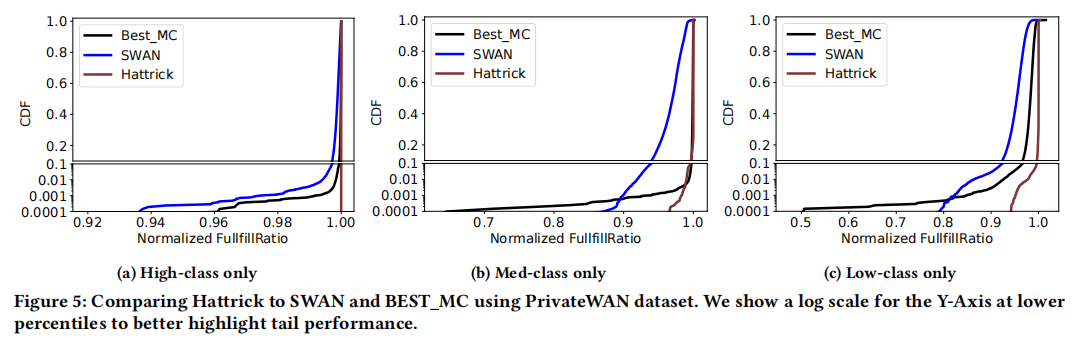
Q1: You compared Hattrick to SWAN. Since SWAN is a multi-objective optimizer that considers things like max-min fairness as well as the number of hardware routing table entries (e.g., HIB entries) on the switches, I’m curious—did you only compare against MLU, or did you also account for these other metrics that SWAN optimizes over?
A1: In our evaluation, we only focused on the maximum carried flow. We did not explicitly compare against SWAN’s other objectives like max-min fairness or hardware resource constraints.
Q2: Can you elaborate a little bit on the granularity of your control? Right, if the unexpected traffic is a burst of traffic, can your system handle that?
A2: Usually, things in TE are more coarse-grained. And I think, as far as I know from your background, it’s more in intra-DC where things are fine-grained, right? In TE, things are coarse-grained, where we think about traffic matrices instead of packets and bursts and this stuff.
Q3: Can your framework handle MLU minimization and other nonlinear objectives?
A3: In fact, MLU minimization, as I mentioned, is part of the optimization in Hattrick. This is mainly because, in some sense, we do not view maximum link utilization as orthogonal to max-flow, which I believe has been the assumption in all previous TE work. These are not orthogonal — in fact, the optimal solution for MLU, when MLU is less than one, is also optimal for max-flow. And we exploited that insight in our design.
Personal thoughts
Hattrick demonstrates a well-balanced integration of domain knowledge and machine learning. The multi-stage design captures the sequential nature of multi-class traffic engineering, while the differentiable simulator brings training closer to real-world conditions where prediction errors are unavoidable. The precedence-aware gradient method further ensures that the strict priority of high-class traffic is respected. These choices make the framework both principled and practical.
At the same time, the scope of evaluation is focused on three traffic classes and throughput-oriented objectives, leaving questions about how it generalizes to more diverse service requirements. In addition, although Hattrick is more robust to forecast errors than existing methods, its reliance on prediction quality is still a natural limitation. These aspects point to promising directions for future research rather than shortcomings. Overall, the paper provides strong evidence that carefully designed ML models can effectively address complex multi-class TE problems and serves as a valuable reference for both academic and practical development.