Title: Hermes: Enhancing Layer-7 Cloud Load Balancers with Userspace-Directed I/O Event Notification
Authors: Tian Pan, Enge Song, Yueshang Zuo, Shaokai Zhang, Yang Song, Jiangu Zhao, Wengang Hou, Jianyuan Lu, Xiaoqing Sun, Shize Zhang, Ye Yang (Alibaba Cloud); Jiao Zhang, Tao Huang (Purple Mountain Laboratories); Biao Lyu, Xing Li (Zhejiang University & Alibaba Cloud); Rong Wen, Zhigang Zong (Alibaba Cloud); Shunmin Zhu (Hangzhou Feitian Cloud & Alibaba Cloud)

Introduction
Layer-7 (L7) load balancers route traffic based on application-layer attributes (e.g., HTTP headers), improving performance, availability, and scalability in public clouds. In multi-tenant settings, each userspace worker must handle traffic from many tenants; effective load balancing across workers is therefore critical to maintain performance isolation. Current L7 implementations rely on kernel I/O event notification (e.g., epoll) to assign connections from the kernel to userspace workers.
However, existing epoll mechanisms lack visibility into workers’ runtime states: the kernel dispatches connections without knowing whether a userspace worker is overloaded. Early epoll designs suffered from thundering-herd effects; the epoll exclusive variant introduces LIFO wakeups that can concentrate connections on a few workers. Reuseport hashes connections to per-worker sockets but is susceptible to hash collisions and remains oblivious to worker load and health. Moreover, L7 workloads (e.g., encryption, compression, or simple copying) vary widely in computational complexity and request size, making it impossible for the kernel to estimate load from packet counts alone.
This paper presents Hermes, a userspace-directed I/O event notification framework that augments L7 load balancers. Hermes guides kernel-space connection scheduling using live worker-state signals from userspace and employs eBPF to non-invasively override Reuseport’s socket selection logic, enabling custom worker dispatch. Hermes has been deployed at Alibaba Cloud across O(100K) CPU cores and handles O(10M) RPS.
Key Idea and Contribution
1. Userspace-directed, closed-loop I/O event notification
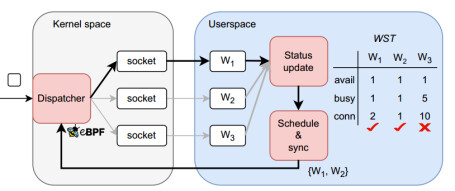
Hermes treats userspace worker state as the primary signal for connection scheduling and constructs a three-stage feedback loop spanning user and kernel space:
Stage 1: worker status update. Each userspace worker processes connections dispatched by the kernel and updates its runtime metrics (e.g., pending-event counts) in a shared-memory Worker State Table (WST) .
Stage 2: connection scheduling across workers. A userspace scheduler periodically reads the WST, computes a candidate set of workers eligible to accept new connections, and synchronizes this decision with the kernel.
Stage 3: connection dispatch in kernel space. Using an eBPF hook, the kernel applies custom scheduling over the candidate set and assigns each new connection to a chosen worker, then returns to stage (1).
2. Multi-process co-scheduling
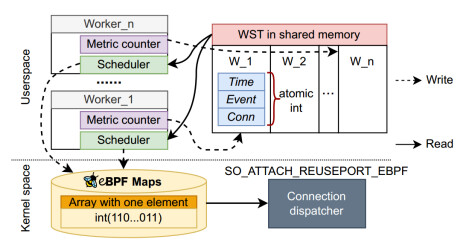
-
Lock-free shared-metrics design. Workers must update WST metrics while the scheduler scans the entire table to make global decisions, implying concurrent reads/writes. Hermes places the WST in shared memory and adopts a lock-free access pattern for performance. Memory is partitioned per worker so that updates to a worker’s own metrics do not interfere with others; thus, writers need no locks. The scheduler’s full-table scans proceed without read–write locks, tolerating minor, transient inconsistencies. Individual state variables use atomic to guarantee read/write atomicity.
-
Worker-driven distributed scheduling. To keep scheduling responsive and concurrent, Hermes uses short timeouts (e.g., epoll_wait() with ~5 ms), and allows multiple workers to run the scheduler logic in parallel, ensuring sufficiently frequent executions for accuracy. To avoid overload, Hermes employs two-stage filtering: the userspace scheduler first selects multiple available workers (coarse filtering) and passes this set to the kernel; the kernel then picks one worker for the incoming connection (fine filtering). If the coarse-filter set is too small, the kernel falls back to Reuseport. For compact communication of the candidate set from multiple schedulers, Hermes uses a bitmap (1 = available, 0 = unavailable).
Evaluation

Under production traffic, the authors compare epoll exclusive, Reuseport, and Hermes. The standard deviation (SD) of CPU utilization is 26%, 2.7%, and 2.7%, respectively; the SD of per-worker connection counts is 3200, 50, and 20, respectively. Hermes delivers the most balanced load, which in turn reduces CPU overload incidents and improves tenant-level performance isolation.
Q&A
Q: Which eBPF hook did you attach the program to? And during deployment, were there moments when you thought, ‘If eBPF could do X, it would make my life much easier?’”
A: At the SO_ATTACH_REUSEPORT_EBPF eBPF hook, we can inspect incoming TCP connections and the accept queues, so we perform connection dispatching there. We override the kernel’s default hash selection and instead choose the target worker socket via a BPF map that’s driven by user-space state. This lets us steer each connection to the most suitable worker and achieve better load balancing.
Personal Thoughts
Hermes targets imbalance rooted in kernel I/O notification by designing a worker-state-aware scheduling framework and using eBPF to add flexible kernel-side dispatch with minimal intrusion. To reconcile userspace–kernel synchronization, the paper proposes a set of practical strategies and optimizations. Many high-performance systems pursue kernel-bypass paths to avoid user/kernel transitions; building on that trend, it would be interesting to explore whether Hermes can evolve into a pure userspace scheduling framework with similar fidelity. In more complex multi-tenant environments, QoS- and fairness-aware scheduling policies also merit deeper investigation.