Title: Low-Overhead Distributed Application Observation with DeepTrace: Achieving Accurate Tracing in Production Systems
Authors: Yantao Geng, Han Zhang, Zhiheng Wu, Yahui Li, Jilong Wang (Institute for Network Sciences and Cyberspace, Tsinghua University); Xia Yin (Department of Computer Science and Technology, Tsinghua University)
Scribe: Xiaoqiang Zheng (Xiamen University)
Introduction
The paper studies the challenge of accurate and low-overhead distributed tracing in large-scale microservice systems. As modern online services shift from monolithic to microservice architectures, diagnosing failures and performance bottlenecks becomes increasingly complex. Existing non-intrusive tracing systems, though convenient, often fall short: FIFO-based approaches mis-associate requests under concurrency, while delay-based approaches incur high overhead and degrade in accuracy at scale. Addressing these limitations is important for maintaining reliable production systems and enabling efficient troubleshooting in highly concurrent cloud-native environments.
Key idea and contribution
The authors propose DeepTrace, a transaction-based, non-intrusive distributed tracing framework that leverages semantic information embedded in requests (e.g., API endpoints, transaction fields) alongside system-level signals to more reliably correlate parent-child relationships. Unlike FIFO- or delay-based systems, DeepTrace introduces three core innovations: (1) protocol-aware span construction using eBPF and protocol templates to support more than 20 common application protocols; (2) a transaction-based span association mechanism that exploits contextual features such as user IDs and API dependencies to improve correlation accuracy; and (3) query-driven trace assembling, which selectively gathers only spans relevant to operator queries, thereby greatly reducing transmission overhead. Together, these designs enable accurate, low-overhead tracing without requiring code instrumentation.
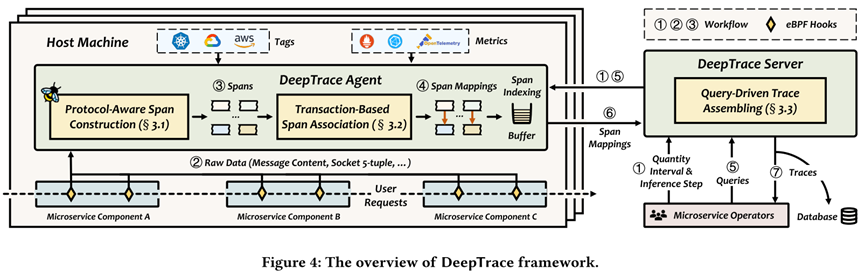
Evaluation
The authors evaluate DeepTrace both in production deployments and in a controlled testbed. The key findings are:
-
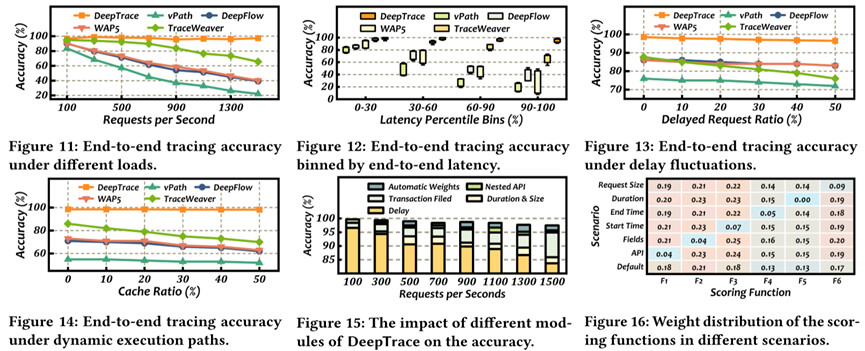
High tracing accuracy under concurrency : DeepTrace maintains over 95% accuracy even when request load reaches 1500 RPS, while FIFO-based and delay-based baselines drop below 40–63%.
-
Robustness against tail latency : DeepTrace achieves about 92% accuracy even in the top 10% tail-latency requests, whereas other methods fail in such cases.
-
Resilience to delay fluctuations and dynamic paths : When 50% of requests experience injected delays, TraceWeaver accuracy drops to 76%, but DeepTrace still maintains about 95% accuracy. Similarly, with caching-induced execution path changes, DeepTrace keeps 97% accuracy, far higher than baselines.
-
Efficiency in trace reconstruction : DeepTrace reconstructs 10,000 traces in ~40 seconds, more than 10× faster than TraceWeaver, while remaining close to FIFO-based methods.
-
Low transmission overhead : Its query-driven assembling reduces data transfer by up to 94%, requiring only 30–60 MB versus hundreds of MB to GB for other frameworks.
-
Negligible performance impact : DeepTrace reduces application throughput by only 4.6%, compared to ~24% degradation in Jaeger with full sampling.
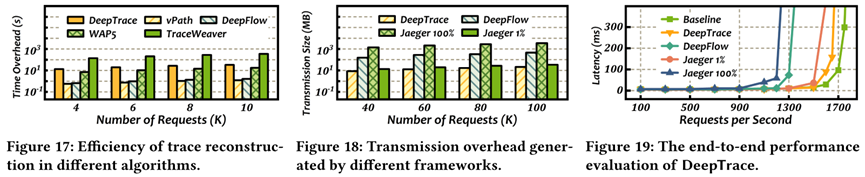
This result is significant because it demonstrates that accurate, efficient, and low-overhead tracing is feasible in real-world microservices, making DeepTrace highly practical for operators diagnosing failures and optimizing resource usage.
Q1: I worked with distributed tracing myself for quite some time. And although you showed the accuracy at the end, one of the challenges that we have with distributed tracing, at least the invasive version, is latency. It adds a little bit of latency. And one way to overcome the situation is using sampling. So sampling, of course, can bring some blind spots. But this is a trade-off. Otherwise, the latency in the requests increases with the amount of microservices that are involved. Do you have any other metrics that you measured apart from accuracy? And how did that compare with the other systems that you had as a comparison? Is latency in a non-invasive distributed tracing framework relevant, like it is in Jaeger, for example? Did you measure latency? Is this relevant in the framework that you built?
A1: Yes. When we perform the request authorization, you accept the transaction information, we also use latency and the duration metric, like a traceweber. In our emulations, we also emulate the latency performance of our framework, like the latency of a trace reconstruction and the end-to-end performance latency.
Q2: Hi. Thanks for the talk. It’s an interesting technique to use contents of the requests to try to correlate between the requests. Are there applications where the content is obfuscated in some way where it would be hard to use this approach? Thank you.
A2: It’s a good question. The content is not always useful because the persistent transition file is not always used in the request content. So, to solve this problem, we also use causality-related metric to the success of parent-child relationship. This is done by traceweber and we pass this works in past. But this is not my main focus. Thank you.
Personal thoughts
I find the paper’s main strength lies in bridging the gap between accuracy and non-intrusiveness. By combining semantic content analysis with protocol-aware parsing, DeepTrace avoids the pitfalls of timing-only inference. The integration with production systems and case studies (e.g., diagnosing latency issues and mitigating application-layer DDoS attacks) highlights the framework’s real-world relevance.
However, I find some limitations. First, the approach depends on extracting meaningful transaction fields, which may not always be available in proprietary or encrypted protocols. Second, while the system reduces overhead, it still requires eBPF-based kernel instrumentation, which may introduce operational complexity in certain environments. For future work, it would be interesting to explore global inference across components, as well as extensions for encrypted or proprietary protocols.