Title: MegaScale-Infer: Efficient Mixture-of-Experts Model Serving with Disaggregated Expert Parallelism
Authors: Ruidong Zhu (Peking University); Ziheng Jiang (ByteDance); Chao Jin (Peking University); Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu (ByteDance); Xuanzhe Liu, Xin Jin (Peking University); Xin Liu (ByteDance)
Introduction
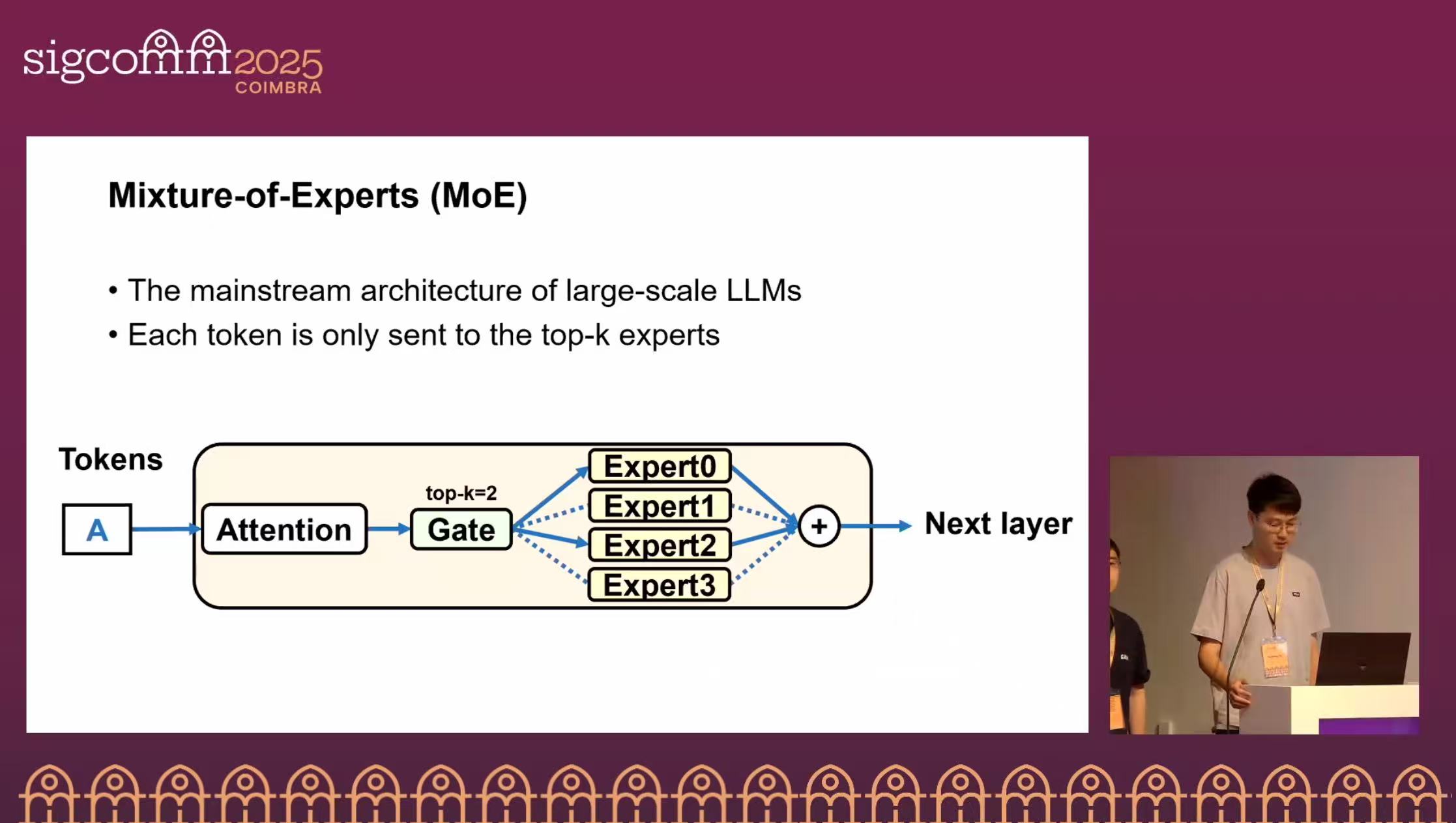
Mixture-of-Experts (MoE) improves LLM performance and reduces computational complexity. However, due to sparse activation, the feed-forward network (FFN) becomes memory-bound during inference, which markedly lowers GPU utilization.
This paper proposes MegaScale-Infer, an efficient MoE serving system that decouples attention and FFN, enabling independent scaling, tailored parallel strategies, and heterogeneous deployment. To cope with MoE sparsity, MegaScale-Infer introduces a Ping-Pong pipeline, splitting request batches into micro-batches and dynamically scheduling them between attention and FFN for inference, effectively hiding communication overhead and maximizing GPU utilization. To support disaggregated attention and FFN, MegaScale-Infer provides a high-performance M2N communication library that minimizes data-transfer overhead.
Key idea and contribution

The core idea is to separate attention and FFN to improve GPU utilization, but disaggregation raises two challenges: (1) because each token must repeatedly and sequentially traverse attention and FFN, separating the two components can introduce idle periods; (2) independent scaling requires M2N and N2M communication between M attention GPUs and N expert GPUs, and using traditional All-to-All primitives can significantly degrade performance.
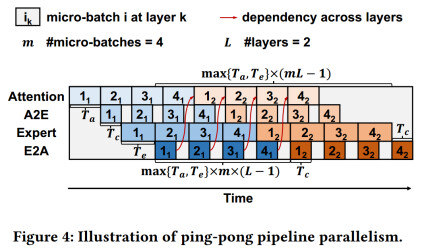
To address Challenge 1, MegaScale-Infer adopts disaggregated expert parallelism with a Ping-Pong pipeline: replicate the attention module with data parallelism, scale the FFN module with expert parallelism, split requests batches into micro-batches, and alternate them between attention and FFN to hide communication and raise GPU utilization.
To address Challenge 2, MegaScale-Infer provides a high-performance M2N communication library that avoids unnecessary GPU to CPU copies and reduces group initialization and synchronization overheads, thereby minimizing the communication cost induced by MoE sparsity.
Evaluation
In a homogeneous setting on NVIDIA 80 GB Ampere GPUs, the authors evaluate MegaScale-Infer across different MoE models. Compared with vLLM and TensorRT-LLM, MegaScale-Infer improves per-GPU decoding throughput by 7.11× and 1.90×, respectively. In a heterogeneous setting, they build a cluster with NVIDIA H20 and L40S GPUs, assigning H20 to attention and L40S to experts. Compared with vLLM and TensorRT-LLM on H20, MegaScale-Infer improves throughput per cost by 3.24× and 1.86×, respectively, leveraging H20’s high bandwidth and L40S’s cost-effective compute.
Q&A
Q1: Could you provide more details about the traffic pattern between the attention nodes and the expert nodes, and outline some design goals for the underlying network?
A1: The primary goal is to keep the communication time shorter than the compute time of both modules so that communication can be overlapped by computation. The traffic pattern is M-to-N: each token produced by an attention node may be dispatched to any expert node.
Personal thoughts
MegaScale-Infer improves GPU utilization by decoupling attention and FFN, enabling independent scaling and heterogeneous deployment. It is worth further exploration to dynamically adjust the numbers of attention and expert nodes to match different workload distributions for optimal performance.