Authors
Xudong Liao (Hong Kong University of Science and Technology)
Yijun Sun; Han Tian; Xinchen Wan; Yilun Jin; Zilong Wang; Zhenghang Ren; Xinyang Huang; Wenxue Li; Kin Fai Tse (Hong Kong University of Science and Technology)
Zhizhen Zhong (MIT)
Guyue Liu (Peking University)
Ying Zhang (Meta)
Xiaofeng Ye (EmbedWay)
Yiming Zhang (Xiamen University)
Kai Chen (Hong Kong University of Science and Technology)
Scribe: Haodong Chen (Xiamen University)
Introduction
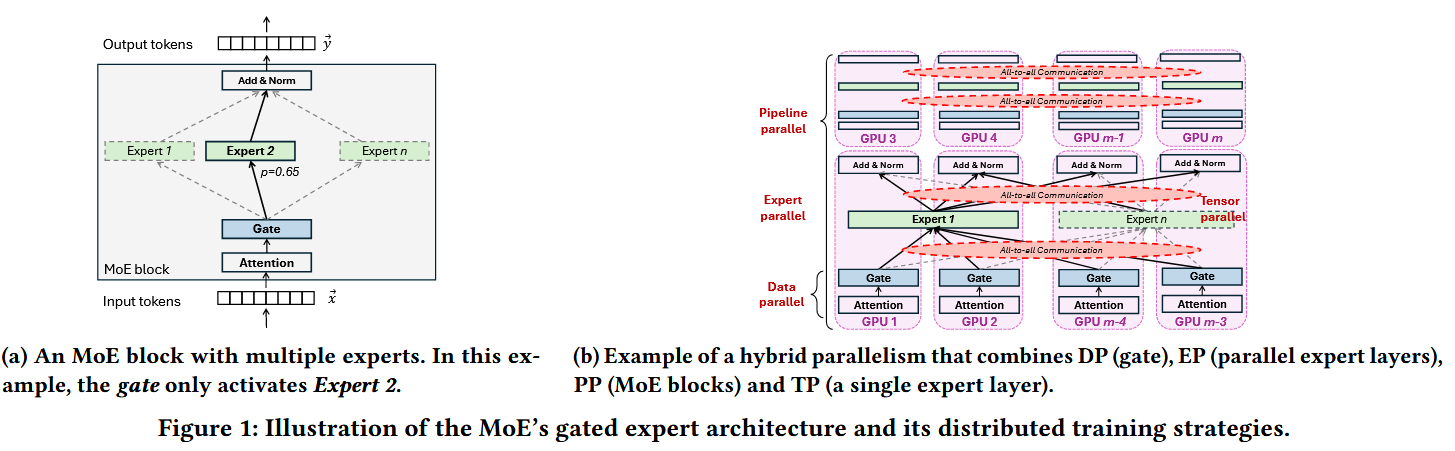
Mixture-of-Experts (MoE) models significantly improve the scalability of large models through sparse gating mechanisms, but introduce new challenges in distributed training. Expert Parallelism (EP) in MoE brings intensive All-to-All communication, whose traffic patterns are dynamic and imbalanced (different experts are activated in different iterations).
Existing GPU interconnects (e.g., NVSwitch, Fat-tree/EPS) are static topologies that often lead to over-provisioning and bandwidth waste, making them unable to efficiently adapt to such dynamic communication. Prior studies leverage Optical Circuit Switches (OCS) for topology reconfiguration, but they assume stable traffic patterns and lack the ability to adjust dynamically during training.
Core Idea and Contributions (Design)
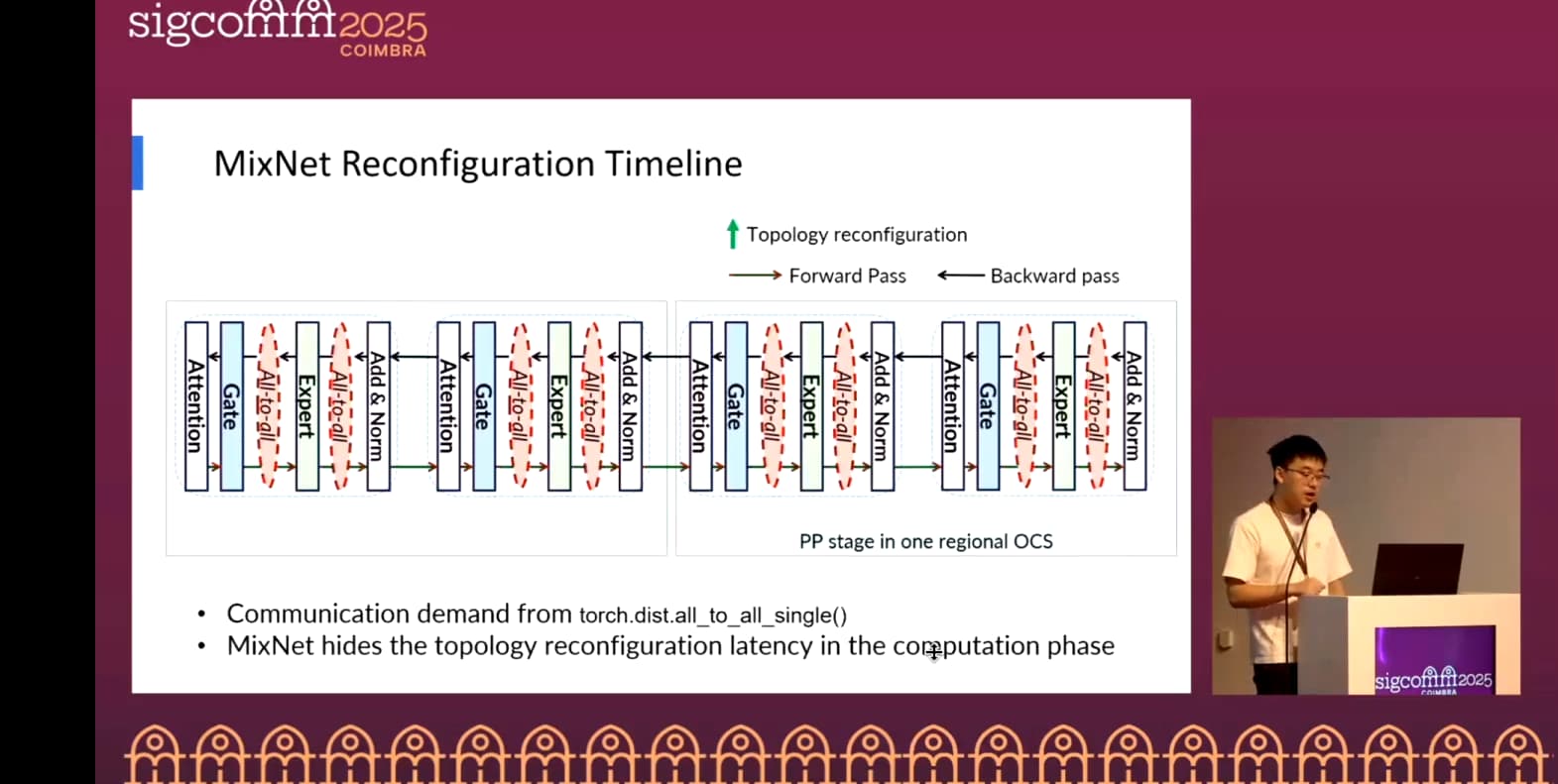
The core idea of MixNet is to insert a millisecond-level reconfigurable regional high-bandwidth OCS domain between scale-up NVSwitch and scale-out EPS. A lightweight greedy algorithm allocates direct optical circuits to bottleneck server pairs on demand during training iterations. A customized communication runtime then maps TP/PP/DP/EP flows to the most suitable interconnect and path, enabling “on-demand provisioning” of bandwidth.
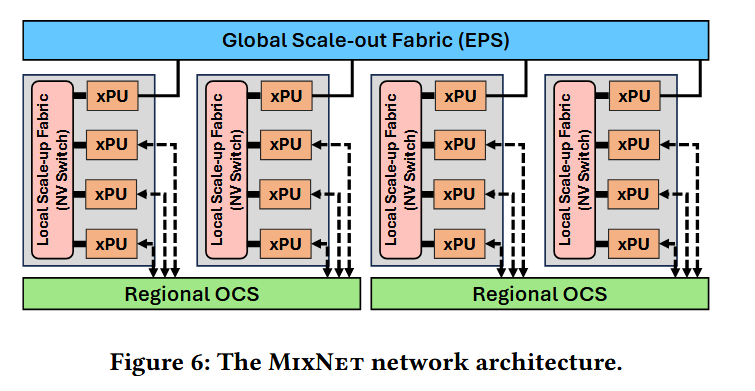
Design details: The cluster is divided into regions based on communication locality. Each server connects part of its NICs to OCS and the rest to EPS. The control plane, driven by decentralized regional topology controllers, generates and deploys OCS topologies per iteration based on runtime-monitored or predictable EP demands. A lightweight greedy strategy prioritizes direct optical circuits for bottleneck server pairs, with reconfiguration triggered in forward/backward compute gaps within milliseconds.
On the data plane, a customized collective communication library splits and routes flows:
- TP is fixed to NVSwitch
- DP/PP go through EPS (with hierarchical all-reduce to reduce outbound traffic)
- EP is prioritized to OCS regions, combined with “delegated GPU + NVSwitch scatter/gather + concurrent OCS/EPS transmission + NVSwitch reordering” routing.
MixNet also keeps dual-path redundancy (OCS + EPS) and leverages regional controllers for local reconfiguration in case of link/NIC/GPU failures, ensuring continuous and scalable training.
Experiments
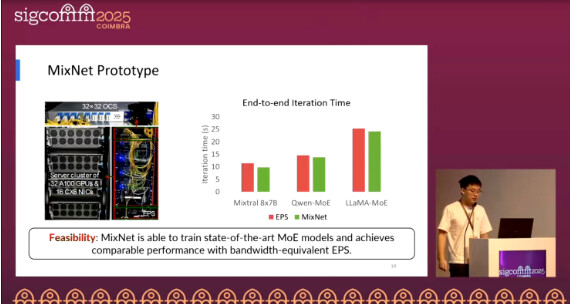
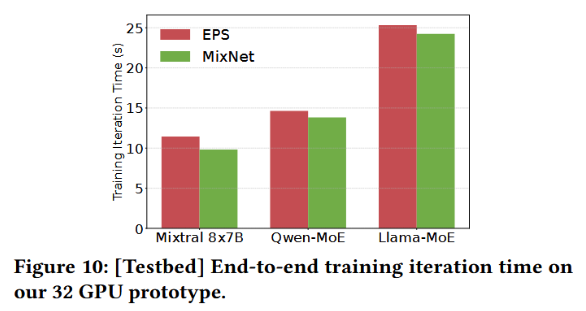
End-to-end prototype (Fig.10):
On a real prototype of 32×A100 GPUs, MixNet—using only 1×100G to EPS and 3×100G to OCS—achieves iteration latency close to a 4×100G non-blocking EPS baseline across three mainstream MoE models. This is achieved by dynamically allocating direct optical circuits for sparse and imbalanced EP All-to-All traffic, without affecting TP/DP transmission paths or accuracy.
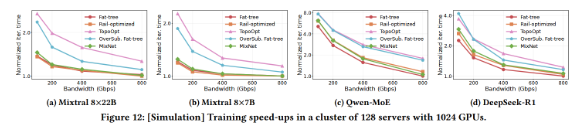
Training speedup (Fig.12):
In simulations on 128 servers (1024 GPUs), MixNet’s iteration time approaches that of Fat-tree/Rail-optimized topologies and is on average 1.4–1.5× faster compared to TopoOpt.
Q&A
Q1:
Compared with electrical switch-based architectures, what is the main selling point of MixNet?
A1:
By using optical switches, MixNet can achieve on-demand bandwidth provisioning, making it more cost-effective and lower-overhead than electrical switches.
Q2:
Since MixNet uses online reconfiguration, does it risk expanding the failure domain?
A2:
MixNet is designed specifically to handle the randomness and dynamism of EP traffic. Thus, dynamic reconfiguration better meets communication demands rather than expanding the failure domain.
Personal Opinion
MixNet captures the essence of EP traffic in MoE training—dynamic, sparse, and regionalized. By embedding a reconfigurable OCS high-bandwidth domain between NVSwitch and EPS, it enables in-training topology reconfiguration, allocating scarce direct bandwidth precisely to the communication pairs with the greatest demand. This achieves a better performance/cost trade-off than traditional static topologies.