Title: Network Support For Scalable And High-Performance Cloud Exchanges
Authors: Muhammad Haseeb, Xiyu Hao, Ulysses Butler, Anirudh Sivaraman (New York University); Jinkun Geng (Stanford University); Daniel Duclos-Cavalcanti (Technical University of Munich); Radhika Mittal (University of Illinois Urbana-Champaign); Srinivas Narayana (Rutgers University)
Scribe: Xiaoqiang Zheng (Xiamen University)
Introduction
This paper addresses the challenge of running financial exchanges in the public cloud, a setting attractive for scalability and cost efficiency but fundamentally ill-suited for the stringent latency and fairness requirements of trading. Traditional on-premise exchanges rely on engineered determinism (e.g., equalized cables, low-jitter switches) to ensure all participants receive market data simultaneously and that earlier orders are processed before later ones. Public cloud environments, however, introduce nondeterminism and latency variance, making fairness hard to guarantee. Existing systems like CloudEx or DBO demonstrate feasibility for tens of participants, but they fail to scale to hundreds or thousands, leaving open the problem of building a scalable and fair cloud-based exchange.
Key idea and contribution
The authors propose Onyx, a system designed to provide scalable, fair, and high-performance networking support for financial exchanges in the cloud. Onyx combines well-studied techniques with new mechanisms in a novel context. For outbound communication, Onyx employs an overlay multicast tree augmented with round-robin packet spraying, proxy hedging, and receiver hedging to minimize latency variance and ensure nearly simultaneous delivery of market data to up to 1000 participants. For inbound communication, Onyx introduces a sequencer based on clock synchronization to preserve fairness across participant orders, along with a Limit Order Queue (LOQ) scheduling policy that prioritizes critical orders during bursts, improving order matching under high load. Importantly, Onyx reuses the same tree structure in reverse to mitigate incest effects, reducing packet drops and enabling higher throughput.
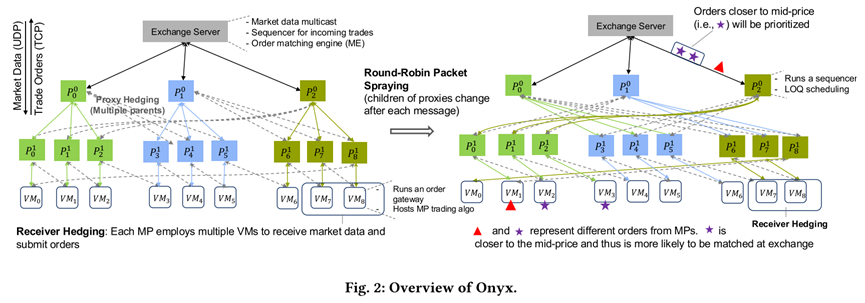
Evaluation
The authors evaluate Onyx extensively against baselines such as AWS Transit Gateway multicast and CloudEx, with results summarized below:
-
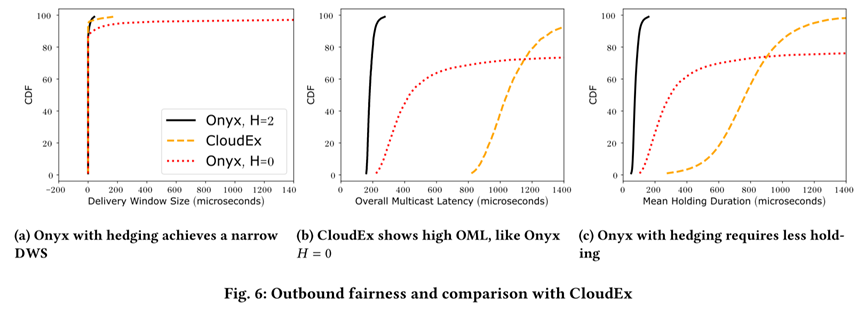
Multicast latency: Onyx achieves significantly lower overall multicast latency (OML). For example, the median OML is 129 µs, about 43% lower than AWS TG (228 µs) and 49% lower than direct unicast (254 µs). At the 90th percentile, Onyx reduces latency by ≈75%.
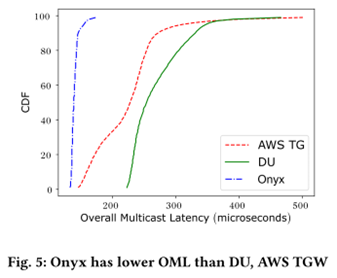
-
Outbound fairness: Onyx achieves extremely small delivery window sizes (DWS), with ≤1 µs difference in multicast latency across participants at high percentiles (up to 92p, and up to 99.9p with receiver hedging). This ensures simultaneous data delivery, outperforming CloudEx which suffers from higher OML when trying to maintain fairness.
-
Scalability: Onyx scales gracefully from 100 to 1000 receivers while maintaining median OML ≤250 µs and fairness gaps ≤1 µs. This demonstrates that fairness and performance remain stable even as the number of participants increases by an order of magnitude.
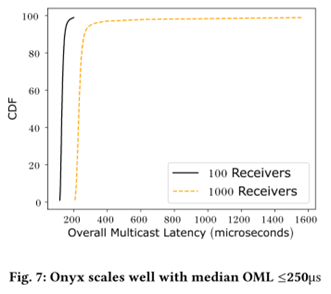
-
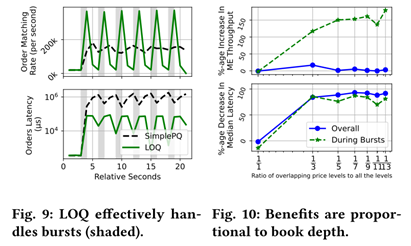
Order throughput: Onyx’s inbound pipeline, enhanced by the sequencer and Limit Order Queue (LOQ), achieves far higher order matching rates than CloudEx. For instance, during bursts, Onyx processes orders almost in real time while CloudEx builds up long queues.
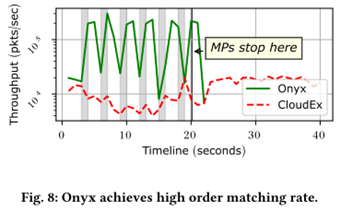
-
Burst handling: LOQ scheduling improves throughput and reduces latency by prioritizing critical orders. During bursts, LOQ improves matching throughput by 137% and reduces latency by 70% compared to a timestamp-based FIFO queue.
Q1: There’s one there. Thanks for interesting talk. I’m just curious for the inbound fairness case, when is the timestamp written at the client side, and how can you make sure the timestamps sent by clients are genuine, not manipulated?
A1: Right, so there’s various trust models to run this system, but we kind of, so this is also assumed in prior work, that there is an entity that could be for example the smart nick at the client, or it could be a program that’s effectively running the market participants code, that’s actually giving you a trusted timestamp of order generation. So we have a discussion of the trust models also in the paper, but I guess the system, it is a requirement for you to have these trusted synchronized timestamps, for you to be able to order them and do various things with them. Yes, so there are many options to kind of how you want to generate those timestamps.
Q2: Oh, hi. Very cool work, thank you for the presentation. I just had a question about transparency, right? Like in the traditional data center, there’s the glass floor, right? Like you can follow the cable from your VM and like make sure it’s not a bit shorter. Do you have any mechanism that does that, but in this setting? So like a way for a participant to not only trust the data center, but actually verify that the latency it gets is not worse than the others?
A2: Yeah, that’s a very interesting question. Yeah, we haven’t necessarily thought too deeply about how you would provide those kinds of metrics, but I can imagine kind of the same way in which we say measure parameters across different clients or on the internet and try and compare. Like there might be some sort of a collaborative approach to actually doing that. But I do think it’s an interesting open question. Like what are good ways to ensure when anyone sees this kind of deployment, like for everybody to be convinced that it is fair. So I think, yeah, we haven’t thought too deeply about that. But I would also encourage you to pose this question on Slack because I believe the first author may have other things to say about it.
Q3: Thanks for the talk. Very interesting. So you’re using multicast to get fairness on the market data. So what kind of loss rates do you see on multicast and how do you cope with that? So if I understand the question correctly, how do we implement multicast? Well, how are you dealing with loss in multicast?
A3: Right, so I guess the slide deck may have changed, but all right. So each of our proxy nodes is a VM that is under the control of the exchange. So if you think about this topology as a network, effectively now your proxy nodes run code that can consume a piece of data from like the parent in the tree and then duplicate, kind of make a few copies and then send it down to the children in the tree. So it’s all, yeah, you should think about it as, I guess, packet processing that’s implemented in software. So it’s not, it does not require hardware support for multicast if that was the concern.
Q4: Because you’re not doing multicast over the wire anywhere. Where is the multicast part in that case?
A4: So, if you remember the tree in the picture, right? So the tree is basically sending out duplicate copies of the same piece of market data. Like every node in the tree receives one copy of the data and sends out k copies if there are k children in the tree.
Q5: Okay, but is it lossless or is it lossy?
A5: No, so we run TCP between every node in the tree. So, yeah, as long as there is some path, it will be lossless. However, losses do happen and it is something that can degrade the guarantees of fairness in the system. Like if, for example, if you have no reachability between two nodes in the tree. So let me take a step back. So for outbound data, like the market data, so that actually runs over UDP. And so there are special services that actually do retransmissions for the outbound market data. For the inbound side, we run TCP and that, for the most part, you can assume is lossless. So losses can get in the way of these fairness guarantees, but the measurements, at least, that we’ve seen for these popular kind of public cloud providers is that the loss rates are actually low for this to be still practical in most cases.
Personal thoughts
I find this paper compelling in its blend of practical design and rigorous evaluation. I particularly like the way Onyx reuses its overlay multicast tree in both directions, elegantly solving scalability challenges for both data dissemination and order submission. The evaluation is thorough, covering latency distributions, fairness metrics, and burst handling. However, one limitation is that Onyx still falls short of the nanosecond-level determinism of colocated on-prem exchanges, and the overhead of sequencing may constrain throughput in extreme scenarios.