Authors: Weihao Jiang; Wenli Xiao; Yuqing Yang (Shanghai Jiao Tong University); Peirui Cao (Nanjing University); Shizhen Zhao (Shanghai Jiao Tong University)
Scribe: Haodong Chen (Xiamen University)
Introduction
High-performance networks (HPNs) for large-scale AI training often aim to simultaneously provide three properties: in-order delivery (I), lossless transmission (L), and out-of-order capability (O). This paper shows that the coexistence of I, L, and O inevitably leads to a new form of deadlock called Orderlock: at the receiver, packets that arrive early must be buffered to preserve I and L, but once the reordering buffer is full and the critical packet has not yet arrived, the system enters self-blocking. This phenomenon can be triggered by a single flow and differs from PFC deadlocks (which rely on cyclic buffer dependency) and HoL blocking. The authors formally define the ILO theorem and demonstrate via simulations and testbed experiments that increasing buffer sizes or relying on recovery mechanisms cannot solve the problem in practice. They further compare several Orderlock-free designs and show that LO (orderless delivery) provides the best potential for AI collective communication.
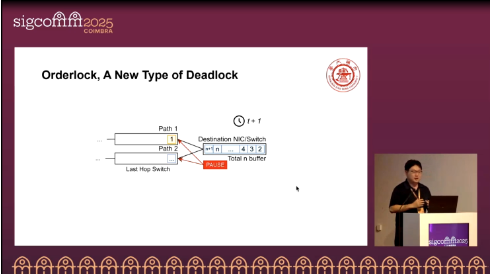
Core Ideas and Contributions
The paper formally proposes the ILO theorem (I∧L∧O as the necessary condition for deadlock) and provides the sufficient condition: if the maximum out-of-order arrival (MOA) ≥ reordering buffer size, then Orderlock occurs. Orderlock can be triggered by a single flow under common packet-level load-balancing schemes.
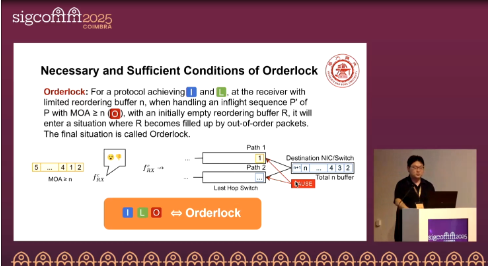
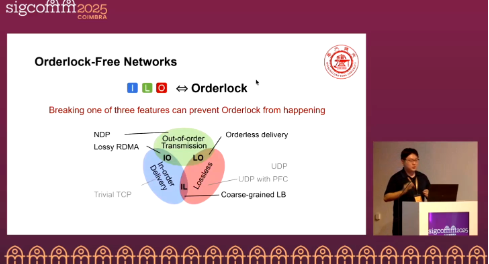
Simply increasing the buffer cannot resolve the issue: in L∧O networks, pause propagation makes end-to-end latency unbounded, the BDP loses its validity as a buffer metric, and MOA follows a long-tail distribution that grows with flow size. The authors argue that one of I/L/O must be broken to achieve Orderlock-free operation, and systematically compare four design paths—IL (limit reordering), IO (lossy with selective retransmission), LO (orderless delivery, reordering at the endpoint), and NDP/CBFC (header trimming or credit-based flow control). This framework allows practical trade-offs between performance, deployability, and resource overhead.
Evaluation
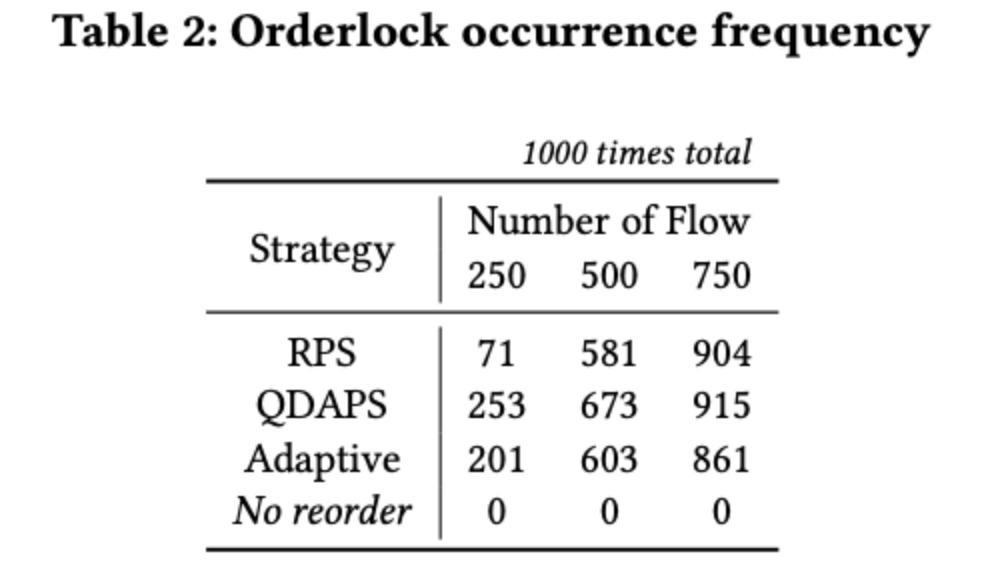
Orderlock Occurrence Frequency (Table 2 & Fig. 5)
In a 3-tier fat-tree with PFC enabled and CBD-free routing, packet-level load balancing (RPS/QDAPS/Adaptive) triggers Orderlock rapidly even for a single flow. Across 250/500/750 concurrent flows with 1000 trials each, occurrences reach RPS: 71/581/904; QDAPS: 253/673/915; Adaptive: 201/603/861. With reordering disabled (control), the count is 0, confirming high frequency and that it is distinct from PFC deadlocks.

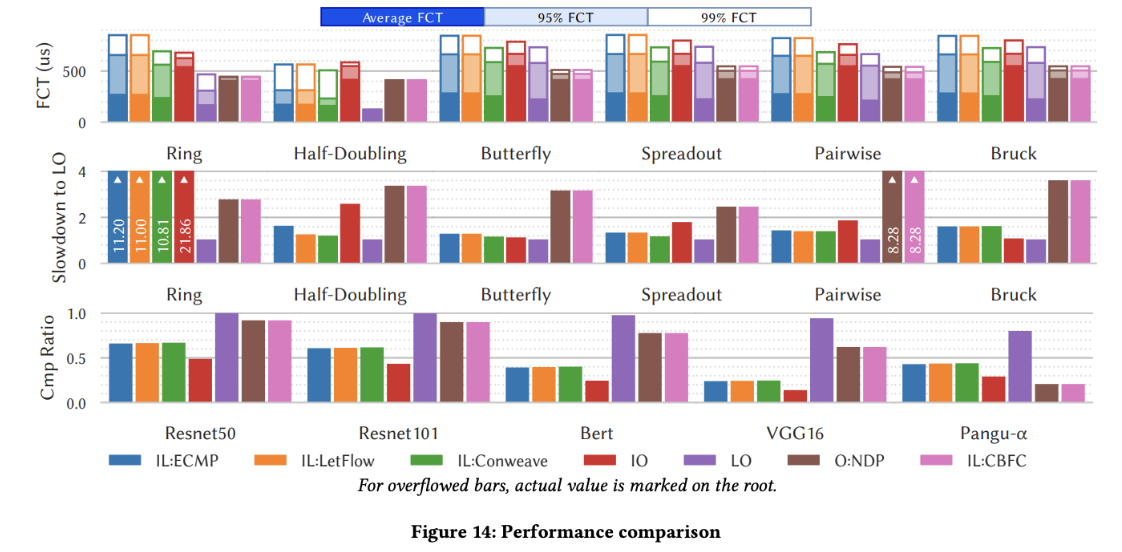
Orderlock-free Protocol Comparison (Fig. 14)
For AI collectives (AllReduce/All-to-All), LO (orderless delivery) achieves the best overall performance. The paper reports up to 11.2× communication and 4.54× training improvement potential over off-the-shelf baselines. NDP/CBFC can approach LO when buffer ≈ BDP but limit concurrency; IO (SR) degrades under heavy reordering due to false retransmissions; IL (ECMP/Flowlet/ConWeave) offers limited tail-latency gains for low-entropy elephant flows.
Q&A
Q1: Have you analyzed in-network reordering, or did you only assume host-based reordering?
A1: Yes. Approaches such as SQR perform reordering inside switches, but they still rely on limited queues/buffers to hold early packets. Once the MOA exceeds this limit, Orderlock still occurs, even with in-network reordering.
Q2: If applications/algorithms can tolerate out-of-order execution (e.g., SGD still converges), could we relax the requirement for in-order delivery?
A2: This is indeed an insightful direction. Our work focuses on the network/protocol layer. At the application/system layer, relaxing order constraints (e.g., out-of-order aggregation or flexible execution) could reduce dependence on I. However, this requires modifications to training frameworks and consistency semantics, which is beyond the scope of this paper but worth future exploration.
Q3: Have you discussed with industry whether the three conditions (I, L, O) hold in practice?
A3: Our work is preliminary. Different companies make different trade-offs between deployment complexity and performance. The general consensus is that breaking one of I/L/O is the most pragmatic way to avoid Orderlock.
Personal Opinion
The paper makes a novel contribution by formally defining Orderlock and proving it can be frequently triggered even by a single flow under packet-level load balancing. However, achieving Orderlock-free operation on existing hardware remains challenging, as it requires new capabilities from both switches and NICs.