Title: Planter: Rapid Prototyping of In-Network Machine Learning Inference
Author: Changgang Zheng (University of Oxford), Mingyuan Zang (Technical University of Denmark), Xinpeng Hong (University of Oxford), Liam Perreault (University of Oxford), Riyad Bensoussane, Shay Vargaftik (VMware), Yaniv Ben-Itzhak (VMware), Noa Zilberman (University of Oxford)
Scribe: Kexin Yu (Xiamen University)

Introduction:
This paper presents Planter, a modular and efficient open-source framework for rapid prototyping of in-network machine learning. In-network inference promises high throughput and low latency but requires significant expertise across programmable data planes, machine learning, and applications - a prohibitive bar for many. Existing solutions are one-off efforts, hard to reproduce or extend. Planter addresses these limitations by identifying general mapping methodologies to introduce new and enhance existing machine learning mappings, supporting diverse platforms and pipeline architectures. The evaluation shows Planter improves over prior model-tailored works in machine learning performance while reducing resource consumption and co-existing with network functionality. Planter-supported algorithms run at line rate on unmodified commodity hardware, providing billions of inference decisions per second.
Key idea and contribution:

The authors present Planter, a framework that facilitates the deployment of in-network machine learning (ML) inference across different architectures and targets. Planter is designed to be modular, allowing for easy integration of new models, targets, architectures, and use cases.
The authors define three general model mapping methodologies that enable mapping a wide range of ML inference algorithms onto programmable data planes. They also introduce four newly mapped inference algorithms, enhance the efficiency of six previously proposed mappings, and support four more state-of-the-art mapping solutions. Their evaluation compares the performance of multiple prior solutions on a single platform, highlighting the importance of supporting different models and showing Planter’s high resource efficiency compared to previous proposals while achieving the same or better ML inference performance.
Evaluation:
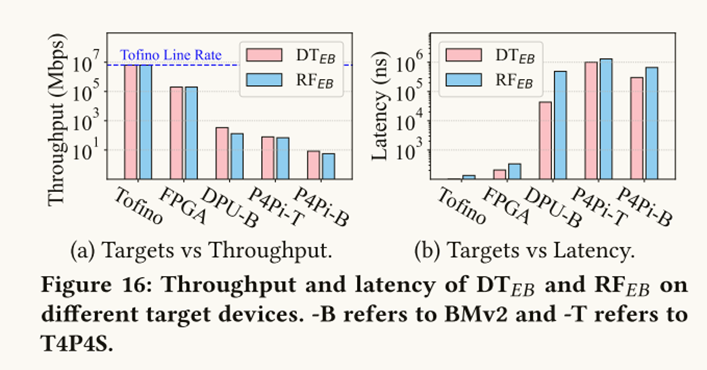
This paper evaluates the system performance of two sample in-network ML algorithms, DT𝐸𝐵 and RF𝐸𝐵, on various hardware and software platforms. The hardware targets, such as Tofino and FPGA, are able to achieve line rate throughput, reaching 6.4Tbps and 100Gbps respectively. In contrast, the software switches (BMv2 or T4P4S) running on the ARM cores of P4Pi and DPU have much lower throughput, ranging from tens to hundreds of Mbps.
A similar pattern is observed for latency. The hardware targets can achieve microsecond-scale latency, while the software platforms only reach sub-millisecond latency. Interestingly, the complexity of the ML model impacts the performance on the software platforms. The more complex RF algorithm exhibits lower throughput and higher latency compared to the DT algorithm on these software targets. However, the model complexity does not have a notable effect on the performance of the hardware platforms.
This result is significant because it demonstrates the ability of programmable network devices to run complex ML models at line rates with low latency, enabling new classes of in-network ML applications.
Q&A:
Question 1:
We all know edge servers would achieve low latency and support more general machine learning models. What is the point of using in-network machine learning?
Answer 1:
If you want to use the edge server it means you have to forward to the server first. However, if in-network machine learning is used, i.e. run on this device, this means that latency is much shorter, by hundreds of nanoseconds or microseconds. But if you want to try some larger models, for example, the deep neural network the definitely the server-based solution based on GPU probably will be a better solution.
Question 2:
I am just curious about how the in-network achieves the integrity of each model that you have divided then in distributed parts.
Answer 2:
Integrity can be achieved by setting constraints. For example, in our work we choose ILP.
Personal thoughts:
This work addresses the problem that previous in-network ML solutions tend to be disposable and difficult to replicate, scale, or compare across different platforms. However, there is a limit to the number of ML models that can be supported at this time, and we hope to add more in future research.