Title: Principles for Internet Congestion Management
Authors:
Lloyd Brown (UC Berkeley)
Albert Gran Alcoz (ETH Zürich)
Frank Cangialosi (BreezeML)
Akshay Narayan (Brown University)
Mohammad Alizadeh (MIT)
Hari Balakrishnan (MIT)
Eric Friedman (UC Berkeley, ICSI)
Ethan Katz-Bassett (Columbia University)
Arvind Krishnamurthy (University of Washington)
Michael Schapira (Hebrew University of Jerusalem)
Scott Shenker (UC Berkeley, ICSI)
Scribe: Mingjun Fang
Introduction:
This paper discusses the issue of congestion control on the Internet. Since the Internet is a large-scale decentralized resource-sharing network and computer communication is bursty, to cope with the inevitable network packet overload, the Internet relies on host-based congestion control algorithms (CCAs) to manage overload issues and ensure network performance. However, existing systems often enforce TCP friendliness (traffic is considered TCP-friendly if its arrival rate does not exceed that of a compliant TCP connection under the same circumstances). Under the TCPF paradigm, the network plays a passive role, and aggressive CCAs gain more bandwidth on congested links, which can lead to the deployment of increasingly aggressive CCAs, thereby increasing overall congestion and harming the Internet. Previous research has shown that this limits the rapid improvement and full efficiency of congestion control algorithms (CCAs) , hindering the rapid growth of network traffic, especially in modern dynamic network environments, and impeding the emergence of new delay-sensitive CCAs (such as Copa and Nimbus). To address this issue, the authors propose CCA independence, which requires the network to actively ensure that all reasonable CCAs obtain the same bandwidth in the same static environment. With the implementation of CCAI, since the bandwidth rights of CCAs are guaranteed, CCAs can freely optimize other metrics, such as packet loss, delay, and jitter, making the deployment of delay-minimizing CCAs possible. Moreover, CCAI eliminates the need for a single standard CCA, promoting diversity and innovation in CCAs.
Additionally, many major Internet players no longer adhere to TCPF (e.g., Google, Amazon, Akamai, Dropbox, and Spotify), making it necessary to consider whether there are suitable alternatives to the TCPF paradigm. Previous approaches, such as per-flow fairness and network utility maximization, do not align with the current economic and commercial pursuits of the Internet. Flows have no role in the commercial agreements of the Internet; they have no “rights” to bandwidth or utility and are not the unit for user charges. The authors seek a conceptual foundation that meets the demands for Internet bandwidth sharing while aligning with the commercial and economic interests of all parties involved. In summary, this concept needs to (i) be implementable within the current Internet architecture (such as IP, BGP, and the best-effort service model) while allowing for the addition of extra protocols and mechanisms, and (ii) provide bandwidth allocation consistent with the current commercial arrangements among parties.
Key idea and contribution:
The authors have designed and articulated three principles to achieve Congestion Control Algorithm Independence (CCAI) in alignment with the commercial and economic models of the Internet. These principles lay the foundation for a framework of weighted and queue-based allocations that are consistent with Internet commercial behaviors—the authors name this framework “Recursive Congestion Share” (RCS). The three principles are depicted in Figure 1.

Principle 1: Enforce bandwidth allocation only during network congestion, described in terms of relative entitlements.
This means that when the network is congested, RCS uses the relative entitlements of packets to decide which packets should be discarded, thus avoiding scenarios where more aggressive congestion control algorithms (CCAs) consume more bandwidth. Relative entitlements avoid absolute guarantees of bandwidth. Compared to designs expressing bandwidth rights in terms of guaranteed rates (i.e., the absolute level of end-to-end bandwidth a user can expect), RCS, through the mechanism of relative entitlements, reduces the negative impact of congestion on statistical multiplexing efficiency and more effectively allocates bandwidth resources during congestion.
Principle 2: These relative entitlements should align with existing commercial arrangements, considering their granularity, recursive nature, and the roles and impacts of monetary flows.
Users need to pay for access to the network, so current commercial agreements are usually made at the granularity of access agreements rather than on a per-flow basis. Access agreements are recursive (when packets are transmitted end-to-end, the sender’s operator pays the next-hop operator, who then pays the subsequent operator), and the direction of monetary flow is similarly recursive, flowing from the domain of the receiver to its provider step by step. These inter-domain commercial behaviors are crucial for network traffic transmission, and thus their recursive nature must be fully considered when managing network congestion.
Principle 3: While the network decides the bandwidth allocation between two endpoints, the composition of the traffic flowing between them should be determined by the endpoints.
The question of who controls and how to control this traffic should follow Principle 2. Decisions should adhere to the flow of funds: the sender decides what traffic enters the network (as with the Bundler mechanism), and the receiver decides what traffic exits the network (as with the Crab mechanism).
The author argues that RCS allocation can achieve the goals of CCAI. The author explains this issue from the perspective of game theory. Assuming the game process is that users try to optimize their throughput individually and are constrained by rationality to avoid sustained loss. The game in this scenario is analyzed in two steps: first, using Mixed Integer Linear Programming (MILP) formalization to determine whether there are multiple game theory equilibria; then simulating the dynamic game theory process to determine whether rational CCAs will converge to these equilibria.First, assuming that the various CCAs controlling the flows are the “players” of the game, and the players are economically rational. Given a set of input rates r , the resulting throughput is determined as a. The players’ strategies are their sending rates, and their payoffs are their sending rates (with a payoff of −∞ if the output rate is less than the sending rate). The author discusses whether these conditions will converge to Nash Equilibrium and Stackelberg Equilibrium. A Nash Equilibrium occurs when each player uses their optimal strategy (i.e., sending rate) assuming all players are aware of the strategies chosen by others. That is, for each i, ri is at its maximum (ai = ri), assuming that all other players keep their sending rates unchanged. In a Stackelberg Equilibrium, an individual CCA first commits to a certain sending rate. Other CCAs in the game observe the actions of these “leaders” and respond, reaching a Nash Equilibrium in the resulting subgame, assuming the leader’s strategy remains unchanged. For a given game, if there is only one Nash Equilibrium and it is also the only Stackelberg Equilibrium, then no matter how “aggressive” (regardless of how they choose their sending rate) each player is, the game has only one stable equilibrium. However, if there is a Stackelberg Equilibrium different from the Nash, or if there are multiple Nash Equilibria, then the “leaders” in Stackelberg can try to manipulate the game to achieve a result that maximizes their throughput. Although Appendix B of the original text provides examples where game manipulation can achieve maximal throughput, the author uses Mixed Integer Linear Programming (MILP) formulations to establish two models to show that in the vast majority of cases, there is only one Nash Equilibrium. The first model is based on random topologies, designed to increase the likelihood of pathological cases: each flow chooses a random path and uses random weights at each entrance on the path. The second model uses topologies subsampled from the CAIDA AS relationship dataset. The MILP solver is used to calculate allocations in both models. Let as denote the allocation of flow s at equilibrium. Establish constraints:
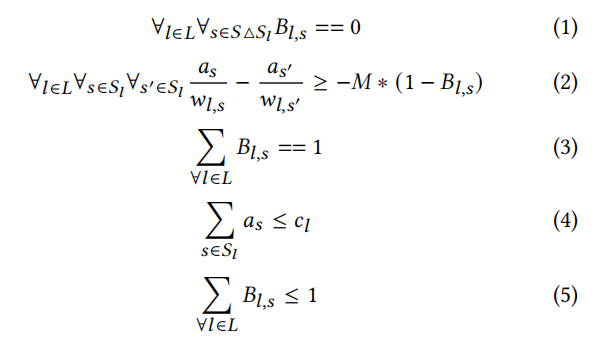
Constraint (1) ensures that no flow becomes a bottleneck on a link not on its path. Constraint (2) ensures that each flow receives its weighted fair share on each congested link. Constraint (3) ensures that each flow s is bottlenecked on exactly one link. Finally, constraint (4) ensures that no link exceeds its maximum capacity. To generate the Stackelberg solution with flow s as the leader, replace constraint (3) with constraint (5), allowing s to be bottlenecked on 0 or 1 link. Simulation results are provided in the Evaluation section.
Evaluation:
Most topologies converge to a Nash Equilibrium state, demonstrating that in the vast majority of cases, RCS allocation can achieve the goals of CCAI. The author presents the results in the first row of Table 1, showing that very few topologies exhibit problematic equilibria. When examining individual flows, the results are even more significant. Out of all 748,920 flows, only 68 (0.009%) benefit from adopting an aggressive Stackelberg leader strategy. Any flow attempting to improve its average gain through a Stackelberg strategy only achieves an average increase of 0.011%. Therefore, in this model, the returns of aggressive strategies are very limited.The author used the CAIDA topology generator to sample 1,030 8-flow topologies, considering only sender weights (606 topologies) and both sender and receiver weights (424 topologies). We assigned CCAs to the hosts in the topology (ensuring each CCA appeared at least once) and iterated multiple times to rotate the CCA assignments. In all these topologies, the agents converged to a single Nash Equilibrium.

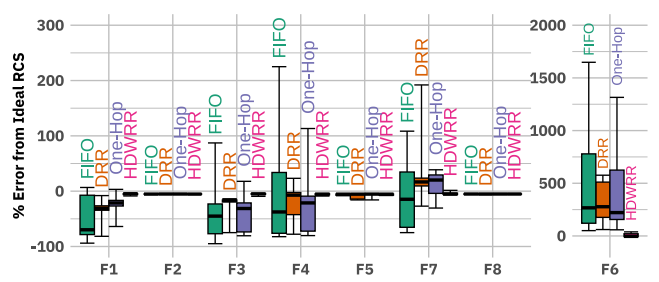
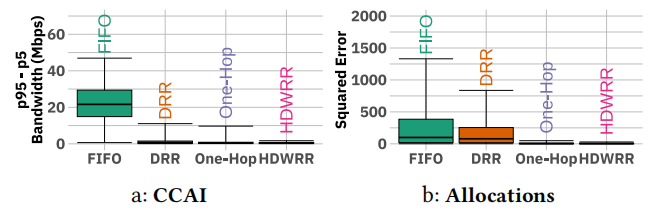
The author discusses through experiments whether various implementation methods can achieve the ideal effect of RCS allocation design. To evaluate RCS allocation in actual CCA implementations, the author implements a mechanism capable of achieving these allocations. They use a scheduling algorithm based on Deficit Round Robin (DRR) [41] — Hierarchical Deficit Weighted Round Robin (HDWRR). The author conducted experiments under four configurations: (1) FIFO, (2) DRR, allocated by flow rather than aggregate, similar to Fair Queuing, (3) One-Hop, using HDWRR but limiting the weight tree to depth 1, and (4) HDWRR, i.e., the implementation described above. In the case of FIFO scheduling, the bandwidth allocation for flows F1, F3, F4, F7, and F6 is sometimes up to 100% lower than the RCS allocation, showing severe starvation. The bandwidth allocation for flow F6 is excessively high, up to 15 times more. Figure 4 shows significant differences in bandwidth allocation (up to 28 Mbps) and large squared errors relative to the RCS allocation in different topologies under FIFO. Under DRR and One-Hop scheduling, the bandwidth allocation for flows F1, F3, F4, F6, and F7 is significantly lower or higher than the RCS. In Figure 3, HDWRR’s bandwidth allocation almost perfectly matches the ideal RCS allocation. In Figure 4, both the bandwidth difference and the squared error relative to the RCS allocation are significantly lower than those for FIFO, DRR, and One-Hop. This indicates that HDWRR’s bandwidth allocation is more consistent across different topologies and can more accurately achieve the theoretical RCS allocation.
Q & A
Question 1:
Q: I have several questions, but these are all based on one assumption. You’re asking the service providers to charge differently for users, right?
A: Yes, service providers are already charging differently for different users.
Q: Currently, providers like Xfinity offer different fixed levels and cap bandwidth. How do you see customers accepting a model where paying more results in less packet drop? If customers don’t accept this, do you foresee adaptation without involving customers, essentially service providers charging each other?
A: The edges of the network can be defined as a configuration parameter, whether they involve eyeball networks or not. The system can work without direct customer involvement.
Question 2:
Q: I’m curious about the mechanistic aspects. TCP schemes didn’t invent congestion control, and previous systems like ATM had admission control. The innovation was minimal mechanism without signaling or per-flow state in congestion points. What mechanistic aspects are involved here?
A: Providing isolation involves more mechanism than not providing it. Modern routers can implement fair hierarchical weighted fair queuing without much difficulty. The mechanism required doesn’t need per-flow state since flows are not economic actors. We need state per endpoint or per endpoint domain.
Question 3:
Q: Do you envision applying congestion shares for both the uplink and downlink similarly, or can they be different?
A: You must consider both sender side weights and receiver side weights to be consistent with internet economics. The paper discusses applying sender side weights when relevant and receiver side weights when relevant.
Personal thoughts
I believe this article provides profound guidance for the design of congestion control algorithms. The three design principles proposed by the author, along with the RCS framework to replace the TCP-friendly paradigm and the proof that RCS can meet the independence of congestion control algorithms, left a deep impression on me. Additionally, what stood out to me the most was the author’s inclusion of the commercial economic benefits of the internet in the design principles. In my view, the longevity of the BGP protocol in the network domain is largely due to its allowance for network operators to implement commercial relationships through routing policies, which is why I believe the RCS framework holds substantial potential for the future. However, I have some concerns regarding the deployment of the HDWRR prototype designed based on the RCS framework in the network. HDWRR is currently implemented in software, and the weight calculation and queue management for each data packet require a significant amount of time, which might result in a high CPU burden and possible increased latency at nodes deploying HDWRR when scaled to actual internet deployment.