Title: PtCAM: Scalable High-Speed Name Prefix Lookup using TCAM
Authors: Tian Song, Tianlong Li, Yating Yang (Beijing Institute of Technology)
Scribe: Ziyi Wang (Xiamen University)

Introduction:
Name prefix lookup is a core operation in name-based data packet forwarding in information-centric networking (ICN) and URL redirection in content delivery networks (CDNs). Essentially, it performs longest prefix match (LPM) on class URL names. Due to the large scale of the name collection, variable name lengths, and the requirement to support per-packet lookup, achieving high-speed processing poses significant challenges. Existing systems are typically implemented using general-purpose storage (such as SRAM or DRAM) or algorithms (such as trie, hash, or Bloom filter), but these methods exhibit clear limitations in terms of throughput, memory efficiency, or extensibility. In particular, as the number of names increases from 77 million in 2015 to 752 million in 2025, traditional approaches struggle to handle such large-scale name collections while maintaining line-rate forwarding. Therefore, there is an urgent need for a solution that enables high-speed look-up while offering good extensibility.
Key idea and contribution:
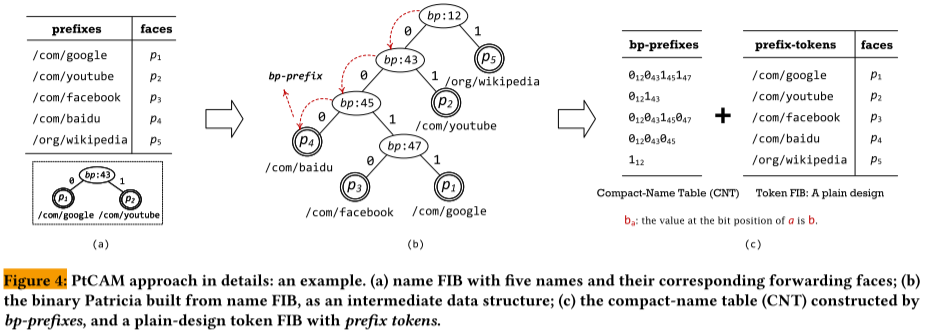
This paper proposes PtCAM (Patricia-TCAM) scheme, which operates as follows. First, compact names are extracted from the original names using a binary Patricia trie. Second, these compact names are loaded into the TCAM to serve as a fast lookup classifier, while RAM is used to store associated tokens for Longest Prefix Match (LPM) verification. The novelty of this scheme lies in its sophisticated integration of the Trie-based structure with the advantages of TCAM hardware devices.
Similar to most other LPM schemes, PtCAM consists of a preprocessing stage and a lookup stage (as shown in the figure below). During the preprocessing stage, the given Forwarding Information Base (FIB) contains names and the next hop in name-based routing lookup (faces in the figure), utilising a binary Patricia tree to construct the internal data structure. Subsequently, a Compact-Name Table (CNT) and a Token FIB (tFIB) are generated: the CNT is used to populate the TCAM, with each compact name corresponding to one entry, while the tFIB is used to load tokens and their corresponding face information into RAM (DRAM/SRAM).
Contributions:
- Propose the PtCAM scheme, whose core innovation lies in the extraction and utilization of compact names through a binary Patricia trie and the generation of a memory layout for TCAM. This scheme combines the merits of the trie structure for precise lookups with the bit-level parallelism of TCAM.
- Conduct tuning of PtCAM efficiency to adapt to commercial TCAM products with limited capacity in practical applications. Additionally, authors develop a scalable PtCAM design that supports large-scale name collections of millions to tens of billions using multiple TCAMs.
- Develop a PtCAM compile program that converts name collections into memory layouts compatible with the TCAM schema. By deploying a prototype system, its feasibility and efficiency on actual hardware were verified.
Evaluation
The paper demonstrates through systematic evaluation that TCAM and its improvements achieve outstanding performance in lookup speed and scalability. A single 80 Mbits TCAM chip can accommodate 1.1 million human-readable names and 1.6 million random names using the optimized version and nearly 16.2 million human-readable names and 32.8 million random names (or even more) using the scalable version. This result is highly significant because it successfully enables high-speed, million-scale name lookup on commercial off-the-shelf (COTS) IP line card TCAM hardware, thereby providing a practical and foundational framework for the evolution of future network architectures toward a content-centric paradigm.
Q&A:
Q: After making some changes to the FIB entries, the process seems to require a full recompilation and then a reinstallation of the entire database. Is there an incremental update process to make this super fast? What’s your opinion on this?
A: For updates, you will have to incrementally build the internal binary Patricia trie data structure. However, the key to our design is that during the preprocessing stage, we reserve some columns of TCAM for future updates, leaving a don’t care value as the default for them. When the insertion of a new name introduces a new critical bit position in the trie structure, the system can activate these reserved columns. Consequently, the operation of inserting an update into the TCAM becomes a very fast online process. According to the experimental results (Section 5.4, Figure 12(b) of the paper), only 8 critical positions (columns) are required to support updates for all 20% of the names.
Personal thoughts
The standout feature of PtCAM lies in its practical applicability on existing TCAM devices, enabling seamless deployment without requiring specialized hardware. This work skillfully combines a mature algorithmic structure (binary Patricia trie) with an efficient hardware component (TCAM), achieving near-line-rate name lookup performance without significantly increasing hardware costs. For scenarios involving complex name prefixes or irregular structures, a potential area for improvement is the system’s memory usage, where exploring more efficient memory layout strategies could be beneficial.