Title: RDMA over Ethernet for Distributed Training at Meta Scale
Authors: Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, Hongyi Zeng (Meta)
Scribe : Bang Huang (Xiamen University)

Introduction
The paper discusses Meta’s implementation of Remote Direct Memory Access over Converged Ethernet (RoCE) networks for distributed AI training. It addresses the challenges of building a high-performance, reliable network infrastructure to support the growing computational demands of AI models. However, building such a network is challenging due to high bandwidth and scalability need, characteristics of AI traffic, various congestions and limitations of the collective library. Overall, this paper provides a comprehensive overview of the design principles, including aspects of Network, Routing, Transport, and Operation. The insights provided in this paper may help the deployment of RDMA technology for AI applications for building high-performance, dedicated networks for distributed training.
Key idea and contribution

The paper shares Meta’s experiences of designing a robust network infrastructure to support large-scale artificial intelligence (AI) training. The authors designed a dedicated backend network called AI Zone for training, separate from the frontend network for data ingestion. This approach allows for independent evolution and scaling. They also developed a enhanced routing schemes based on ECMP, along with a centralized traffic engineering, and flowlet switching (refer to the original paper for details). Furthermore, they tuned DCQCN for various collectives and leveraged the receiver-driven traffic admission mechanism of collective library to manage congestion effectively. They found that roofline performance can be achieved by co-tuning of both collective library configuration as well as network configuration.
Evaluation
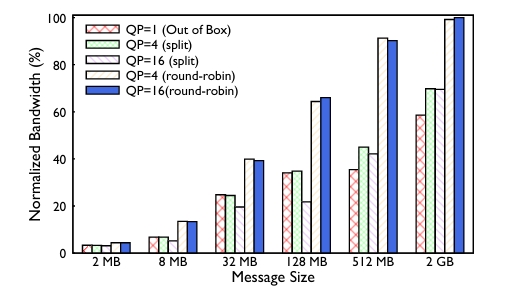
For routing, here is an experiment about testing the ECMP and QP scaling performance, it increases number of flows for hierarchical collectives through QP Scaling software feature in Collective Library. From the experiment results above, we can see that better performance can be achieved when using different scaling strategies, it achieves up to 40% improvement for AllReduce collective.
The authors also conducted more experiments to show that optimal performance can be achieved by co-tuning network and collective, for more detailed statistics, please refer to the original paper.
Q&A
Q1: What is the rationale behind the tries of shallow buffer in ToR switches and deep buffer in Spine tier?
A1: Firstly, ToR switches, often white-box switches, allow for greater flexibility in managing traffic, such as separating control and data messages into different queues. Secondly, the granularity of the rack typically involves 16 GPUs. This setup minimizes the impact of back pressure, as any issue would only affect a small portion of the network.
Q2: Have you tried any other methods (besides ECMP and flowlet switching), and what are the major challenges behind them?
A2: It has the operational simplicity of something like ECMP, we can easily test it and then start to tune it. Other approaches maybe too hard and not all NIC vendors support them.
Q3: Whether multi-rail topology could alleviate the low performance issues associated with static routing.
A3: The static routing and all-reduce performance issues mainly arise due to operational reasons and bandwidth limitations. Multi-rail topologies can reduce latency by minimizing network hops, but the trade-offs didn’t justify the shift until reaching higher bandwidths like 400 Gbps.
Personal thoughts
This paper offers valuable insights into the design and operation of RoCE networks for AI training. I appreciate the detailed discussion on routing schemes and congestion control, which are critical for optimizing performance. However, the complexity of tuning these systems and the reliance on proprietary mechanisms pose challenges. Overall, the paper provides a comprehensive overview of Meta’s approach and its practical implications for large-scale AI training.