Title: Realizing RotorNet: Toward Practical Microsecond-scale Optical Networking
Authors: WWilliam M. Mellette (inFocus Networks); Alex Forencich, Rukshani Athapathu, Alex C. Snoeren, George Papen, George Porter (University of California, San Diego)
Scribe: Xiaoqiang Zheng (Xiamen University)
Introduction:
Two of the most promising demand-oblivious network designs, RotorNet and its extension, Opera, rely on a novel switching technology known as a rotor switch to construct an all-optical datacenter network. While prior work on RotorNet and Opera outlines a vision for a simple, scalable, high-bandwidth, low-latency network, it fails to address many practical concerns because the authors lacked access to a functional rotor switch. Specifically, while the RotorNet authors demonstrated the potential ofa rotor switch using an 8-port mock up, the device itself was actually a MEMS-based selector switch. Similarly, the Opera network design was prototyped using a Tofino-based electrical packet switch as a stand-in for the rotor switch. Moreover, both systems employ custom network transport protocols at the end hosts, preventing the authors from conducting straightforward end-to-end performance testing using standard tools.
Key idea and contribution:
In this paper, the authors provide the first real-world evaluation of RotorNet and Opera using an actual rotor switch. They discuss their experience manufacturing, deploying, and performing system-level testing of a 128-port optical rotor switch connecting a rack of commodity servers using commercial transceivers and an unmodified Linux networking stack. In addition to demonstrating high-performance operation with end hosts running standard Linux, their deployment highlights the robustness and flexibilty of the RotorNet/Opera approach. While their switch has 100% port yield on all 256 single-mode fibers, the rotor itself exhibits minor manufacturing defects.
The authors also develop and deploy a novel end-host-based masking technique—akin to bad-sector mapping in commercial hard drives—that allows TCP transfers to extract 99.5% of the achievable link capacity despite the imperfections, demonstrating the practicality of the rotor concept. They also show how Opera’s expander-graph- based path selection allows deployments to make full use of potentially sub-optimal matchings installed in the rotor switch.
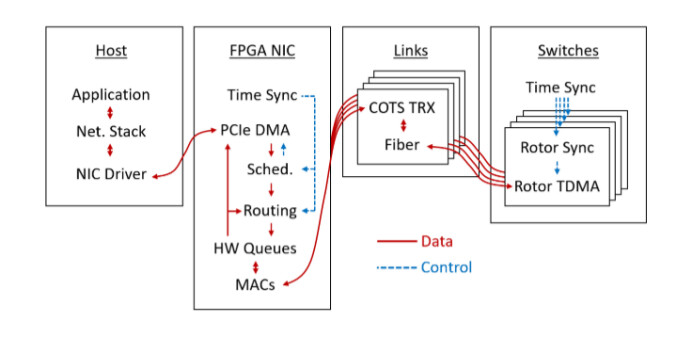
Evaluation:
The authors first evaluate the ability to send end-to-end TCP traffic between remote Linux applications, with packets traversing the network stack, NIC driver, NIC, and rotor switch. As shown in Figure 2, the work achieves 0 TCP retransmissions, a large congestion window, and a throughput within 2% of the ideal 2.5 Gb/s (0.5% overhead when subtracting out the defect gap). Notably, none of this requires any modifications to the Linux application, TCP, or the Linux networking stack.

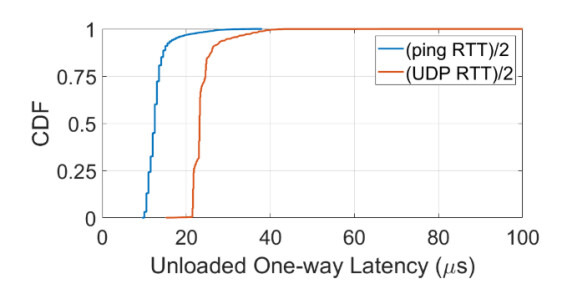
Next, the authors evaluate traffic delivery from a latency perspective with multi-hop Opera forwarding enabled. Because ping operates at the kernel level, they test the userspace-to-userspace latency using a simple UDP client/server program to understand the performance a typical sockets application would experience. Figure 3 shows the latency statistics for both ping and UDP. The result shows that userspace networking added an extra 10 microsecond one-way delay compared to ping.
Q1: Hello, very nice talk! So could you elaborate a bit more on the host implementation like, how accurate do you need to profile these hardware artifacts, how do you delay the packets and how much do you need to delay them?
A1: Yeah, that’s a great question. So the question was about how do we profile these point defects and synchronize those with the network. Well, we are synchronizing the switch with the end host, using the precision time protocol. And in terms of the implementation of the delay, there is a series of forwarding tables that gets cycled through in synchronization with the switch.
Q2: What line rate were you able to run the actual test bed implementation?
A2: Yeah, thank you. All of the results I presented today were done at 10 gigabits a second. We also implemented everything at 25 gigabits a second, but not 100% of the ports were able to be supported. So we ended up with something like 80 ish percent of our ports functioning at 25 gigs. So we only actually reported everything at 10gigs, and we kind of withheld the 25 gigs results because we didn’t have 100% success rate on that.
Personal thoughts:
This paper successfully advances the RotorNet and Opera concepts with a full implementation and legacy application performance, offering valuable insights into the practical challenges and potential of high-speed optical circuit switching. While this paper showcases an important step in optical switch implementation, it lacks crucial technical details on switch losses, resilience to data center environmental factors, and performance estimates at higher data rates. In my humble opinion, adding these details would make the paper more perfect.