Title: ResCCL: Resource-Efficient Scheduling for Collective Communication
Scribe : Yuntao Zhao (Xiamen University)
Authors: Tongrui Liu, Chenyang Hei, Fuliang Li (Northeastern University); Chengxi Gao (Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences); Jiamin Cao, Tianshu Wang, Ennan Zhai (Alibaba Cloud); Xingwei Wang (Northeastern University)
Introduction
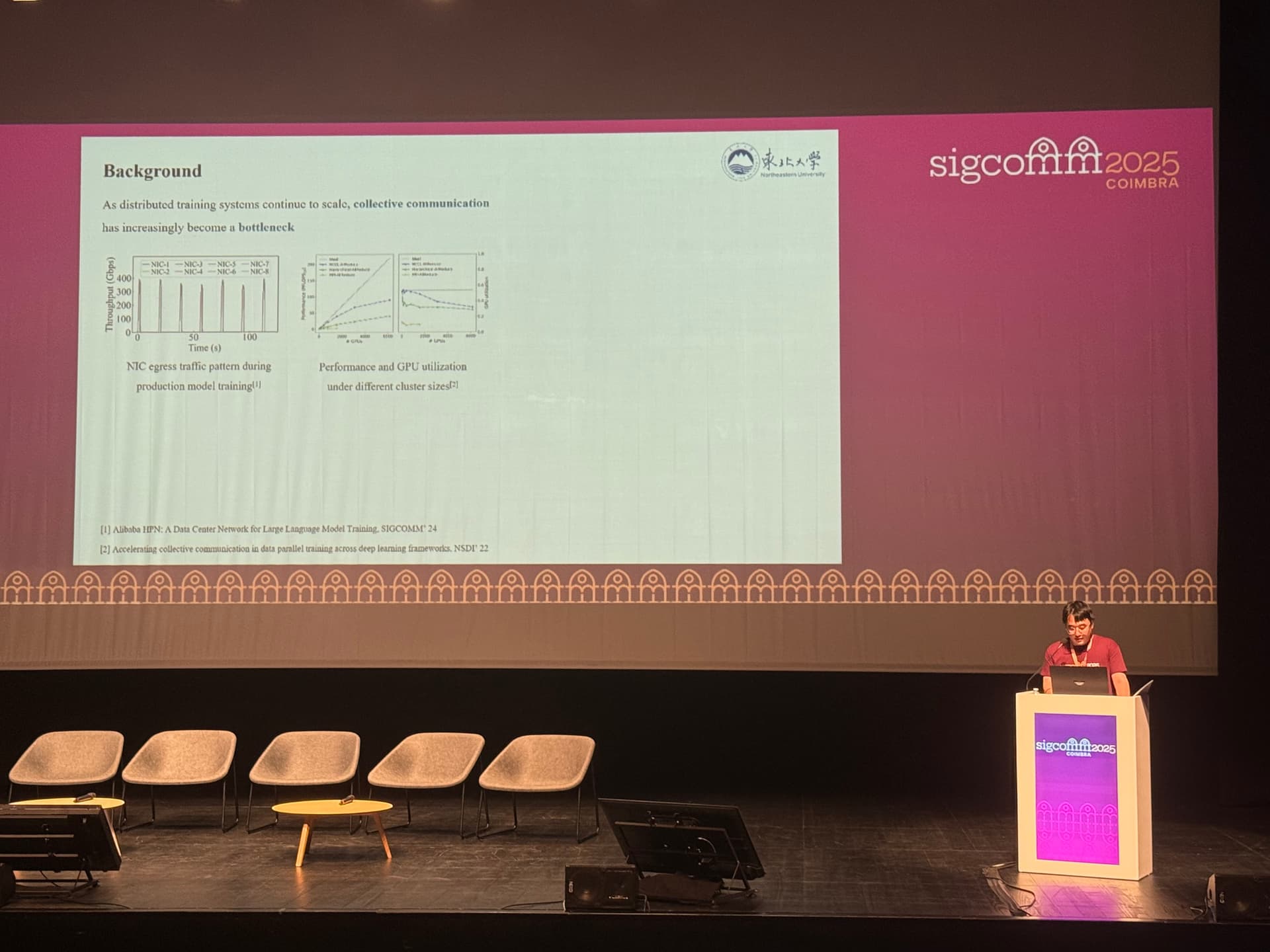
In large-scale distributed deep learning training, collective communication is essential for synchronizing gradients and parameters across GPUs. However, as training systems scale up, communication has increasingly become a major bottleneck. Even with cutting-edge hardware such as DGX-H100 systems connected via 400 Gb/s InfiniBand, communication can still account for 17%–43% of iteration time when training large models like GPT-3.
Existing collective communication libraries such as NCCL and MSCCL have focused primarily on optimizing communication algorithms. Yet, they suffer from critical execution-level inefficiencies. Specifically, they use static thread block (TB) allocation and coarse-grained scheduling, which leave many GPU resources idle and underutilize link bandwidth. In addition, these libraries rely on runtime interpreters that dynamically parse algorithm steps, introducing substantial overhead. These limitations motivated the design of ResCCL, a new CCL backend aimed at achieving resource-efficient scheduling for collective communication.
Key idea and contribution:
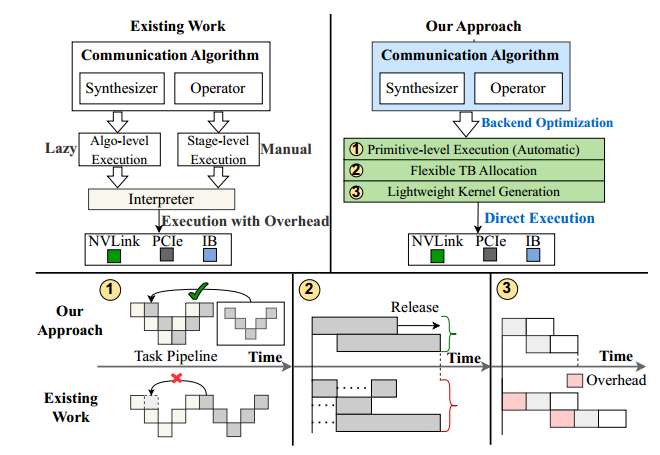
ResCCL introduces three major innovations to overcome the inefficiencies of existing backends:
- Primitive-Level Scheduling Optimization
Instead of scheduling at the algorithm or stage level, ResCCL performs scheduling at the level of communication primitives (e.g., send, recvReduceCopy). This fine-grained scheduling is guided by a global dependency analysis across micro-batches, minimizing idle pipeline “bubbles” and improving link utilization. The result is near-optimal execution order and higher effective bandwidth. - Flexible Thread Block (TB) Allocation
Unlike NCCL/MSCCL, which rigidly bind TBs to fixed GPU links, ResCCL introduces a state-based allocation mechanism. It dynamically merges non-overlapping connections and reallocates idle TBs to active communication tasks. This greatly reduces wasted SM resources and ensures more balanced thread utilization. - Lightweight Kernel Generation
ResCCL eliminates runtime interpretation overhead by directly generating streamlined communication kernels. These kernels embed the optimized primitive pipelines and execute efficiently on GPUs. This approach not only reduces control overhead but also ensures that synthesized algorithms run closer to their theoretical peak performance.
Together, these components allow ResCCL to address the core issues of static resource allocation, idle TBs, and runtime overhead, delivering substantial performance improvements.
Evaluation
Experimental Setup. ResCCL was evaluated on an A100 cluster with 32 GPUs across 4 servers, each equipped with NVSwitch (intra-node) and RoCE NICs (inter-node). Baselines included NCCL, MSCCL, and synthesized algorithms generated by TACCL and TECCL, tested under both expert-designed and synthesized collective algorithms.
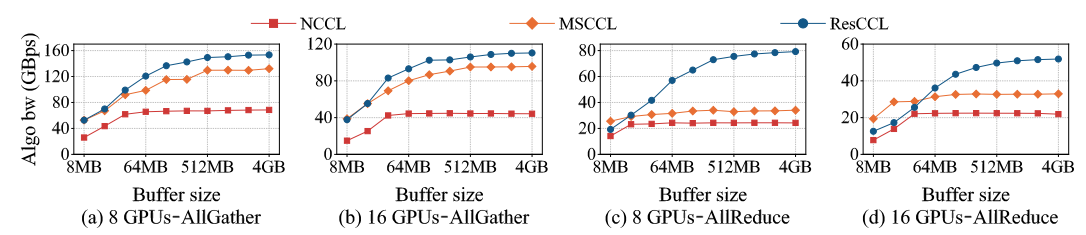
Bandwidth Performance.
- For AllGather, ResCCL outperformed NCCL by 28.1%–2.2× and MSCCL by 12.4%–1.6× on 16-GPU clusters, and achieved up to 1.6× speedup on 32-GPU clusters for large messages.
- For AllReduce, ResCCL improved bandwidth by 6.7%–2.5× over NCCL and 10.7%–2.5× over MSCCL, except for very small messages (<16 MB) on 32 GPUs where fixed overhead caused up to 8.3% slowdown.
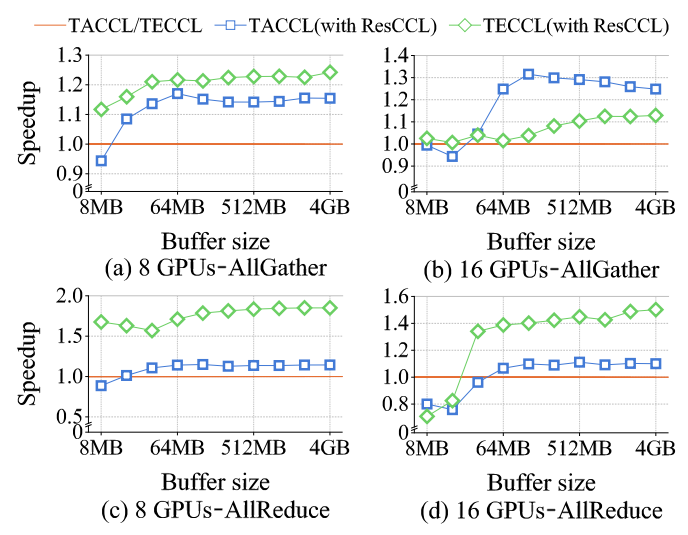
- For synthesized algorithms, ResCCL achieved 4.6%–1.5× speedups over MSCCL for TECCL-generated algorithms and up to 1.4× for TACCL-generated ones, with only slight degradation for very small inputs.
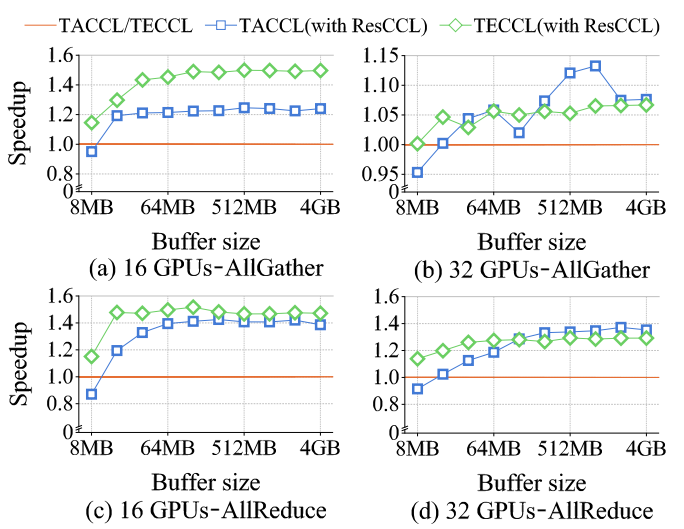
Scalability and Topology Adaptability. Across different network topologies (2–4 servers, 4–8 GPUs per server) and hardware (including V100 GPUs), ResCCL consistently maintained performance superiority. For example, it improved AllReduce by up to 3.7× over NCCL and 2.4× over MSCCL in larger settings.
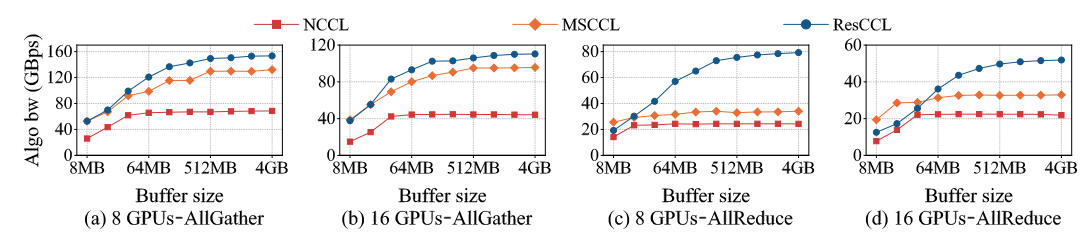
Resource Utilization. ResCCL reduced SM resource overhead by up to 77.8% and increased TB utilization by 41.6%. Unlike MSCCL, which often left TBs idle for more than 90% of their lifetime, ResCCL maintained balanced TB usage, with maximum idle ratios below 22%.

End-to-End Training. Integrated into Megatron-LM, ResCCL improved training throughput by up to 39% for T5 models (220M–3B parameters) and by 11%–20% for GPT-3 models (6.7B–44B parameters), compared with NCCL. Against MSCCL, it achieved up to 1.8× speedup for T5 and 29.3% for GPT-3. These results confirm ResCCL’s benefits in real-world distributed training scenarios.

Q1: I was wondering whether every node has to be identical and whether the topology is homogeneous and symmetrical. Does your framework handle scenarios where this is not the case?
Q2: How do you precreate a dependency graph or larger models?
A1&A2: These issues are quite complex; let’s take them offline and discuss them in detail.
Personal thoughts
ResCCL stands out for its end-to-end design philosophy: it bridges the gap between algorithm-level innovations and execution-level efficiency. By combining primitive-level scheduling, flexible resource allocation, and lightweight kernel generation, it forms a cohesive backend that realizes the theoretical performance of advanced collective algorithms in practice.
The work’s strengths lie in its meticulous optimization of execution overhead, balanced TB/SM utilization, and significant gains in both micro-benchmarks and real-world training. It demonstrates that system-level design is just as critical as algorithmic optimization for communication libraries.
However, some limitations remain. First, small-message performance suffers from ResCCL’s fixed scheduling overhead, making it less effective for workloads dominated by tiny communication sizes. Second, the system focuses on intra-job GPU scheduling, without explicitly addressing inter-job network-level congestion management. Future extensions could integrate in-network telemetry or adaptive flow control to handle multi-job contention scenarios.
Overall, ResCCL represents a significant step forward in collective communication backends, providing a compelling example of how resource-efficient scheduling can unlock the latent performance of distributed deep learning at scale.