Authors: Wenxue Li (Hong Kong University of Science and Technology; Huawei); Xiangzhou Liu; Yunxuan Zhang; Zihao Wang (Hong Kong University of Science and Technology); Wei Gu; Tao Qian; Gaoxiong Zeng; Shoushou Ren (Huawei); Xinyang Huang; Zhenghang Ren; Bowen Liu; Junxue Zhang; Kai Chen (Hong Kong University of Science and Technology); Bingyang Liu (Huawei)
Speaker: Wenxue Li
Scribe: Haodong Chen

Introduction
RDMA is widely deployed in datacenters because it offloads the network stack to RNICs to achieve high throughput and low latency; however, traditional RNICs use Go-Back-N (GBN) for loss recovery, which causes throughput to collapse on lossy Ethernet once packets are lost. Operations often enable PFC to make Ethernet “lossless” as a workaround. PFC is coarse-grained, prone to head-of-line blocking, pause/congestion storms, and deadlocks, and imposes strict distance constraints, significantly increasing operational complexity and risk. These limitations motivate the community to explore efficient RDMA over lossy networks without PFC.
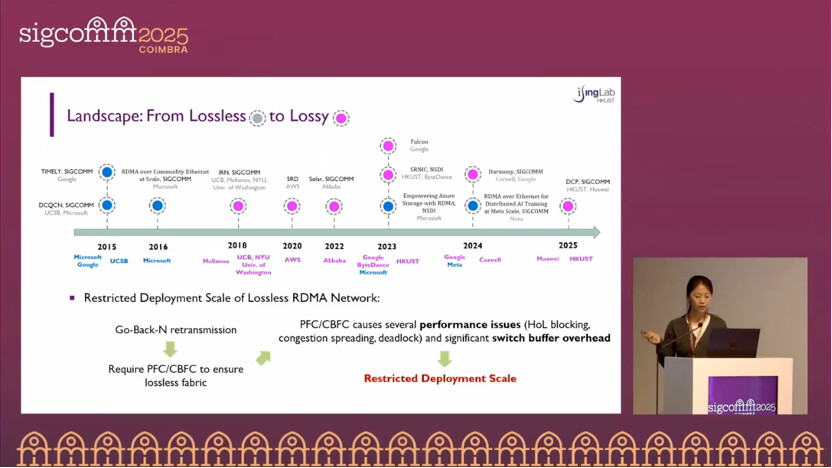
There are two main directions: (1) improve congestion control to keep switch queues small and reduce drops, which treats symptoms rather than the root cause; (2) rely on purely software retransmission, which cannot leverage RNIC offload. This has led to implementing Selective Repeat (SR) inside RNICs (e.g., IRN and newer RNICs) to improve loss recovery. Yet two core issues remain:
(1) Incompatibility with per-packet load balancing: per-packet adaptive routing naturally introduces reordering; IRN treats reordering as a loss signal (SACK-triggered recovery), which can spuriously trigger retransmission even when no actual loss occurs, producing heavy false retransmissions (the paper observes many flows with up to 100% retransmission ratio in loss-free simulation).
(2) Over-reliance on timeouts (RTO): cases such as tail loss do not trigger fast recovery and must wait for a timeout; if a retransmitted packet is lost again, the sender—having entered recovery only once—waits for the next timeout. Both effects inflate tail latency.
Key idea and contribution
Design goals (R1–R4)
Based on the above, the paper revisits RDMA reliability and establishes four goals that must be satisfied simultaneously:
R1 Eliminate dependence on PFC (remain stable on lossy Ethernet).
R2 Be naturally compatible with per-packet load balancing, distinguishing real loss from reordering and avoiding false retransmissions.
R3 Provide fast recovery for any loss (explicit loss notification, avoiding RTO).
R4 Be hardware-offload-friendly, minimizing storage and compute overhead for practical RNIC/switch implementation.

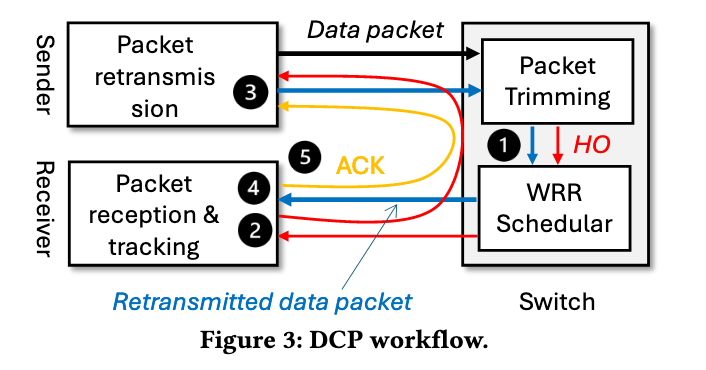
Core design: DCP
The paper proposes DCP, a transport architecture co-designed between switches and RNICs. On the switch side, a lossless control plane is provided: under congestion, the switch trims packets to header-only (HO) and reliably forwards HO packets. Endpoints use HO notifications to enable header-driven, fast and precise retransmission, and adopt message-level counting without bitmaps for out-of-order reception and state tracking. Prototypes on P4 switches and FPGA RNICs demonstrate, under real and large-scale workloads, performance improvements of about 1.6× / 2.1× over state-of-the-art lossless/lossy baselines (mechanisms and details are discussed later).
Evaluation
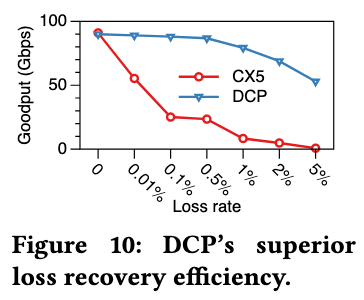
Loss recovery (Fig. 10)
On a 100 Gbps testbed with two P4 switches and 16 FPGA RNICs, the switch enforces configured loss rates (0.01%–5%): DCP flows are trimmed to HO while CX5 flows are dropped, and goodput is measured incrementally. DCP improves loss-recovery efficiency by 1.6×–72× over CX5 across this range.
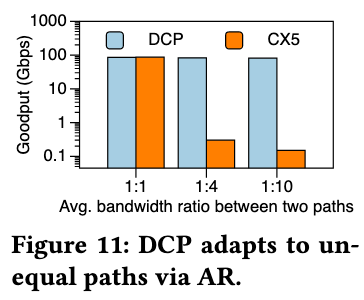
Per-packet AR / unequal paths (Fig. 11)
Two paths across switches are configured with port-capacity ratios of 1:1 / 1:4 / 1:10. The switch enables per-packet adaptive routing (AR) proportional to capacity, and the average goodput of two long flows is measured. DCP maintains stable throughput across all ratios, whereas CX5 degrades significantly under unequal capacities.
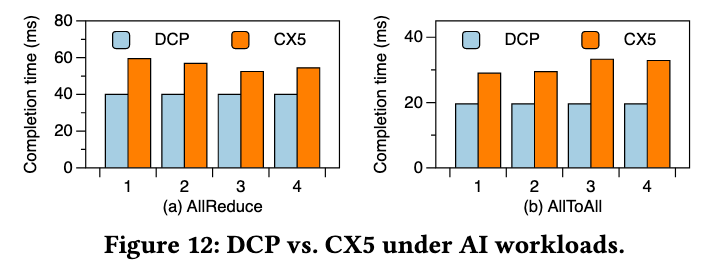
AI prototype (Fig. 12)
AllReduce/All-to-All is implemented with verbs API + OpenMPI; the 16 RNICs are partitioned into four groups and run concurrently; AR is configured for DCP and ECMP for CX5; job completion time (JCT) is recorded per group. DCP reduces JCT by up to 33% / 42% for AllReduce/All-to-All.
Long-distance link (text only, no figure): one inter-switch link is replaced with 10 km fiber (≈50 µs per hop) using 100G-LR; DCP sustains about 85 Gbps for long flows.
The following are ns-3 large-scale simulation experiments
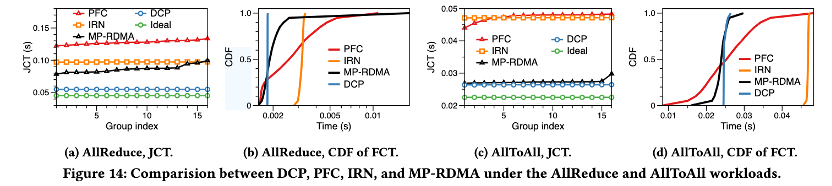
AI simulation (Fig. 14)
For AllReduce, DCP’s JCT is on average lower by 38% / 44% / 61% compared to MP-RDMA / IRN / PFC; for All-to-All it is 5% / 45% / 46% lower on average. Single-flow tail FCT is also best, explaining the JCT gains (the synchronization in collectives means one slow flow delays the whole job).
Q&A
Q1
How is the control plane keep lossless? Is PFC used?
A1
DCP switches do not depend on PFC. WRR (weighted round-robin) is used to provide a near-lossless control plane, assigning the control queue higher weight than data queues so that it is served first. The paper demonstrates that with reasonable weights, even under worst-case local incast bursts, the control plane can be kept lossless.
Q2
If link failures cause unrecoverable loss, will timeouts severely impact performance?
A2
The focus is congestion-induced loss, addressed by packet trimming for recovery. Link failures or extreme cases are considered uncommon in datacenters due to the reliability of optics and links. A customized timeout mechanism is provided for such cases, but it is not highly efficient; congestion loss is primarily handled by ACK-based transport.
Q3
Packets may be dropped for other reasons, such as link or switch failures. How are such “silent drops” detected and retransmitted?
A3
The primary target is congestion loss; loss due to link/switch failures or bit errors is not the emphasis. A timeout mechanism—similar in spirit to Go-Back-N—is included to handle these losses, though such events are believed to be uncommon in datacenters.
Personal thoughts
The main contribution of DCP is that, without lossless (PFC) guarantees, it provides a transport architecture for RDMA over lossy Ethernet that balances reliability and performance, is friendly to per-packet load balancing, largely avoids reliance on timeouts (RTO), and is practical to implement in hardware. However, deployability may be challenging because it requires hardware/firmware changes on both switches and RNICs (e.g., congestion-triggered header trimming and an HO control queue in switches, and HO-based fast retransmission and out-of-order direct writes at endpoints).