Title : S2: A Distributed Configuration Verifier for Hyper-Scale Networks
Authors : Dan Wang, Peng Zhang, Wenbing Sun, Wenkai Li (Xi’an Jiaotong University); Xing Feng (NorthWest University); Hao Li (Xi’an Jiaotong University); Jiawei Chen, Weirong Jiang, Yongping Tang (ByteDance)
Scribe : Xing Fang (Xiamen University)

Background
In large-scale data center networks, configuration errors are often the main cause of failures. To prevent errors from propagating into production, operators rely on configuration verification tools for “pre-deployment checks.” However, existing verifiers such as Batfish were originally designed for medium-sized networks. When scaled to tens of thousands of switches and hundreds of millions of routes, they often fail due to excessive memory consumption or a lack of parallelism. The paper argues that single-machine optimization alone is insufficient; instead, verification at this scale requires a combination of distributed architecture and memory control mechanisms to remain feasible in production environments.
Challenges
Severe memory bottlenecks. Control-plane simulation needs to store and propagate massive routing entries. Even when the network is split across multiple machines, a single worker may still need to hold all prefixes at peak, leading to out-of-memory errors. Beyond distributing the workload, an additional mechanism is required to bound peak memory.
Complex prefix dependencies. Route aggregation, cross-protocol redistribution, and policy configurations introduce dependencies across prefixes. Simple partitioning may break convergence semantics; thus, sharding must be dependency-aware.
Distributed simulation must preserve single-machine semantics. Workers need to exchange intermediate routes. If not carefully coordinated, the resulting behavior can diverge from single-machine simulation. A global coordination mechanism is therefore needed to mask distribution while minimizing changes to Batfish models.
Data-plane verification must be parallelized. Checking all possible paths is computationally intensive. Using a shared global BDD table causes contention, memory blow-up, and performance bottlenecks. A new mechanism is required to enable high concurrency in verification.
Implementation
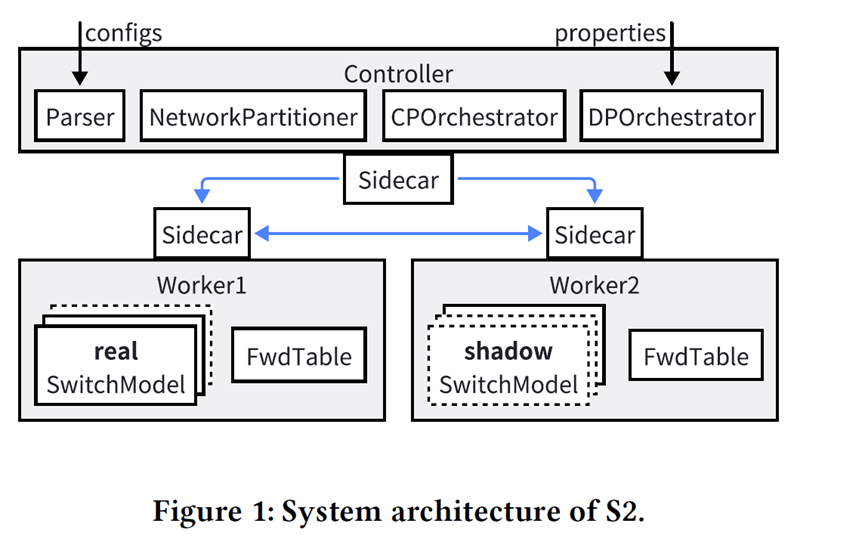
Memory control. S2 employs a three-layer strategy: distributed partitioning + prefix sharding + per-worker BDD. The network is first divided across multiple workers so each only processes part of the devices, distributing both computation and memory load. Next, prefix sharding splits routing prefixes into shards that are simulated in rounds; after each round, results are written out so a worker only keeps one shard’s routing table in memory at a time, effectively bounding peak usage. Finally, in the data plane, each worker maintains an independent BDD table; symbolic packets crossing workers are serialized/deserialized, avoiding the contention and inflation of a global shared structure.
Prefix sharding. To ensure correctness, S2 builds a Directed Prefix Dependency Graph (DPDG). Weakly connected components are used as shard units so that dependent prefixes remain in the same shard and are processed in order. If new dependencies emerge during runtime, shards are merged and recomputed to preserve semantic equivalence.
Distributed control-plane simulation. S2 adopts a “real node + shadow node” abstraction: each worker simulates its local devices as real nodes and remote neighbors as shadow nodes. Shadow nodes communicate with their corresponding real nodes through sidecars, keeping the protocol logic transparent. A control-plane orchestrator schedules shard execution and intermediate route propagation until convergence.
Distributed data-plane verification. In the data plane, the data-plane orchestrator drives each worker to locally build forwarding tables and port predicates. Symbolic packets are then propagated across workers. Since each worker maintains its own BDD table, verification scales with higher parallelism and lower memory use.
Evaluation
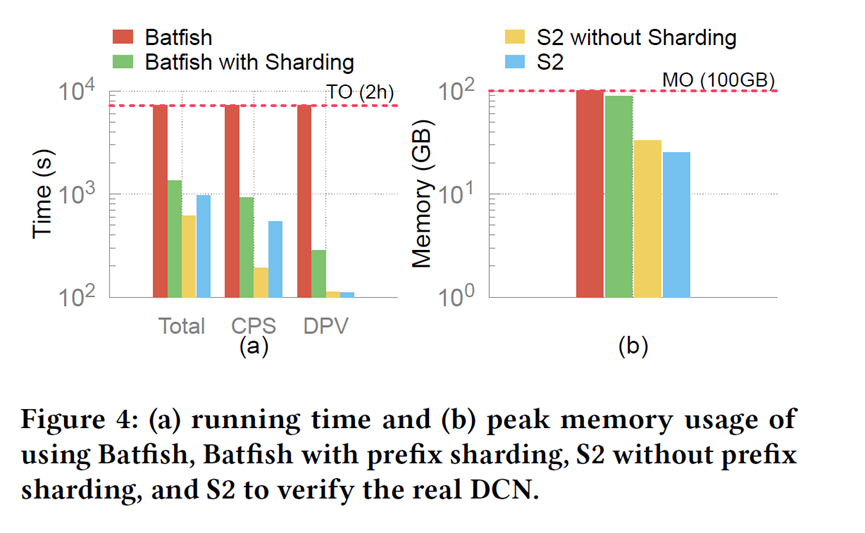
On a production network with about 16K switches and 200M IPv4 routes, S2 successfully completed verification in 16 minutes with peak memory around 35 GB per worker. By contrast, vanilla Batfish ran out of memory, while Batfish with prefix sharding could finish but used memory close to the upper bound.
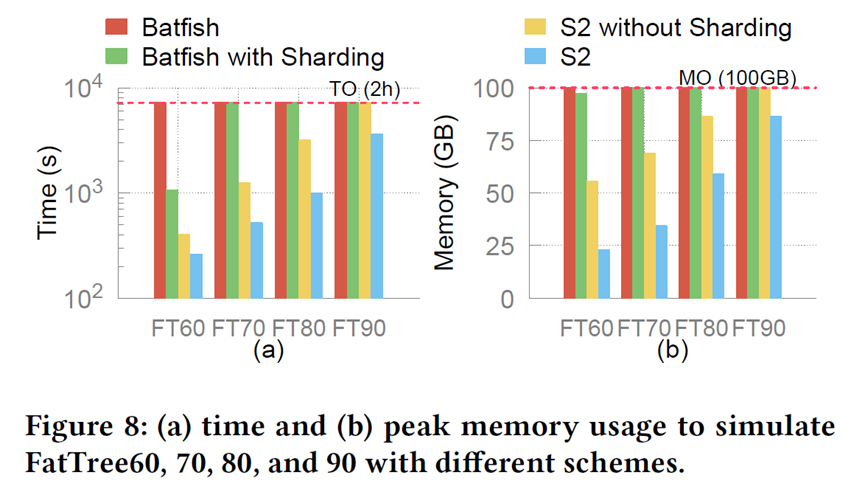
In synthetic FatTree experiments, S2 scaled to over 10K devices and 1B routes, the only system reported to handle this size. Increasing the number of workers consistently reduced runtime and memory usage, though improvements tapered off beyond eight workers. Comparisons of different partitioning strategies (random, expert, METIS) showed little performance difference, suggesting that load balancing is more important than minimizing cross-worker communication.
Q&A
Q1: At the beginning you mentioned that modular-based approaches like Lightyear and Kiryami cannot support certain properties. Which verification properties can your system support that those modular approaches cannot?
A1: Our distributed framework is decoupled from the underlying simulator, so the supported properties depend on the simulator itself. In our current implementation, S2 supports all the verification properties that Batfish supports. This design choice allows S2 to fully leverage Batfish’s property-verification capabilities.
Q2 How does performance change when scaling from 1 instance to 16 instances? With only 4 physical workers, is it possible to scale beyond 16 for even faster performance?
A2: Due to limited hardware resources, we did not have more physical servers. For the evaluation, we divided 4 physical workers into multiple logical servers to reach 16 instances. We have not yet demonstrated scaling beyond that.
Q3: Can your framework verify systems using ECMP (equal-cost multi-path) routing, and how do you handle it?
A3: Yes. S2 can handle such non-standard configurations. For example, in the same data-center network layer, different devices may have different maximum numbers of paths. These real-world ECMP variations can also be supported by S2.
Personal thoughts
S2 successfully overcomes the scalability limitations of traditional network configuration verification by extending Batfish to ultra-large-scale data center networks, and demonstrates practical feasibility on real-world deployments. Through a combination of distributed execution, prefix sharding, and per-worker BDD management, the system effectively addresses key challenges including computational load, memory peaks, and parallelization efficiency. The introduction of shadow nodes further ensures semantic consistency, resulting in a well-structured and practically viable architecture.
The use of a sidecar design to share routing information across workers enables efficient distributed route simulation—an approach reminiscent of multi-instance coordination in virtualized environments. This architecture preserves local autonomy while supporting global reachability analysis, offering a reusable paradigm for future large-scale network verification systems. If Batfish’s performance were evaluated with a higher number of shards and compared against existing distributed data plane verification frameworks such as Medusa, the evaluation would provide a more comprehensive understanding of S2’s advantages in scalability, resource efficiency, and deployment practicality.
Overall, S2 significantly advances the operational scalability of network verification tools and provides a valuable engineering blueprint for building high-performance, semantically consistent, and distributed network analysis platforms.