Title: SCX: Stateless KV-Cache Encoding for Cloud-Scale Confidential Transformer Serving
Authors: Mu Yuan (The Chinese University of Hong Kong); Lan Zhang (University of Science and Technology of China); Liekang Zeng, Siyang Jiang, Bufang Yang, Di Duan (The Chinese University of Hong Kong); Guoliang Xing (The Chinese University of Hong Kong)
Speaker: Mu Yuan
Scribe: Yining Jiang
Introduction
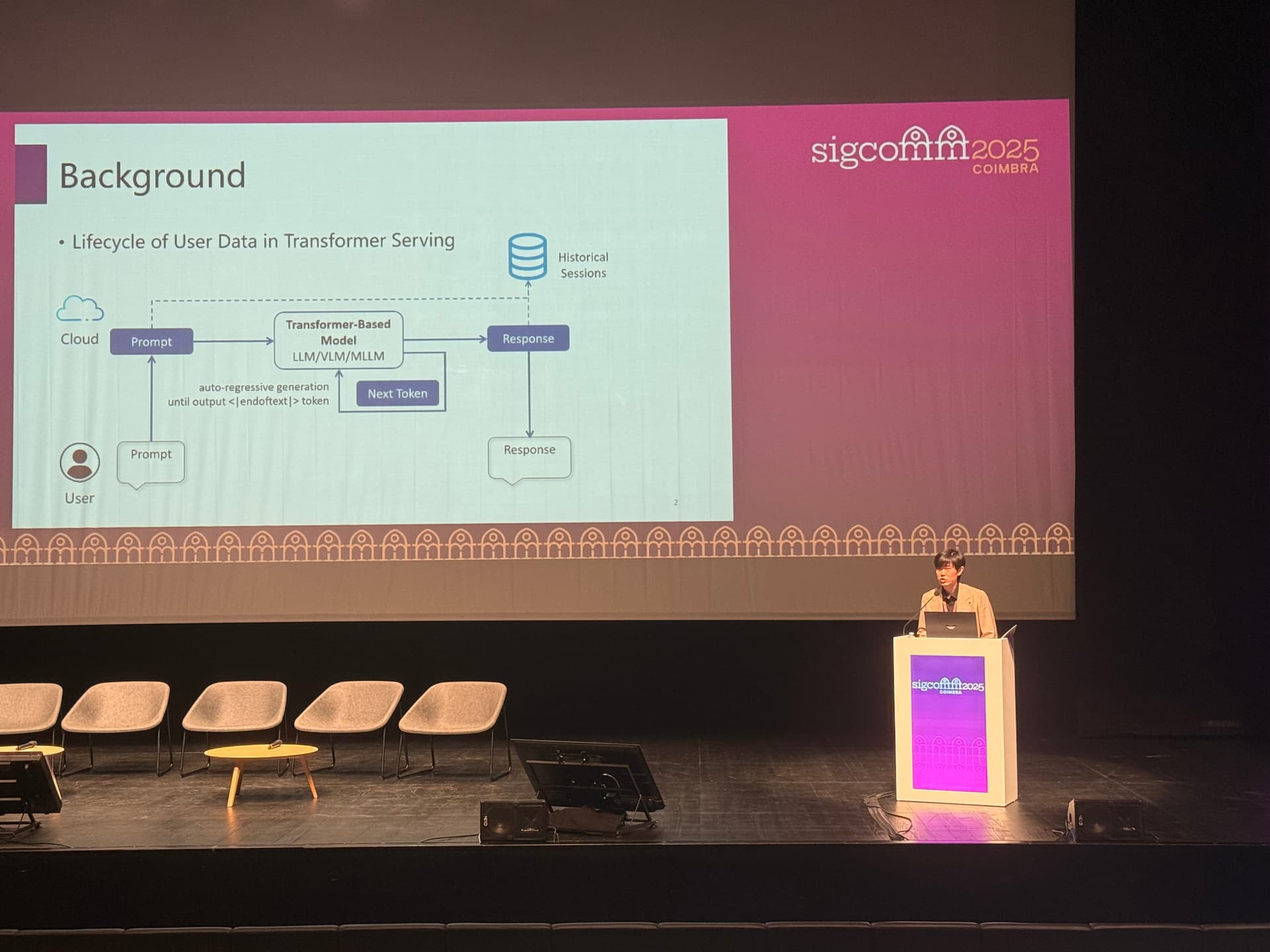
The paper addresses the challenge of providing confidential Transformer inference in the cloud. Transformer models are widely used in sensitive applications such as medical diagnostics and financial forecasting, but current plaintext-based services raise serious privacy concerns. Existing approaches—cryptography-based, memory isolation-based (TEE), and access control-based—fall short: cryptography introduces huge latency (e.g., hundreds of seconds), TEEs suffer from throughput bottlenecks, and access-control solutions require specialized hardware like NVIDIA H100 GPUs. Thus, a new solution is needed to achieve both privacy and efficiency in a hardware-agnostic manner.

Key idea and contribution
The authors propose SCX (Stateless KV-Cache Encoding), a novel framework for stateless KV-cache encoding. The core idea is that during Transformer inference, both the user input and the intermediate KV-cache are encoded with user-controlled keys, preventing the cloud from independently completing the next-step prediction or recovering the original input, thereby ensuring privacy.
The main design of SCX includes:
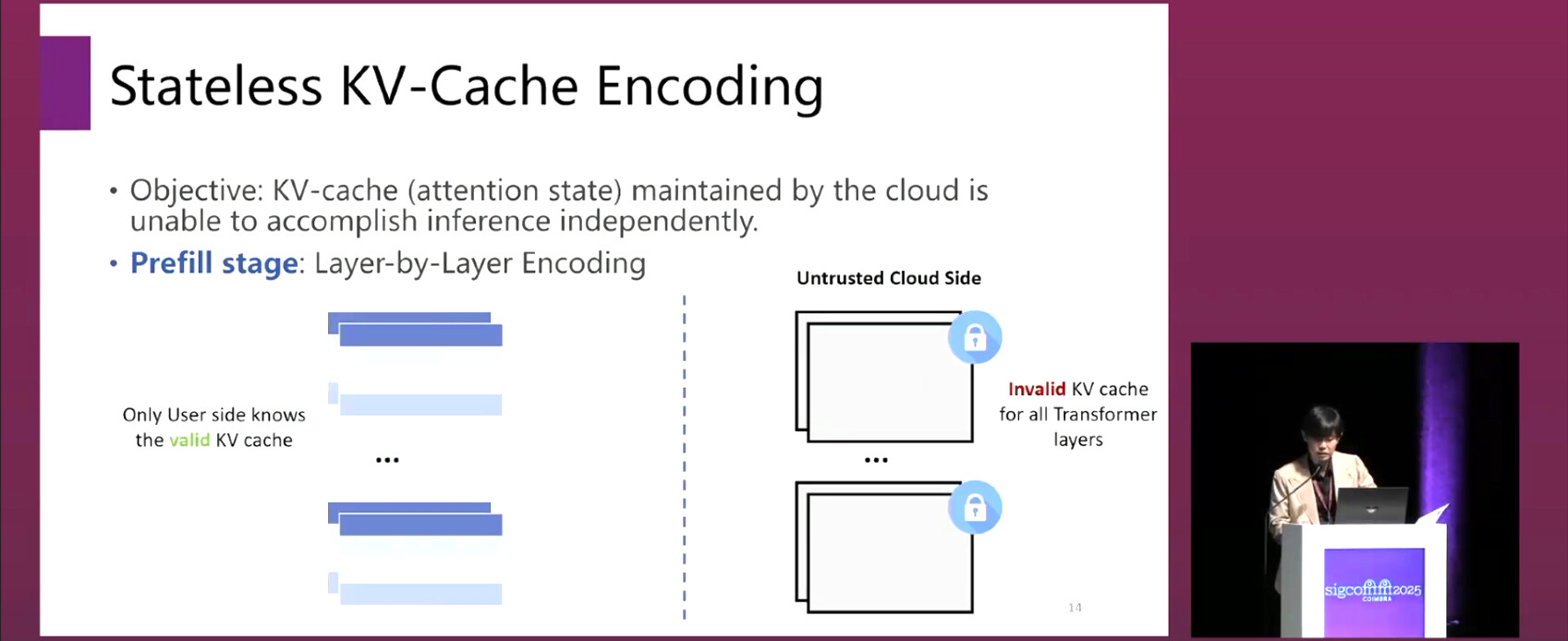
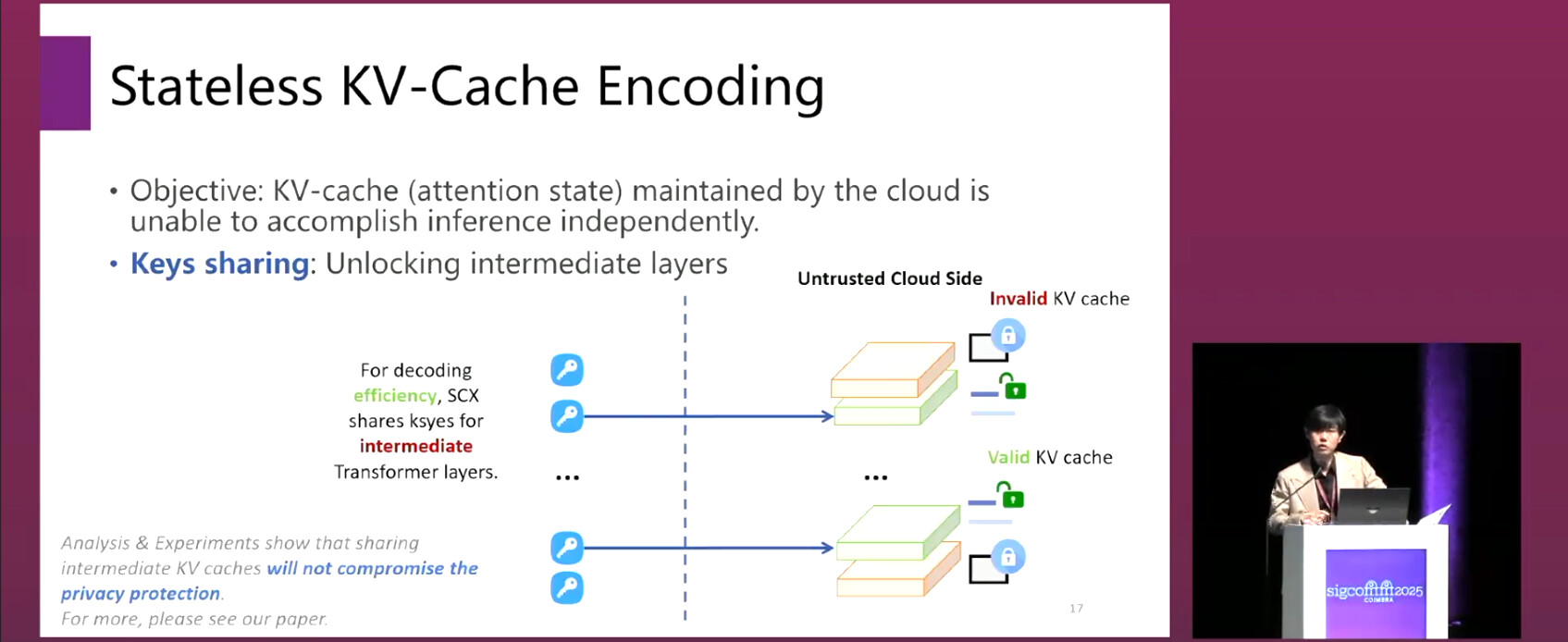
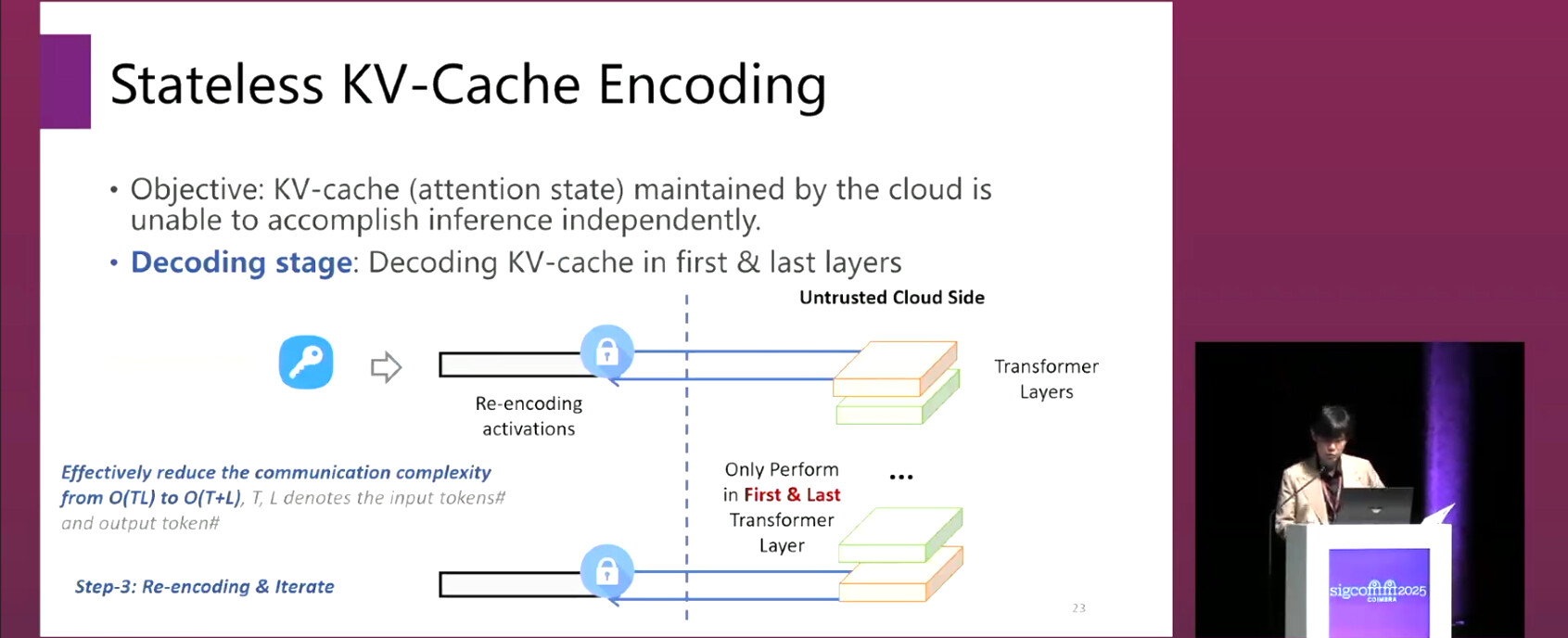
- Three-stage architecture: prefill, key sharing, and generation.
- In the prefill stage, SCX applies a combination of token permutation, redundant embeddings, and Laplace noise to defend against brute-force attacks, LLM-assisted recovery, and fitting-based inversion attacks.
- In the key sharing stage, only the keys for intermediate layers are uploaded, reducing communication complexity from O(T·L) to O(T+L).
- In the generation stage, the user only participates in decoding the KV-cache of the first and last layers, ensuring “statelessness.”
Theoretical guarantees: The authors prove that SCX-encoded inference is mathematically equivalent to plaintext inference (i.e., no accuracy loss), and they establish privacy bounds based on differential privacy.
Evaluation
Experiments on LLaMA-7B/13B/70B, Mixtral-8x7B, TinyLlama-1.1b-GPTQ, Qwen-7b-GPTQ show that SCX achieves near-plaintext performance with strong privacy:
-
Latency: For LLaMA-7B, SCX reduces prefill latency from 17s (TEE) or 200s (crypto) to 36ms.
-
Inference Output Quality: According to the accuracy and perplexity (PPL) of four Transformer models on the WikiText-2 dataset in both plaintext mode and SCX mode, the experimental results confirm our mathematical proof of equivalence: The PPL difference (Δ PPL) is zero, and the accuracy is 100%.
-
Privacy: Robust against brute-force, LLM-assisted recovery, and fitting-based inversion attacks.
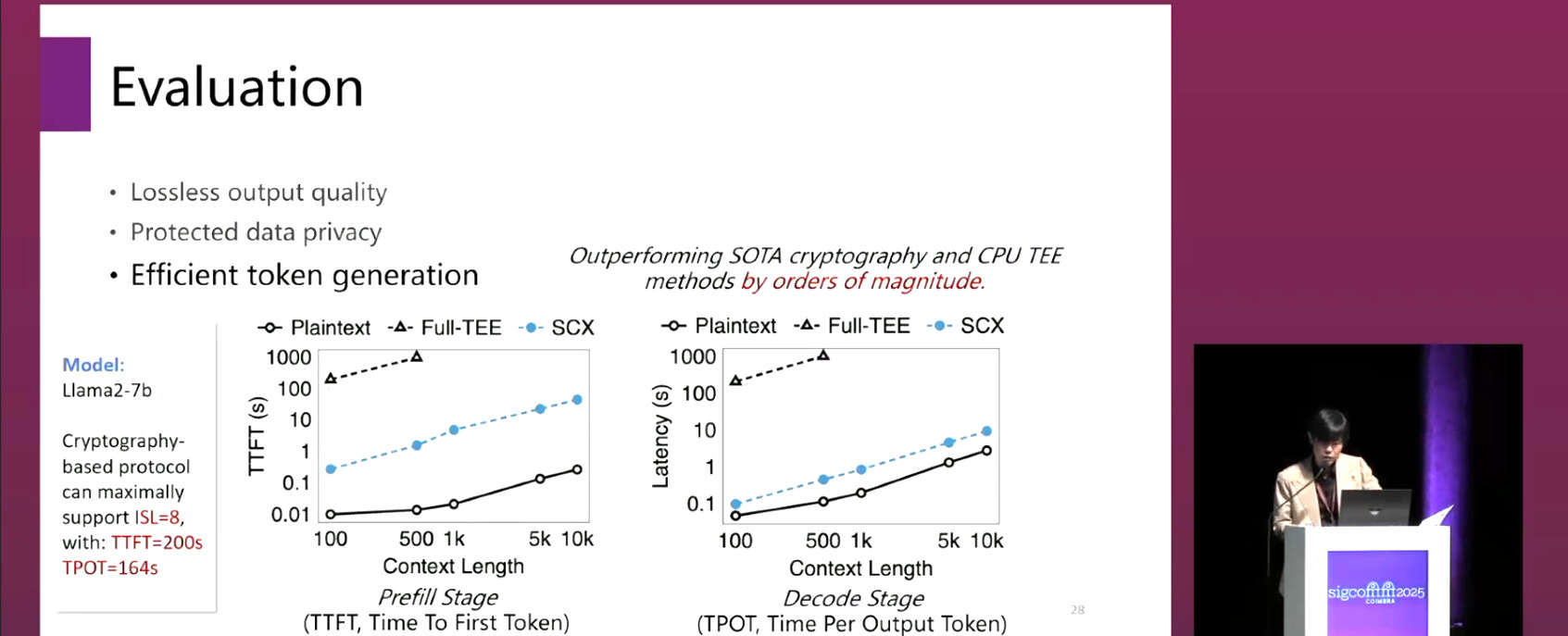
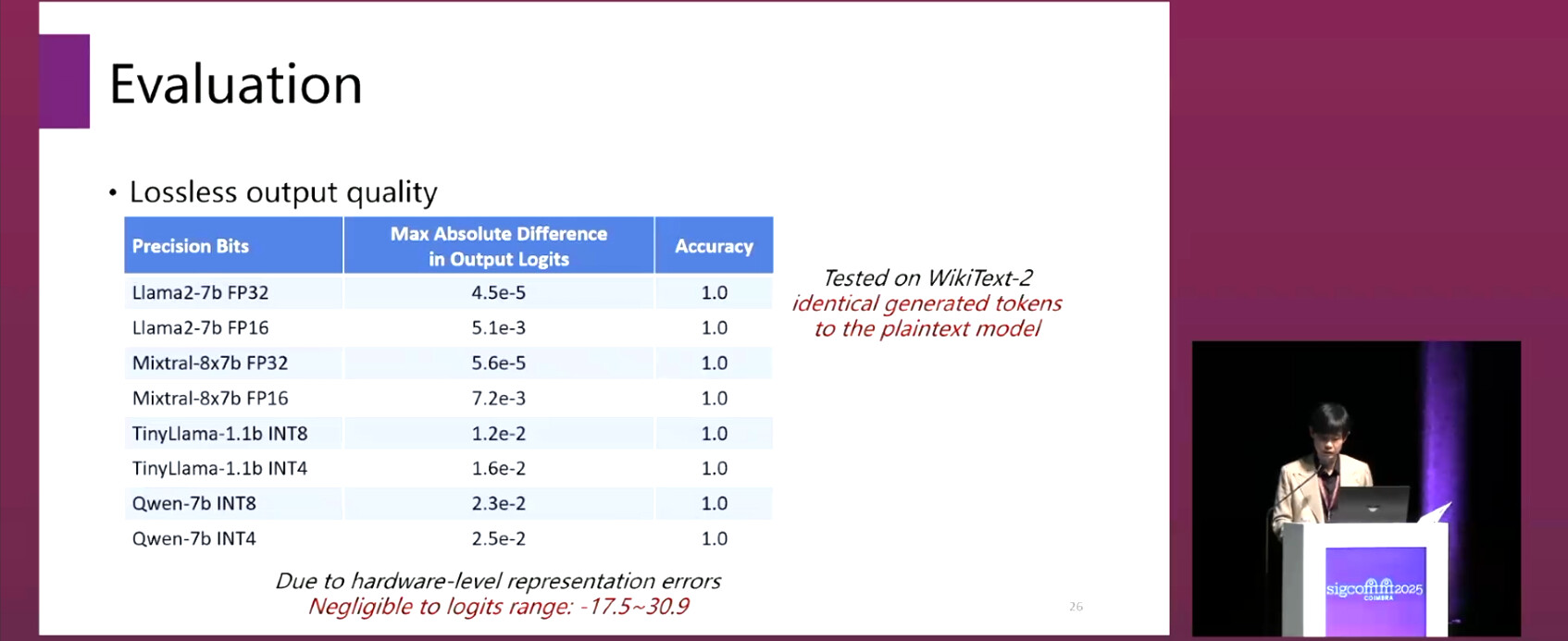
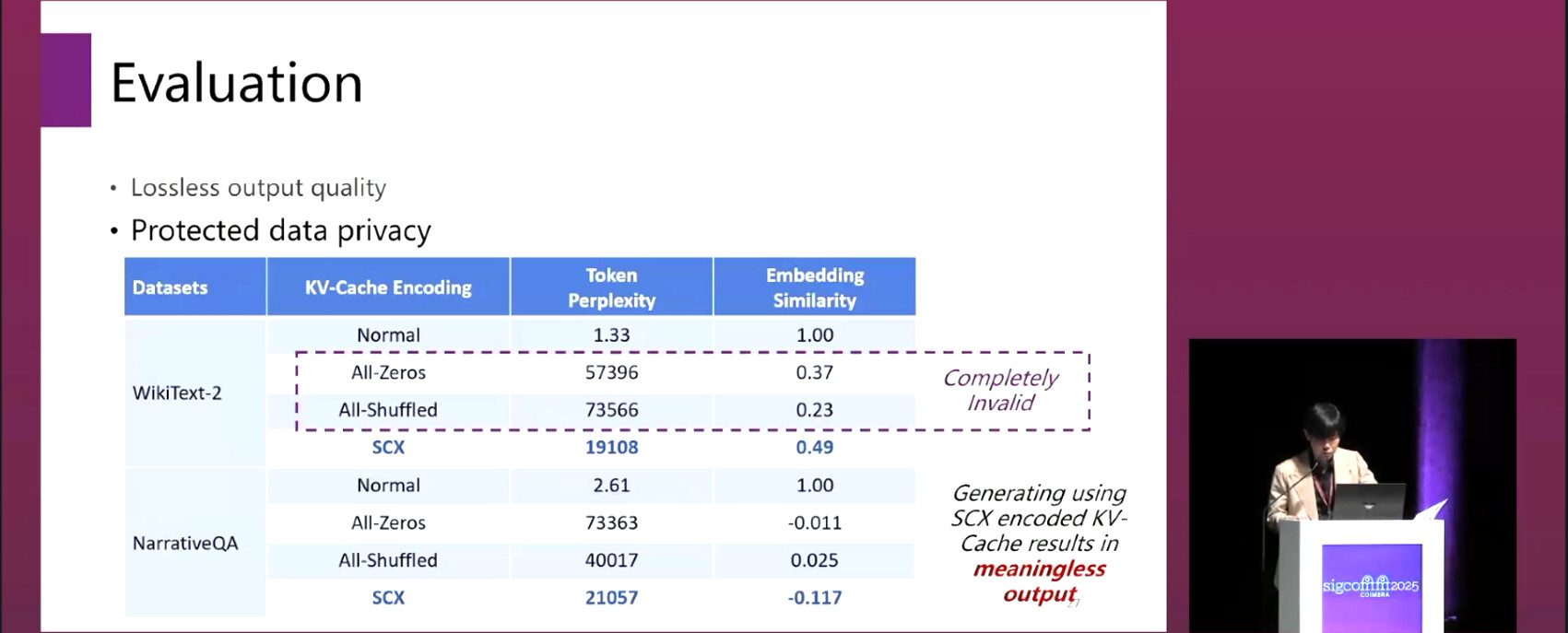
These results are significant because they demonstrate that efficient and practical confidential serving of large Transformer models is possible without specialized hardware or massive cryptographic overhead.
Q&A
Q1: Can SCX only run a regular transformer in a confidential Azure or any other confidential cloud platform?
A1: Nowadays, there is no commercial model that supports confidential serving. But the Apple company claims that they use private cloud computing techniques that are almost based on dedicated access control. It’s not a protocol-based but a hardware-based solution. Our system does not require any specific hardware or any software stack.
Q2: Could you share some intuition behind why performance is not dropping? The modern disease of the KV-cache is out of distribution. Its performance is not dropping, and it’s handling it correctly. Why can SCX just do this kind of end-to-end once encoding and give it to all the non-junk tokens?
A2: The performance Guarantee depends on our specific transformation design. The reason is that we do not accumulate the transformation errors; we just encode it and make the cloudside compute and then directly just decode and re-encode it. So the errors will not accumulate across different operators. We do it very frequently. So our performance is guaranteed, and it theoretically generates the equivalent output.
Personal thoughts
I think the paper’s idea of a “stateless kv-cache encoding” is quite elegant, as it cleverly leverages the two-stage nature of autoregressive inference by adopting different encoding strategies in the prefill and generation phases. It provides a new design space between pure cryptographic approaches and hardware-dependent solutions. However, further research is still needed for extremely long-context scenarios.