Title: SGLB: Scalable and Robust Global Load Balancing in Commodity AI Clusters
Speaker : Yu-Hsiang (Sean) Kao (ByteDance)
Scribe : Yuntao Zhao (Xiamen University)
Authors: Chenchen Qi (ByteDance); Wenfei Wu (Peking University); Yongcan Wang (ByteDance); Keqiang He (Shanghai Jiao Tong University); Yu-Hsiang (Sean) Kao (ByteDance); Zongying He (Broadcom); Chen-Yu Yen, Zhuo Jiang, Feng Luo (ByteDance); Surendra Anubolu (Broadcom); Yanjin Gao, Bingfeng Lin, Wenda Ni, Yiming Yang, Donglin Wei, Boyang Zhou, Jian Wang, Shan Ding (ByteDance)

Introduction
As Internet companies increasingly build large-scale AI clusters with commodity Ethernet switches for model training, network traffic characteristics such as low entropy and high burstiness pose stringent requirements: high peak bandwidth and robustness against failures. Existing load balancing solutions (e.g., ECMP, DLB, programmable-switch-based designs) fall short in such environments—either reacting too slowly to failures, ignoring global congestion, or being impractical for deployment in commodity hardware. To address this, the paper proposes SGLB (Scalable and Robust Global Load Balancing), which leverages the emerging Global Load Balancing (GLB) engine in modern Ethernet switches and a custom control-plane protocol, SyncMesh, to deliver congestion-aware and failure-resilient traffic distribution tailored for AI training workloads.
Key idea and contribution:
SGLB introduces three main innovations:
- Global Congestion-Aware Load Balancing: It utilizes the GLB engine to gather both local and remote congestion states, compute path quality in real time, and distribute traffic to less congested paths, achieving near-optimal load balancing.
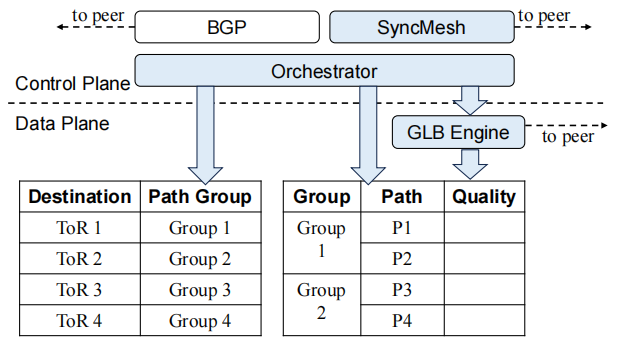
- Fast Link Failure Recovery with SyncMesh: By combining BGP with the newly designed SyncMesh protocol, SGLB achieves recovery from link failures within 45 µs, a dramatic improvement over BGP’s second-level convergence, thus ensuring long-term robustness.
- Scalable Path Quality Management and Asymmetry Handling: Through path segmentation, profile compression, and localized SyncMesh configuration, SGLB scales to data center–sized networks under limited hardware resources. Moreover, it introduces a scheme to handle bandwidth asymmetry caused by LAG failures, preventing throughput suppression on healthy paths.
Evaluation
The evaluation includes both testbed deployments and simulation studies:
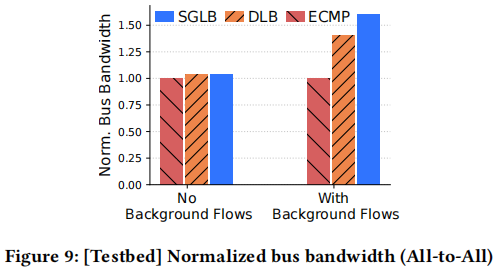
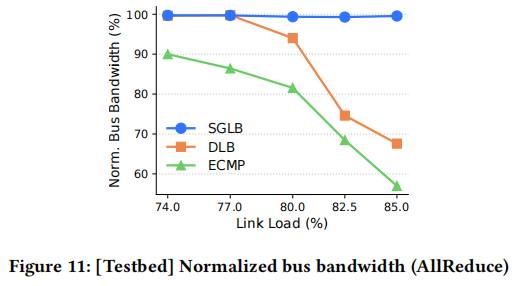
- Collective Communication: For NCCL benchmarks, SGLB accelerates All-to-All by up to 60% over ECMP and 15% over DLB, while sustaining higher bandwidth under heavy load in AllReduce.
- Failure Convergence: SGLB recovers in 1–45 µs depending on topology depth, over 20,000× faster than BGP-based schemes (>1 s).

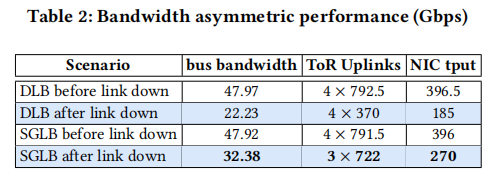
- Asymmetry Handling: In LAG failure experiments, SGLB maintains 32.38 Gbps throughput, compared to 22.23 Gbps for DLB, by proactively removing asymmetric paths.
- End-to-End Training: Training LLaMA-3 with 32 GPUs, SGLB reduces communication time per iteration from 1.177 s to 0.704 s, cutting total iteration time by 12.3%.
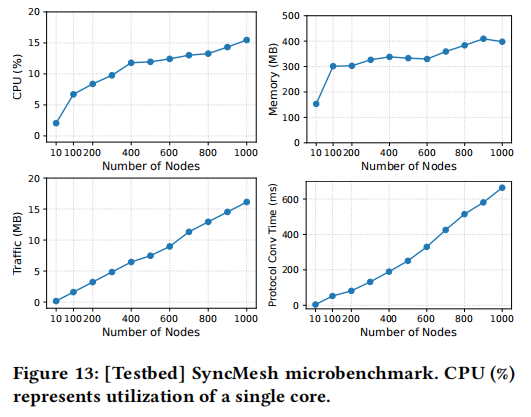
- Scalability: SyncMesh demonstrates low CPU/memory overhead and robust convergence even in simulated 1000-node clusters, highlighting its practicality.
Q1: You mentioned it takes fifty microseconds to learn that a path has failed and to stop using it. This implies that, even for load balancing, there’s still some delay before the information propagates. Since you use large collectives in your tests, what’s the threshold at which SGLB stops working well? In other words, what flow sizes are needed for it to work effectively, given that you need stable traffic patterns for the propagation to be useful?
A1: Right, so the trick we apply here removes that dimension: there’s a three-segment limitation in terms of how far the GLB messages propagate. The GLB messages are provided by the ASIC capability, so switches only communicate with their immediate neighbors. The GLB messages are never routed or forwarded beyond one hop. That means if we’re neighbors, I only send a GLB message to you. After you read it, you record it in your ASIC tables and then discard it. This guarantees that the latency is minimized—just two hops, and in many cases, they’re only microseconds apart. This also minimizes the impact on production network traffic.
Q2: Is it deployed in production?
A2: Almost in production.
Personal thoughts
The strength of SGLB lies in its end-to-end system-level design that bridges hardware features (GLB engines) with customized protocols (SyncMesh), delivering a deployable, production-ready solution for AI clusters. It convincingly addresses critical issues of failure recovery, congestion-aware routing, and path asymmetry, with substantial performance benefits in both micro-benchmarks and real training workloads.
That said, there are still several directions for further enhancement:
- The effectiveness of SGLB depends on GLB-capable switches, which may vary across hardware environments.
- The performance advantage is less pronounced at flowlet-level granularity, indicating opportunities for refining scheduling strategies.
- The current design primarily targets single-tenant AI clusters; extending it to address multi-tenant contention and fairness could broaden its applicability.
Overall, SGLB represents a solid contribution to data center networking for AI, showing that commodity hardware innovations can be systematically exploited to meet the extreme demands of distributed training. It sets a strong precedent for practical, scalable, and robust load balancing solutions in the AI era.