Title: SkeletonHunter: Diagnosing and Localizing Network Failures in Containerized Large Model Training
Authors: Wei Liu (Tsinghua University, Alibaba Cloud), Kun Qian (Alibaba Cloud), Zhenhua Li (Tsinghua University), Tianyin Xu (UIUC), Yunhao Liu (Tsinghua University), Weicheng Wang (Alibaba Cloud) Yun Zhang (Alibaba Cloud), Jiakang Li (Alibaba Cloud), Shuhong Zhu (Alibaba Cloud), Xue Li (Alibaba Cloud), Hongfei Xu (Alibaba Cloud), Fei Feng (Alibaba Cloud), Ennan Zhai (Alibaba Cloud)
Scribe: Mengrui Zhang (Xiamen University)

Introduction
This paper studies network failures in containerized large model training, a setting where containers, RDMA NICs, GPUs, and virtual network components interact at a massive scale. The problem is important because large model training is highly synchronous; even a small network delay can significantly slow down training or cause job failures. Existing data center monitoring tools fall short because containerized training clusters are highly dynamic, have complex endpoint bindings, and involve intertwined overlay and underlay networks. These factors multiply the difficulty of efficient and accurate connectivity monitoring.
Key Idea and Contribution
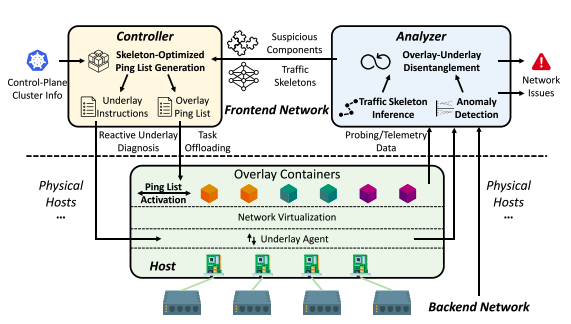
Figure 1: Architectural overview of SkeletonHunter.
The authors present SkeletonHunter, a monitoring and diagnosis system tailored for containerized large model training. Its key idea is to leverage the intrinsic sparsity in training traffic: only certain endpoints (the bound pair of a container and an RNIC) consistently communicate. Instead of probing all possible network paths, SkeletonHunter infers a traffic skeleton, the crucial set of active paths, and uses this to build an optimized probing matrix.
When a failure is detected, SkeletonHunter applies optimistic overlay-underlay disentanglement: it separately checks virtual (overlay) and physical (underlay) components under the assumption that their root causes do not propagate across layers. If it cannot find any problematic components at each layer, it also fine-checks the RNICs that connect.
As shown in Figure 1, SkeletonHunter follows the traditional Pingmesh architecture and consists of three major components, including the controller, the agent, and the analyzer, to realize the methodology. The controller is responsible for generating probing tasks and instructing the agents for each container to perform actual probing. The agents report the probing results (including end-to-end latency and packet loss rate) to the analyzer for failure detection and localization.
Contributions:
- Identifies unique challenges of diagnosing containerized training networks: high container dynamics, endpoint-induced complexity, and overlay–underlay interplay.
- Introduces SkeletonHunter, which infers sparse traffic skeletons and efficiently probes for failures.
- Deploys SkeletonHunter in production, showing it can detect and localize failures quickly and accurately .
Evaluation
Skeleton Hunter has been deployed in production at scale: monitoring over 5,700 hosts and 40,000 RNICs, analyzing more than 1 billion latency measurements daily. It successfully detected and localized over 4,000 network failures with 95% accuracy, reducing monthly failure rates by 99%.
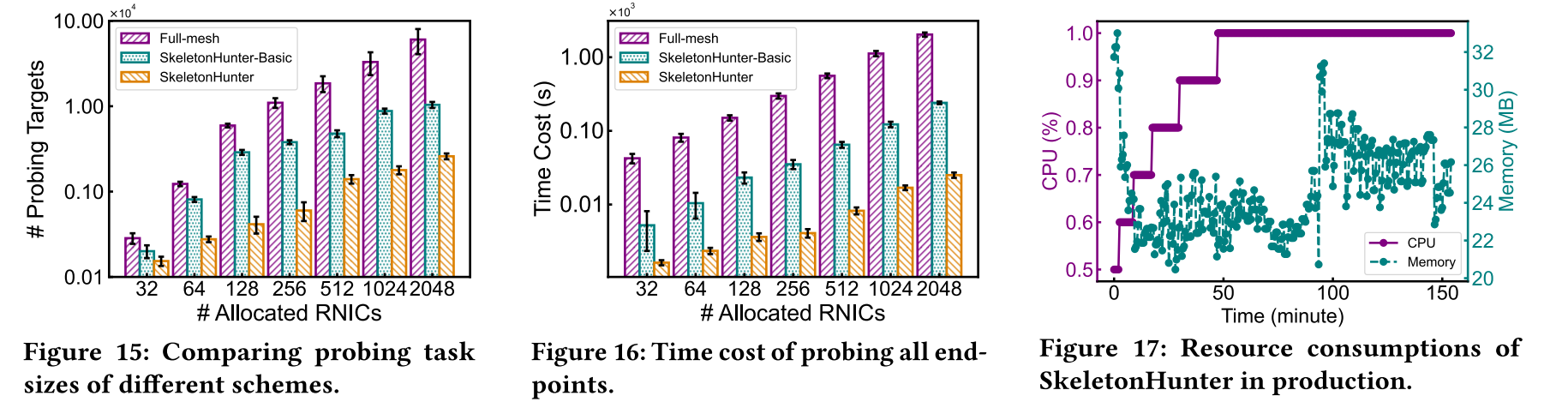
Evaluation results show that SkeletonHunter greatly reduces the probing matrix size by leveraging traffic skeletons; for instance, with 2,048 RNICs, it reduced probing targets from more than 60,000 to just about 2,600. It also cut probing time by up to nearly 90% compared with the basic ping list, while maintaining low overhead, with agents consuming less than 1% CPU and around 35 MB of memory. In terms of effectiveness, SkeletonHunter achieved 98.2% precision and 99.3% recall in detecting failures, uncovering 4,816 failures and accurately localizing 1,302 faulty components with 95.7% accuracy. Moreover, it identified 19 categories of failures across hardware and software layers, enabling rapid troubleshooting and improving the reliability of containerized large model training in production.
Q&A
Q1: What about gray failures or slow degradations caught by the long-term detection system?
A1: A frequent issue involves RNICs acting unpredictably, especially when offloaded flow tables become inconsistent with the control plane. This leads to degraded performance, making it one of the most problematic failures observed.
Q2: What about the 2% inaccuracy in detection/localization?
A2: Most inaccuracies come from agents crashing in production, which can cause false alarms when end-to-end connectivity appears to fail.
Q3: Is the system only applicable to large language models?
A3: No, the approach generalizes to other deep learning workloads, not just large LLMs.
Personal Thoughts
I like that SkeletonHunter leverages a deep insight, the regular sparsity of training traffic, and turns it into a practical monitoring strategy. The system is also pragmatic: it works without requiring visibility into user workloads or modifying their training code, which makes it deployable in real-world cloud environments.
On the downside, SkeletonHunter relies on assumptions about workload traffic patterns. As parallelism strategies evolve, traffic skeleton inference may become less accurate.