Title : SkyNet: Analyzing Alert Flooding from Severe Network Failures in Large Cloud Infrastructures
Authors : Bo Yang, Huanwu Hu, Yifan Li, Yunguang Li, Xiangyu Tang, Bingchuan Tian, Gongwei Wu, Jianfeng Xu, Xumiao Zhang, Feng Chen, Cheng Wang, Ennan Zhai, Yuhong Liao, Dennis Cai, Tao Lin (Alibaba Cloud)
Scribe : Xing Fang (Xiamen University)

Background
Modern hyperscale networks deploy numerous monitors to ensure service reliability. However, this often leads to alert storms when severe failures occur, overwhelming operators and delaying mitigation. Existing monitoring tools are fragmented and designed per data source, while rule-based or LLM-driven workflows are hard to scale to unseen or complex incidents. Without a unified structure to organize and interpret alerts, operators face high cognitive load and long recovery times, failing to meet strict SLAs.
Challenges and Key Insights
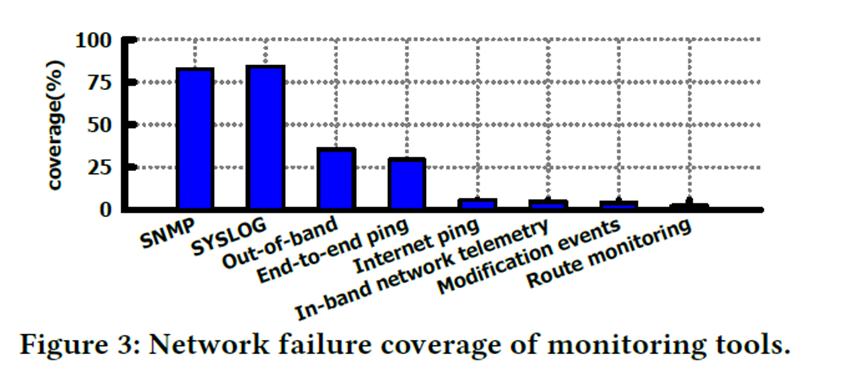
Multi-source alert heterogeneity hinders analysis unless structurally unified. Alerts originate from diverse tools such as Ping, SNMP, Syslog, and INT, each with different formats and semantics. Naïve merging amplifies noise and causes misclassification. SkyNet introduces a unified alert format by normalizing fields and aligning frequencies, enabling consistent interpretation and feeding clean input into downstream modules.
Critical signals are sparse and often buried under massive noise. In most severe incidents, only a handful of alerts are directly related to the root cause, yet they are flooded by secondary or irrelevant alerts. SkyNet addresses this by organizing alerts into temporal and spatial clusters, then building a hierarchical alert tree to aggregate and abstract them into high-level events, greatly improving focus and interpretability.
Parallel events lack clear prioritization, risking misordered mitigation. When multiple sites experience simultaneous issues, the number of alerts is not a reliable indicator of severity. SkyNet introduces a scoring model that integrates packet loss, link breaks, customer impact, and duration, producing a normalized risk score for each event. This guides mitigation scheduling by severity and prevents wasted efforts on lower-impact incidents.
LLM-based methods lack controllability and stability in critical settings. Although LLMs have shown promise in parsing logs and aiding diagnosis, the authors argue that they suffer from context window limitations, hallucinations, and unverifiable reasoning paths. SkyNet instead adopts explainable logic chains and rule-based reasoning to ensure robustness and auditability, which is crucial for reliable production use.
Implementation
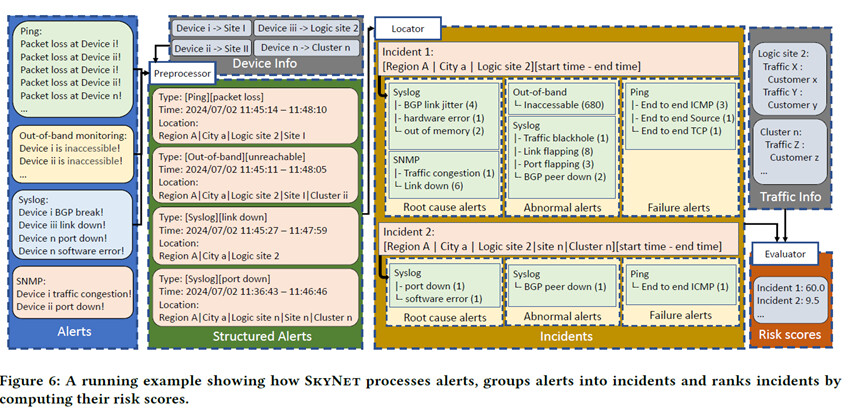
SkyNet follows a modular design with three core components: Preprocessor, Localizer, and Evaluator. The system revolves around structured alerts as the unified intermediate representation. Each module operates independently but coherently via standardized interfaces, supporting both parallel development and future extensibility.
The preprocessor handles alert structuring, deduplication, and aggregation. By applying template-based parsing and pattern matching, it converts raw alerts into canonical types. Repeated or sustained alerts (e.g., frequent SNMP threshold breaches) are merged. Each structured alert includes temporal and spatial scopes, reducing alert volume while retaining essential context.
The localizer organizes structured alerts into events using hierarchical network topology. It builds an alert tree where nodes correspond to network objects (e.g., clusters or sites). Alerts are aligned within five-minute windows and grouped based on topology proximity. The system can also split disjoint propagation paths into separate events, improving clustering precision and root cause attribution.
The evaluator assigns risk scores and prioritizes events based on business impact. The authors propose a composite scoring function incorporating factors such as link breakage, SLA traffic anomalies, critical customer exposure, and duration. A sigmoid function is used to smooth upper bounds and reduce score volatility. The output includes ranked events and zoom-in views for rapid diagnosis.
Evaluation
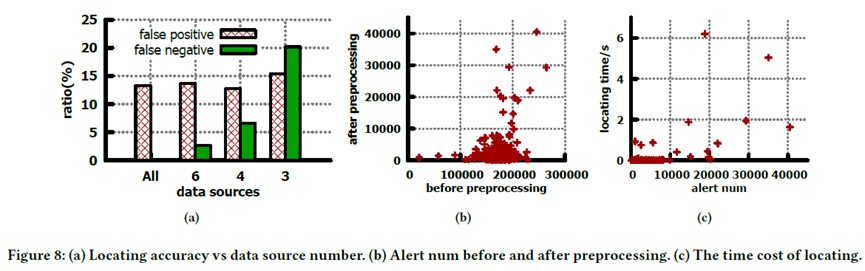
SkyNet has been deployed in Alibaba’s global network infrastructure and has aided the mitigation of dozens of severe incidents over the past 18 months. The system reduced average mitigation time from hours to minutes and successfully enabled automated isolation and prioritization in many cases, contributing to higher SLA adherence.
The authors present several representative use cases, including identifying concurrent DDoS attacks across sites, isolating cascading loss events from link failures, and correlating ingress failures with global reachability matrices. SkyNet demonstrated both accuracy and efficiency in narrowing down the affected area, outperforming manual tracing methods in complex forwarding environments.
The system also shows good extensibility. Its architecture supports plug-and-play data source integration and has already incorporated new monitoring signals such as PTP delay alerts, configuration change events, and remote gRPC statistics. The authors illustrate how these signals are structured and scored, demonstrating the system’s adaptability and evolution potential.
Q&A
Q1: Early in your talk, you mentioned an interesting problem: the true root-cause alerts often appear after other alerts. Later in the presentation, I didn’t see how this issue was addressed. Could you elaborate?
A1: That’s a very good question. SkyNet does not attempt to classify or differentiate the specific types of incidents. Instead, it focuses on overall patterns, serving as a safety net to catch critical issues. For predefined incidents that require precise root-cause handling, another system in the team covers those cases. SkyNet itself is designed to provide bottom-line protection rather than fine-grained classification.
Q2: You mentioned that an LLM-based solution could also be useful in similar scenarios. Could you explain a bit more?
A2:Our group has another paper that explores an LLM-based approach. SkyNet, in contrast, is a more deterministic system. We are working on both directions in parallel but do not plan to merge them at this stage. Our current priority is to provide a trustworthy, deterministic solution, while the LLM-based approach remains a complementary line of exploration.
Personal Thoughts
I find SkyNet to be a practical and well-engineered system that effectively extracts key error categories from massive alert volumes via aggregation, classification, and prioritization. The resulting structured events significantly improve both manual debugging and LLM-assisted analysis. In particular, SkyNet’s outputs could serve as valuable input to other systems such as BiAn, which was also published at SIGCOMM’25, potentially enhancing their inference accuracy and efficiency. While SkyNet has not yet achieved fully end-to-end fault analysis—its output still requires human interpretation—the remaining “last mile” could plausibly be addressed through techniques like chain-of-thought reasoning powered by LLMs, ultimately leading to more complete and precise localization.