Title: The Sweet Danger of Sugar: Debunking Representation Learning for Encrypted Traffic Classification
Authors: Yuqi Zhao, Giovanni Dettori, Matteo Boffa, Luca Vassio, Marco Mellia (Politecnico di Torino)

Introduction
The paper addresses the challenge of classifying encrypted network traffic—a task made difficult because traditional deep packet inspection fails under encryption. Existing studies report high accuracy (up to 98%) by applying representation learning models inspired by NLP (e.g., BERT), suggesting these models extract meaningful patterns even from encrypted payloads. However, this paper argues that such results are misleading: inflated by dataset preparation flaws, spurious correlations, and shortcut learning. The importance of this problem lies in both security and networking efficiency, making it vital to assess whether representation learning can genuinely solve traffic classification or if prior work is over-promising.
Key idea and contribution:
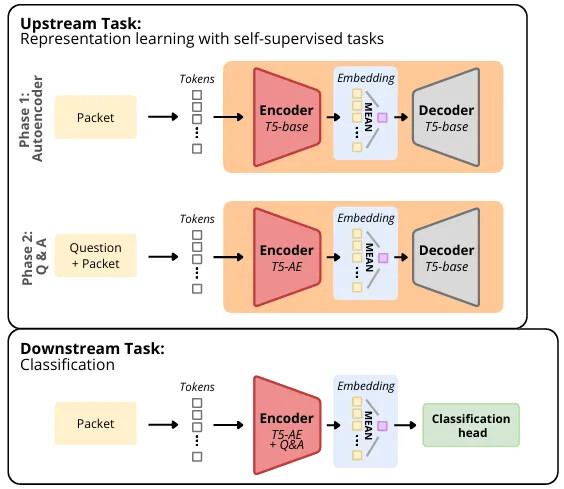
The authors critically reassess prior claims by re-evaluating state-of-the-art models (ET-BERT, TrafficFormer, NetMamba, YaTC, netFound) under stricter, more realistic experimental conditions. They uncover that much of the reported high accuracy stems from data leakage and shortcut learning, particularly due to per-packet splitting that allows test and train sets to share information from the same flow. To address these pitfalls, the authors propose Pcap-Encoder, a T5-based representation learning model specifically designed to focus on protocol headers rather than encrypted payloads. Unlike previous approaches, Pcap-Encoder uses self-supervised pretraining with reconstruction and Q&A tasks tailored to networking semantics, thereby extracting meaningful features from headers.
Evaluation
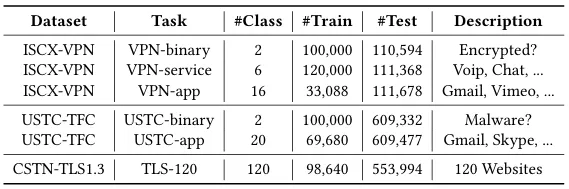
The evaluation spans multiple datasets and tasks, comparing state-of-the-art methods against Pcap-Encoder and shallow baselines. Results show that when tested under correct per-flow splits with frozen encoders, most existing models collapse to poor performance (<40% accuracy in complex tasks), revealing that their earlier success was artificial. Pcap-Encoder stands out as the only model providing stable and semantically meaningful representations, though its performance still struggles on highly complex tasks like TLS-120. Strikingly, even simple shallow baselines outperform complex representation learning models in some cases.
Q1: What’s the size of your model?
A1: About 800GB for the pretraining model.
Q2: The random forest algorithm you compared uses labeled data for supervised learning, so can your model learn by itself?
A2: Yes, we use supervised learning model for random forest algorithm, but the comparison is only done on downstream task, so the labeled data is used.
Q3: Can you explain a little bit more about the Q&A model you used?
A3: We used T5-based architecture for our Q&A model. For beginning of the input, like in network, the question is what’s the ttl and network capacity, and the model outputs the answer.
Personal thoughts
This paper is a valuable reality check for the networking and AI communities. The authors’ insistence on frozen encoders for fair evaluation is especially insightful, as it exposes whether pretraining truly yields useful representations. On the downside, while Pcap-Encoder offers meaningful insights, its high complexity and resource demands limit its practicality, especially when simpler baselines perform competitively.
Looking forward, open questions remain: Can we design efficient yet domain-aware representation learning approaches that outperform shallow baselines without relying on spurious correlations? Is there potential in hybrid approaches that combine domain knowledge with self-supervised learning? Additionally, extending the evaluation methodology to broader networking tasks (e.g., intrusion detection, QoE estimation) could further test the limits of representation learning in encrypted environments.