Title : Towards LLM-Based Failure Localization in Production-Scale Networks
Authors : Chenxu Wang (Nanjing University and Alibaba Cloud); Xumiao Zhang (Alibaba Cloud); Runwei Lu (New York University Shanghai and Alibaba Cloud); Xianshang Lin, Xuan Zeng, Xinlei Zhang, Zhe An, Gongwei Wu, Jiaqi Gao (Alibaba Cloud); Chen Tian, Guihai Chen (Nanjing University); Guyue Liu (Peking University); Yuhong Liao, Tao Lin, Dennis Cai, Ennan Zhai (Alibaba Cloud)
Scribe : Xing Fang (Xiamen University)

Background
The paper focuses on one of the most challenging aspects of production networks—failure localization and root cause analysis. Although existing monitoring systems are highly automated, major incidents inevitably generate a flood of alerts that often exceed human operators’ processing capacity. Traditional rule-based or heuristic approaches struggle to generalize to unseen failure patterns, while simple statistical methods lack interpretability and accuracy. The authors observed that LLMs have strong potential in understanding and reasoning over complex textual data, and thus proposed BiAn to significantly enhance the efficiency and reliability of incident investigation in production environments.
Challenges and Key Insights
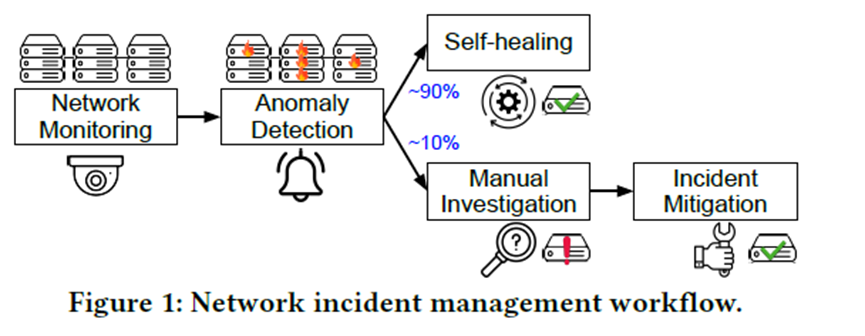
The paper illustrates the workflow of network failure diagnosis and identifies several key challenges.
First, the scale and heterogeneity of monitoring data pose a fundamental challenge. A single incident can trigger gigabytes of logs from diverse monitoring sources, often containing redundancy and noise. Human operators find it difficult to extract relevant information under time constraints, and LLMs may also be distracted by irrelevant data. BiAn addresses this by applying a hierarchical summarization and device-level analysis to gradually compress the data.
Second, the complexity of device and event relationships increases reasoning difficulty. Failures may propagate across the network topology, causing secondary alerts, and temporal order can also affect causal inference. Relying on single-device analysis alone can be misleading. BiAn introduces topology and timeline information as additional inputs, enabling more comprehensive reasoning to identify the true faulty device.
Third, fast response is a hard requirement in production environments. Network operations are bound by strict SLAs, and prolonged localization may incur millions of dollars in losses. BiAn’s key insight is to leverage lightweight model fine-tuning, early stopping, and parallel multi-agent execution to avoid unnecessary computation and keep latency within minutes.
Fourth, network evolution demands system adaptability. As devices, protocols, and operational workflows change frequently, static models quickly become outdated. BiAn addresses this with a continuous prompt updating mechanism, which extracts and consolidates knowledge from historical cases to enhance reasoning performance over time.
Finally, explainability and consistency are prerequisites for deployment. If outputs are random or lack reasoning, operators cannot trust the system in critical scenarios. BiAn mitigates this by applying the Rank of Ranks mechanism to reduce randomness and by producing explanations grounded in standard operating procedures (SOPs), so that human operators can quickly verify its conclusions.
Implementation
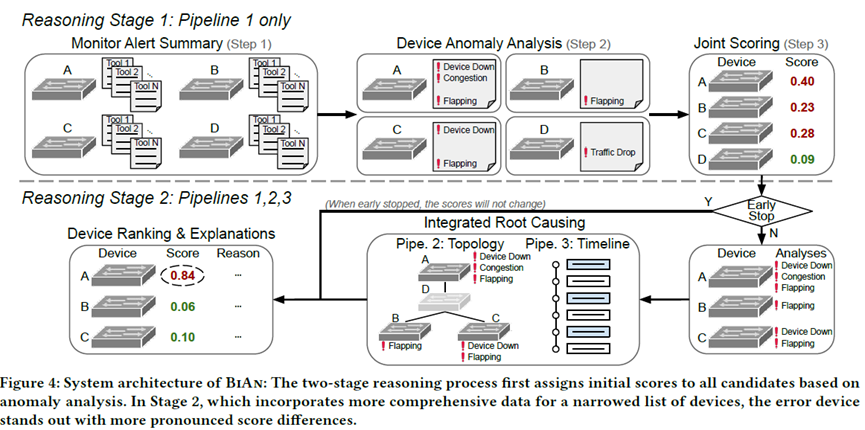
The paper presents the architecture of BiAn, which consists of several functional modules.
First, a hierarchical reasoning framework effectively controls complexity. BiAn employs multi-level LLM agents: monitoring alerts are first summarized into structured reports, then device-level anomaly analysis is performed, and finally candidate devices are scored and ranked. This “coarse-to-fine” design significantly reduces input size, keeping LLM inference within feasible bounds.
Second, multi-input integration enhances localization accuracy. In the second stage, BiAn incorporates both topology and timeline information into reasoning, making it easier to distinguish root-cause devices from those merely affected. For example, anomalies on a parent node may cause alerts on child nodes, but topology reasoning can reveal the true source, while timeline ordering helps rule out secondary effects.
Third, continuous prompt updating ensures long-term adaptability. BiAn leverages LLMs’ own generation and reflection capabilities to perform multiple reasoning attempts on historical cases, compare correct versus incorrect paths, and distill key knowledge. This knowledge is then merged into future prompts. The design avoids expensive parameter training while allowing the system to steadily improve its reasoning stability.
Finally, engineering optimizations guarantee practical usability. The authors fine-tuned smaller models for specific tasks, lowering computational overhead while improving accuracy. Early stopping allows BiAn to halt further reasoning when results are already highly confident, and parallel execution further reduces latency. Together, these optimizations enabled BiAn to sustain performance during ten months of real-world deployment.
Evaluation
First, real-world deployment verified the practicality of BiAn. In ten months of operation across Alibaba Cloud’s global network, BiAn reduced time-to-root-causing (TTR) by an average of 20.5%, and by up to 55.2% in high-risk cases—demonstrating particular advantages in complex scenarios.
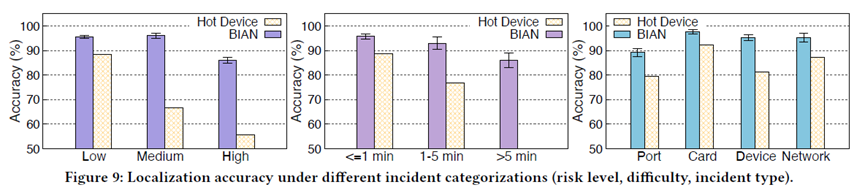
Second, both accuracy and explainability improved. Based on 17 months of real incident cases, offline experiments show BiAn improved localization accuracy by 9.2% compared with the baseline (as shown in the paper’s figures). Operator surveys also reported that its explanations were generally “helpful”; even when the top-1 prediction was incorrect, the explanations provided useful context for human analysis.
Third, case studies highlighted BiAn’s value in difficult scenarios. In incidents where multiple devices simultaneously showed anomalies, manual investigation could take 20 minutes, while BiAn localized the true faulty device within seconds by leveraging topology and timeline reasoning.
Finally, ablation studies and operational insights confirmed the soundness of the design. Experiments demonstrated the critical roles of multi-pipeline reasoning and the Rank of Ranks mechanism in improving accuracy, while continuous prompt updates contributed to ongoing gains. The authors also shared operational experiences such as data retention limitations and operator onboarding, offering valuable lessons for future research.
Q&A
Q1: In joint scoring, since individual device evidence may be insufficient, do you rely on manually set thresholds or let the language model infer suitable values? Do these thresholds vary across different cases?
A1: The system does not fully rely on the language model to directly produce a diagnosis. Instead, it combines device evidence with model output in a real decision-making process, and plans to involve more human-operator input in the future to build an interactive human–AI workflow…
Q2: Have you observed cases of hallucinations, where the model gives random or clearly incorrect explanations?
A2: Yes, random outputs have occurred, but this is treated as part of a trust-building process. The system is positioned as an assistant rather than a fully automated decision maker. Operators can review the reasoning, apply critical thinking, and choose to accept or reject the model’s results.
Q1: If the same type of incident repeats several times, can the system improve its accuracy over time—perhaps using reinforcement learning or similar mechanisms?
A3: We have evaluated repeated error patterns and analyzed the trade-offs between accuracy, learning bias, and time cost. Details are discussed in a subsection of the paper. Currently, the mechanism relies mainly on feedback loops rather than strict reinforcement learning.
Personal Thoughts
Overall, BiAn represents a meaningful advance in applying LLMs to network operations. It effectively tackles scale, latency, and explainability, and its deployment results are convincing. Unlike prior systems that only provide coarse summaries, BiAn directly assists operators in pinpointing faulty devices, which is a substantial step forward.
That said, I remain cautious about certain design choices. In particular, BiAn relies heavily on LLMs for log aggregation and filtering—tasks that may be more efficiently and reliably handled with rule-based or template mechanisms, as demonstrated in SkyNet. Using LLMs here introduces computational overhead and the risk of hallucinations, which could mislead operators if explanations are inaccurate. Furthermore, while SkyNet achieves effective event aggregation without timeline reasoning, BiAn emphasizes temporal order as essential. This discrepancy raises interesting questions: is it due to methodological differences, or inherent to the problem setting? Exploring the gap between heuristic approaches and LLM-based reasoning for causal analysis could provide deeper insight into the boundaries and complementarities of the two paradigms.