Title: TraceWeaver: Distributed Request Tracing for Microservices Without Application Modification
Authors: Sachin Ashok, Vipul Harsh, P. Brighten Godfrey (University of Illinois Urbana-Champaign), Radhika Mittal (University of Illinois Urbana-Champaign), Srinivasan Parathasarathy (IBM Research), Larisa Schwartz (IBM Research)
Scribe: Mingyuan Song (Xiamen University)
Introduction
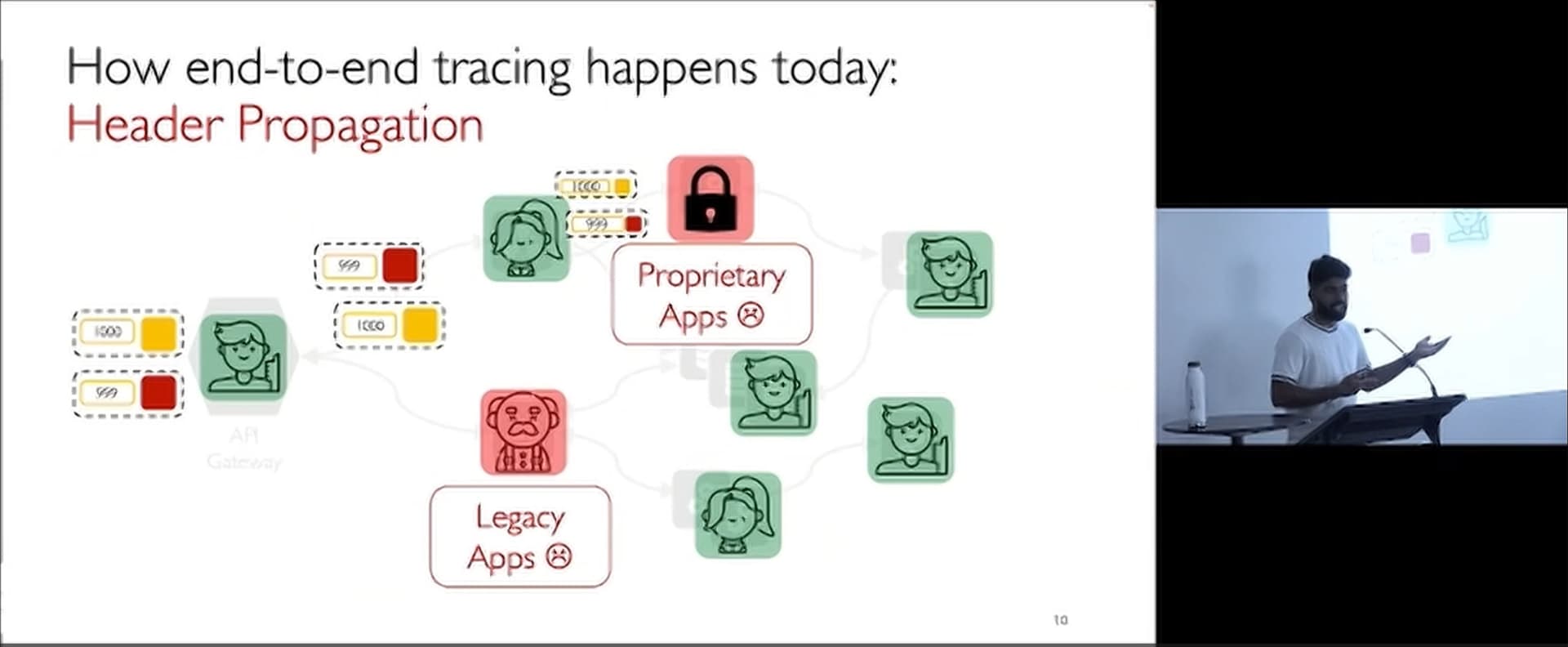
TraceWeaver addresses the significant challenge of monitoring and debugging highly distributed microservice architectures without requiring application instrumentation. Modern microservice applications can involve hundreds or even thousands of service instances, making it complex to trace requests across the entire system. Traditional tracing solutions like Jaeger and Zipkin require significant code modifications to propagate tracing information, which is a substantial barrier to adoption, especially for legacy systems. TraceWeaver aims to provide a non-intrusive solution by leveraging available span metadata and call graphs to reconstruct request traces with high accuracy.
Key Idea and Contribution
The authors developed TraceWeaver, a system that reconstructs request traces by utilizing readily available information such as timestamps and call graphs from test environments. The core innovation of TraceWeaver is its reconstruction algorithm, which uses a combination of constraint satisfaction and statistical timing analysis to effectively map incoming requests to their corresponding outgoing requests.
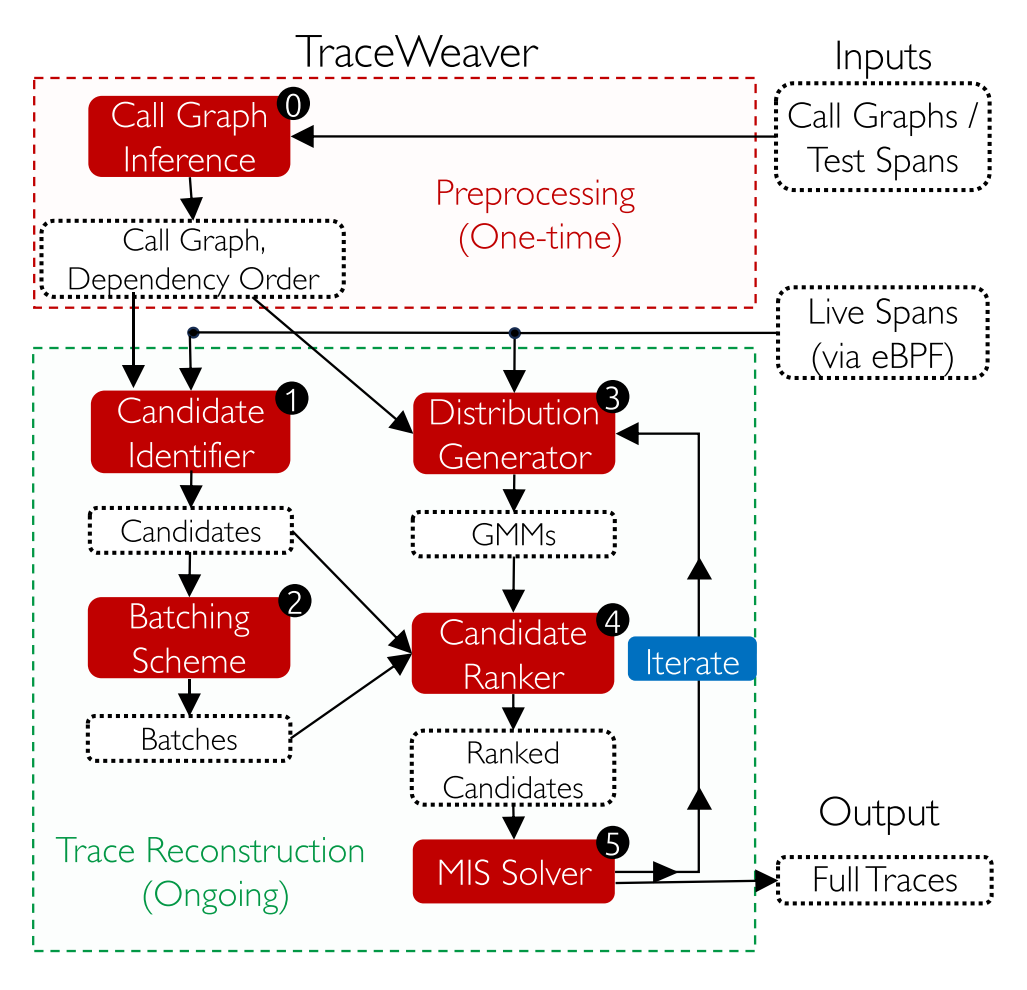
The design of TraceWeaver involves several key components:
- Span Metadata Collection: TraceWeaver captures span metadata (such as timestamps, request types, and endpoints) using non-intrusive tools like eBPF hooks and service mesh sidecars. This information provides the foundation for identifying potential mappings between incoming and outgoing requests.
- Call Graph Inference: By running the application in a controlled test environment, TraceWeaver constructs detailed call graphs that describe the sequence of backend services each request interacts with. This step helps in understanding the typical request flow and dependencies between services.
- Candidate Identification and Pruning: For each incoming request, TraceWeaver generates a list of candidate outgoing requests based on span metadata and call graph constraints. It prunes the search space by eliminating candidates that do not satisfy timing or dependency constraints.
- Scoring and Ranking Candidates: TraceWeaver assigns scores to the remaining candidate mappings using statistical timing analysis. It estimates the probability distribution of delays between parent and child spans and uses these distributions to rank the candidates.
- Iterative Joint Optimization: The system iteratively refines the mappings and timing distributions. It starts with an initial guess of the timing distribution, applies constraints to identify feasible mappings, and then uses these mappings to update the timing distribution. This process is repeated until the mappings converge to a high-accuracy solution.
- Constraint Solver: TraceWeaver formulates the mapping problem as a maximum independent set problem in a graph, where vertices represent candidate mappings and edges represent constraints. The goal is to find the highest-scoring set of mappings that satisfy all constraints simultaneously.
- Handling Call Graph Dynamism: To accommodate dynamic changes in the call graph (e.g., due to caching or failures), TraceWeaver introduces a level of fuzziness in its algorithm. It allows for partial adherence to the call graph constraints, ensuring robustness in varying runtime conditions.
Evaluation

TraceWeaver’s efficacy was demonstrated using the DeathStarBench benchmarking suite and a production dataset from Alibaba. The system achieved an accuracy of 93% in benchmark tests and 80-99% in real-world scenarios under varying loads. This is significant because it showcases that non-intrusive tracing can be highly effective for performance debugging and A/B testing, offering a practical alternative to traditional methods that require extensive code modifications.
Q: Why is header propagation considered to require substantial modifications to applications?
A: While the RPC library can add headers, the application still needs to propagate these headers to backend requests. This requires tight coupling with specific technologies, which hasn’t seen widespread adoption.
Personal Thoughts
TraceWeaver presents a compelling solution to a prevalent problem in microservice monitoring. Its non-intrusive approach is particularly advantageous for legacy systems or environments where modifying application code is impractical. The iterative refinement of mappings and timing distributions is a robust method for achieving high accuracy without context propagation. However, the system’s dependence on accurate call graphs and span metadata from test environments might pose challenges in highly dynamic systems. Future work could explore enhancing the accuracy by incorporating more nuanced information, such as content-based similarities between requests. Overall, TraceWeaver is a significant step forward in distributed request tracing, offering a practical tool for developers and operators to gain insights into their microservice architectures without the overhead of traditional tracing solutions.